This is Part 5 of a 6-part series that demonstrates how to take a monolithic Java application and gradually modernize both the application and its data using Azure tools and services. This article explores ways to improve data scalability.
The PetClinic application relies on a relational database to ensure that it captures which pets the clinic has treated and to detail the relationships among pets, owners, and veterinarians. A PostgreSQL database is robust, but as the clinic grows, the database must scale to support that growth. Although we could run the database on a bigger machine, there are limits on how many tasks a single machine can run in parallel.
Relational databases struggle when tables contain many rows but each transaction only needs a few of them. For example, the “visits” table might have a history of 100,000 visits, but an employee might only need to view a dozen of them to schedule a visit next month. Additionally, it’s not necessary to search through visits with 100 veterinarians when only six of them work at the relevant location.
Fortunately, there’s a way to partition the data that clears the clutter while preserving data availability. This process is called sharding. As discussed in Microsoft’s article on the Sharding Pattern, sharding seeks to divide the data into smaller collections and keep each collection on a node — a separate instance of the database. This reduces the data that the node must encounter to find what it needs.
Additionally, dedicating a single node to the data ensures that resources are available to run tasks. When the load is light, one physical machine might run many nodes. But as the daily transaction volume grows and requires scaling, the nodes can move onto separate machines.
In transactional applications like PetClinic, developers often shard data based on how they query it. In a pet clinic, most daily operations involve scheduling visits or reviewing schedules. These tasks generally center upon the visit data. If we decide to shard the clinic data because of its size and volatility, we require a stable, unique value consistent across all visits.
For example, we assign a unique value to each veterinarian when they join the clinic. The values sets for all veterinarians are unaffected, so this key is stable. Additionally, all visits link to a veterinarian, so we can divide the entire set of visits into smaller blocks using each veterinarian’s unique ID.
Citus extends PostgreSQL into a distributed database. Microsoft’s implementation of this is Azure Database for PostgreSQL — Hyperscale (Citus). Hyperscale (Citus) enables us to build world-class relational databases — such as that for PetClinic — by distributing the data across several nodes. We can locate the nodes in the regions closest to the offices. Therefore, a veterinarian’s data is in the same region as the office, eliminating network latency and maintaining data availability for reports or analyses.
Globally expanding the pet clinic becomes a straightforward advancement from the Azure Database for PostgreSQL. It’s merely PostgreSQL, distributed. This also provides the performance of NoSQL databases while avoiding the effort of redesigning the data and application to run on a database like Cosmos DB or Cassandra.
While Citus is quite powerful, it requires at least three machines. Scaling this way can be significantly more expensive than moving the database to one larger machine. Be cautious with this decision.
Depending on replication requirements, we can save operational costs by implementing multiple databases, replicating data using batch processes overnight, and running microservices on Azure Functions to handle the distributed data. This takes time to design and implement, so Citus is the more straightforward first step when migrating to a cloud-native architecture for immediate scaling.
Using the Cosmos DB for this application is possible, but requires denormalizing the data. Spring Boot provides an implementation of the Java Persistence Architecture (JPA), upon which the implementation of PetClinic depends. Microsoft provides Azure Spring Data Cosmos client library for Java, which might have helped replace JPA, but denormalizing the data means rewriting the application, which is beyond the scope of this article.
Regardless, the following process delivers a high-performing application with only modest changes, allowing time to consider how to migrate to a NoSQL environment.
The demonstration below rearchitects an application using APIs to be truly cloud native. It underscores that a service-based architecture hides the data implementation, which provides another way to isolate the application from changes to a NoSQL database.
Implementation
Before proceeding, you must implement your cluster. You can use the process detailed in the second article in this series to migrate your data into this cluster.
Create the Database
Citus is a type of PostgreSQL implementation, so the process for implementing your database is like the process in the previous article.
Start by logging in to the Azure Portal and, on the Home page, click Create a Resource. Then type “Azure Database for P” in the search box. In the list of results, select Azure Database for PostgreSQL.
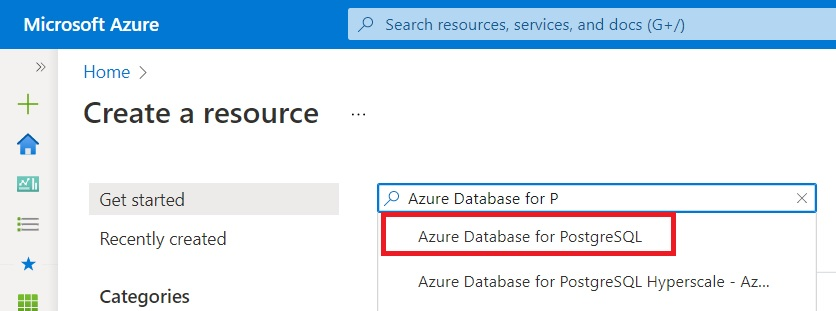
On the next page, click Create, then scroll until you see Hyperscale (Citus) server group and click Create.
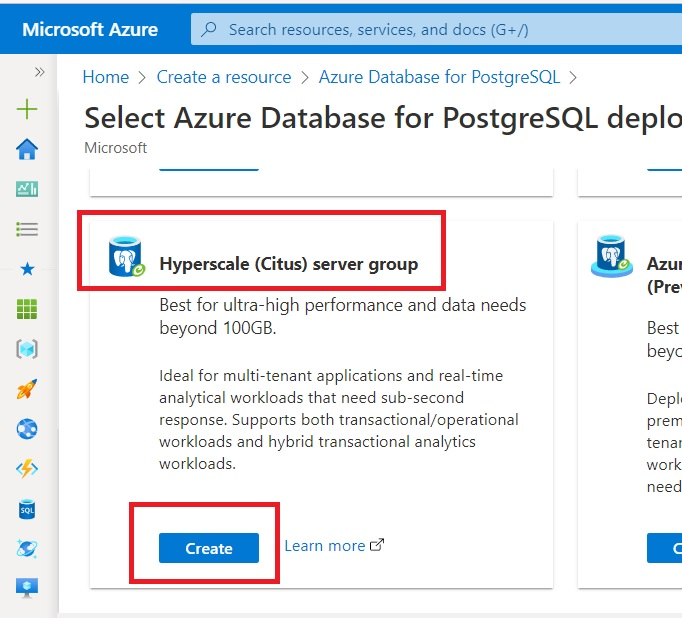
Select your Resource Group or create a new one:
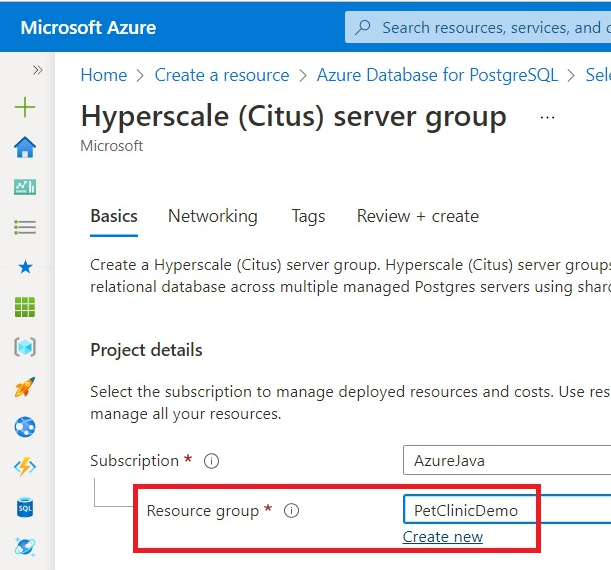
To start configuring the server group, fill in the Server group name and select a PostgreSQL version.

Next, configure the server group. For this tutorial, select the Basic tier.

Then scroll down to configure the node. Select the smallest node available.

When you’ve set it up, click Save. That completes the server group configuration.
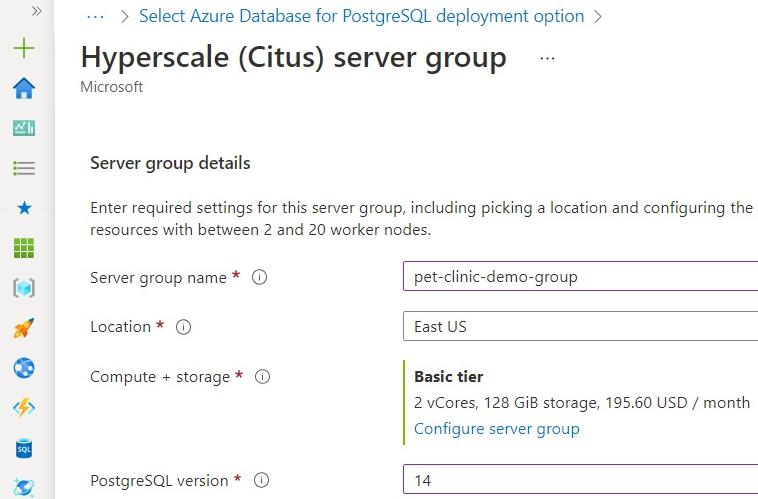
Scroll down and set the Administrator account password, and click Next: Networking.
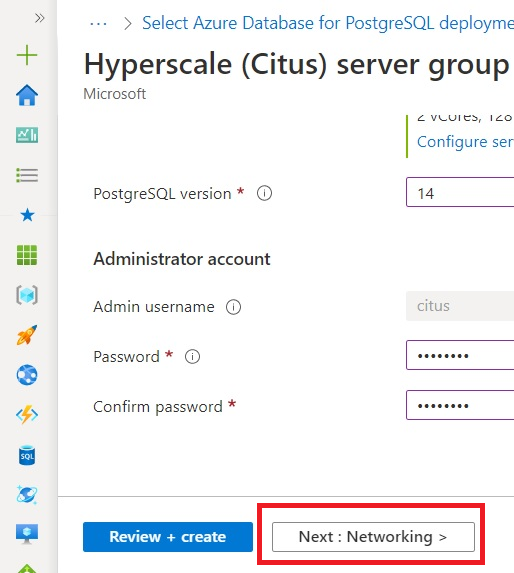
By default, Citus blocks all access to the database. You’re going to configure access from the local machine and from other Azure services. After you’ve configured networking, click Review + Create.
Review the configuration and click Create. The deployment takes a while, but when complete, you’ll see the following:

Migrating Data
Before you can import your data, you must create the PetClinic role.
In the Azure Portal, navigate to the resource and click Roles.
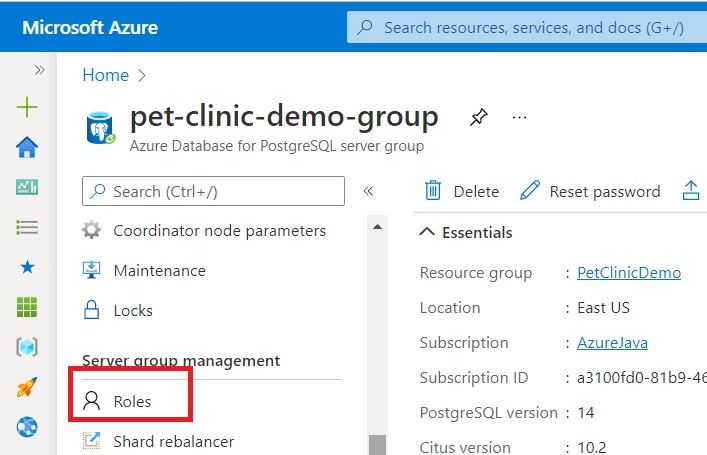
In the new blade, click Add. In the next blade, set the username and password. Note that you can’t use the petclinic password (used in the PetClinic application).

After adding the role, import the data. To manage partitioned tables, Citus restricts the ability to create databases, so you cannot create a PetClinic database. Instead, you’ll use PSQL (a terminal-based front-end to PostgreSQL) to create a petclinic schema in the Citus database that the petclinic user owns. The port is always 5432 and the hostname for the command has the form:
c.<Server Group name>.postgres.azure.com
The last two arguments are the username, Citus, and the database name, which is also Citus. Use this command to start PSQL:
C:\Projects\PetClinic\postgresDb>psql
--host=c.pet-clinic-demo-group.postgres.database.azure.com --port=5432 citus citus
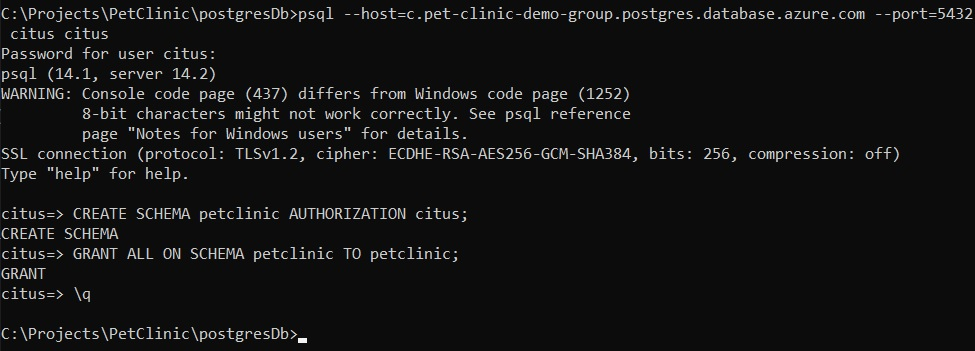
The password is the password you set when setting up the database. In this demo, it’s P@ssword. The command to create the petclinic schema is:
CREATE SCHEMA petclinic AUTHORIZATION citus;
And the command to set access to the user’s petclinic is:
GRANT ALL ON SCHEMA petclinic to petclinic;
Import Data
Now that the schema exists, import the data. When distributing tables into shards, some values exist in multiple locations. For example, the current database relies on sequence tables to generate the next ID for most tables. However, each node has a separate copy of those tables and cannot synchronize the values.
For this reason, Citus will prevent you from distributing any table that generates an identity. Almost all tables in this application use this mechanism to generate their primary key, so you must change this to be able to distribute your tables.
The best resolution is to change the ID columns to varchar to accept unique universal identifiers (UUIDs). However, that means changing the values in the tables that create the key and all the foreign references to these keys. It also entails changing the application to provide those values when it adds records.
Instead, this demonstration takes a shortcut using an old feature of PostgreSQL: the SERIAL keyword. It provides the necessary behavior and Citus will distribute the tables without having to change the application to provide keys.
This was only one change necessary to migrate the data. You must also modify the original database export script by:
- Connecting to the Citus database (the
petclinic database doesn’t exist) - Removing the commands to create the
petclinic database - Changing references to point to the
petclinic schema - Removing the primary key constraint on the
visits table (you’ll add a new primary key later) - Changing all
GENERATED values to SERIAL values - Removing the commands that reset the sequence values (you'll do that after importing the data)
To make these changes, connect to the Citus database.
\connect citus
Comment out the following commands to avoid trying to create the database:
Replace public with petclinic. You can view those changes in the citusData2.pg file.
Remove the primary key constraint on the visits table (you’ll add a new primary key later).
Change the primary key type from integer to SERIAL.
This is an example of the changes for each table:
CREATE TABLE petclinic.owners (
id SERIAL,
first_name text,
last_name text,
address text,
city text,
telephone text
);
The script modifies all the tables to add generated values.
The following is an example of the commented code that updates the vets table. You’ve made this change to all tables.
Remove the commands to reset the sequences for the generated values. This is an example of the change:
-- Name: owners_id_seq; Type: SEQUENCE SET; Schema: petclinic; Owner: petclinic
--SELECT pg_catalog.setval('petclinic.owners_id_seq', 11, true);
After making these changes, run the script to import the data. In this command, use the -U petclinic option to set the username and -f citusData2.pg to set the name of the file with import commands. The last argument sets the database to citus:
C:\ContentLab\Projects\PetClinic\postgresDb>psql
--host=c.pet-clinic-demo-group.postgres.database.azure.com --port=5432 -U petclinic -f citusData2.pg citus
The full listing is long, so will be truncated here. The beginning appears below:

The next image shows the end. You shouldn’t see any error messages.

Distribute the Tables
The introduction discussed sharding the visits data using a vet_id. However, the PetClinic application didn’t implement a vet id column in the visits table in the current data design. Additionally, there’s no association of veterinarians with pets or owners. Therefore, there’s no way to track which veterinarian is treating a pet.
You will fix this by adding a vet id column to the visits table. Then you’ll add a new primary key that is the composite of the vet_id and table id values. Afterward, you’ll shard and distribute the visit data. Finally, you will shard the remaining tables as reference tables to be available locally on each node.
First, add the Vets column. You won’t implement a not null constraint at this time.
Do this with the following PSQL commands.
Start PSQL with:
C:\ContentLab\Projects\PetClinic\postgresDb>psql
--host=c.pet-clinic-demo-group.postgres.database.azure.com --port=5432 -U petclinic citus
Then add the new column with:
alter table visits add column vet_id integer;
Afterward, add the foreign key constraint. These commands are on two lines in the screenshot.
alter table visits add foreign key (vet_id) references vets(id);
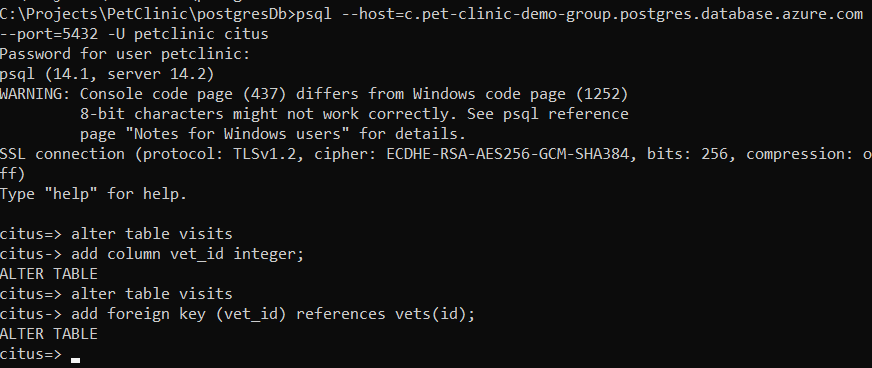
Next, populate the empty vet_id values. Since PetClinic never assigned each visit to a particular vet, you have two choices:
- Assign all visits to an existing
vet. - Create a
vet named “Not Assigned” and assign all visits to this one.
Implement this second option so that the app can track which visits weren’t associated with a veterinarian. Do this with your current PSQL session.
First, use a basic SELECT statement to retrieve a list of all veterinarians currently in the table to find the highest index:
select * from vets;
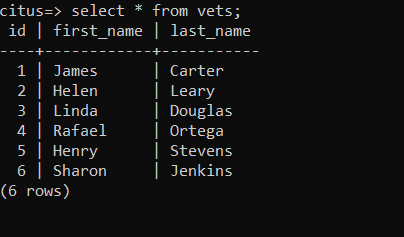
Then insert “Not Assigned” with an SQL INSERT:
Insert into vets (id, first_name, last_name)
Values (7, ‘Not’, ‘Assigned’);

And verify the change with an SQL SELECT:
select * from vets;

Now that you have the index of your new veterinarian, you can insert that into the visits table and verify the change with:
update visits set vet_id=7;
select * from visits;

Now that the data is complete and every row has a valid value in the columns that compose the new key, add the composite key with:
alter table visits add primary key (id, vet_id);
The SERIAL feature automatically sets the not null constraint. The \d visits command describes the table.

Before you can shard the visits table, you must define the reference tables. Citus provides a function to do this, which you can execute using the PSQL SELECT command. The following screen captures are of the owners table, but every other table except the visits table requires this change:
select create_reference_table(‘owners’);

Finally, you can shard the visits table using the Citus create_distributed_table function:
select create_distributed_table(‘visits’, ‘vet_id’ );

To verify that the database is functional, run the following query (distributed here over several lines for readability):
select vets.first_name, vets.last_name, pets.name,
visits.visit_date, visits.description,
owners.first_name, owners.last_name
from pets
join owners
on pets.owner_id = owners.id
left join visits
on visits.pet_id = pets.id
join vets
on visits.vet_id = vets.id;

If you want more details about what is in each of the sharding tables, try select * from citus_shards. PostgreSQL provides the citus_shards view as an overview of the shards. You can find out more about these tables and views at Citus Table and Views.
Connect the Application
To connect PetClinic to your new database, you must obtain the connection string from Azure.
Additionally, you can use it to update the application-postgres.properties file:
spring.datasource.url=${POSTGRES_URL:jdbc:postgresql://c.pet-clinic-demo-group.postgres.database.azure.com:5432/citus}
spring.datasource.username=${POSTGRES_USER:petclinic}
spring.datasource.password=${POSTGRES_PASS:P@ssword}
After updating the file, restart PetClinic, open a browser and retrieve the URL for your application host. You can see that the application is almost ready.
However, the current implementation doesn’t support adding a new visit. Trying to do so results in an error.
Application Updates
To enable the user to associate a veterinarian with a visit:
- Add a list of veterinarians to the New Visit page for the user to select.
- In visit.java, add
pet_id and vet_id with getters and setters. - In VisitController.java, add a vet repository.
- In VisitController.java, modify the
loadPetWithVisit function to obtain and add the list of veterinarians to the model
Add a Vet List to the New Visit Page
Updated the createOrUpdateVisitForm.html page by adding a list of veterinarians just above the Add Visit button so that the user can pick one.
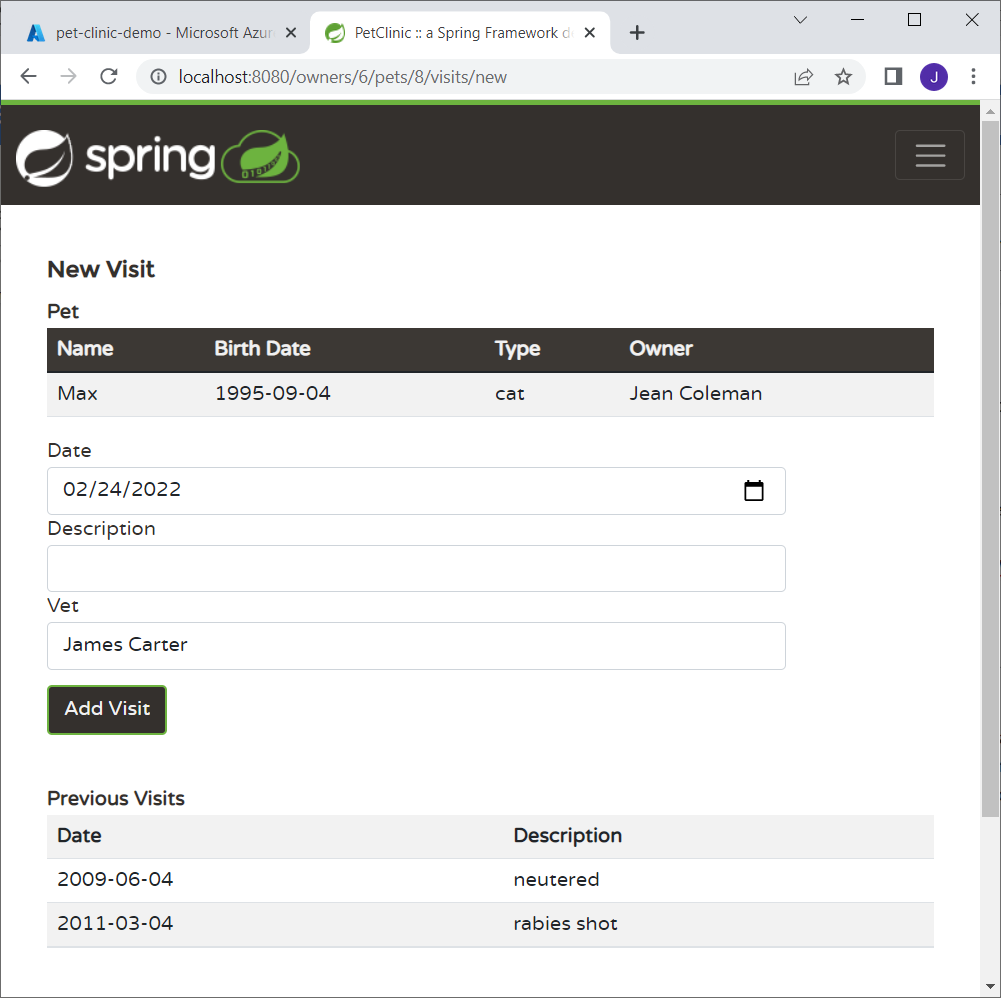
The HTML additions to provide this are:
<div class="form-group">
<label class="col-sm-2 control-label">Vet</label>
<div class="col-sm-10">
<select class="form-control" th:object="${vetList}" id="vetId" name="vetId">
<option th:each="vet : ${vetList}"
th:value="${vet.id}"
th:text="${vet.firstName}+' '+${vet.lastName}"></option>
</select>
<span class="fa fa-ok form-control-feedback" aria-hidden="true"></span>
</div>
</div>
You could use the input fragment provided in inputField.html, but it doesn’t support selecting a choice, so you added the logic directly.
Update Visit.java
To support transferring form data to the web page, add two fields:
private int vet_id;
private int pet_id;
Add the associated getters and setters:
public int getVetId() {
return this.vet_id;
}
public void setVetId(int vet_id) {
this.vet_id = vet_id;
}
public int getPetId() {
return this.pet_id;
}
public void setPetId(int pet_id) {
this.pet_id = pet_id;
}
Update the Visit Controller
Change the constructor to accept an instance of the VetRepository so that you can obtain a list of veterinarians:
public VisitController(OwnerRepository owners, VetRepository vets) {
this.owners = owners;
this.vets = vets;
}
Modify the loadPetWithVisit function to pass that list to the web page in the model:
Owner owner = this.owners.findById(ownerId);
Pet pet = owner.getPet(petId);
Collection<Vet> vetList = this.vets.findAll();
model.put("pet", pet);
model.put("owner", owner);
model.put("vetList", vetList);
Visit visit = new Visit();
pet.addVisit(visit);
return visit;
That completes the changes needed. If you rebuild and redeploy the application, you can return to the New Visit page, select a veterinarian for the visit, and add the visit successfully.
Summary
Migrating the PetClinic application to a high-performance relational data service enables your implementation to scale accordingly while using your existing data structure and Spring Boot’s support for Java Persistence Architecture. Additionally, this limited the changes needed to make the application. In contrast, migrating to a non-relational database would have required the larger task of completely redesigning the application to work with denormalized data.
The Azure Database for PostgreSQL — Hyperscale (Citus) is a relational database that partitions data using sharding. Partitioning improves performance by reducing the volume of data that the database sees when running queries and by keeping the data local to the consuming application.
Despite remaining with a relational database, some changes were necessary to support partitioning. The changes focused on two areas: modifying the table structure to use a key that didn’t rely on replicated data, and attaching a veterinarian’s ID to each visit to enable sharding the visit data.
These changes underscore the fundamental challenge of moving from a traditional relational database to a partitioned database. When distributing data, it’s crucial to remember that the process replicates some data in multiple locations. Additionally, some tables contain only portions of the data set. Limiting scope by including the sharding key ensures that queries remain relevant and functional.
The Citus FAQ identifies some unsupported queries, such as correlated subqueries, so developers should plan accordingly. The PetClinic data model implemented by Spring Boot’s JPA didn’t use any of these query types, so the architecture required few changes.
Scalable data is useful for investigating other ways to make an application more efficient. For example, if PetClinic runs a report for all veterinarians, we can determine whether asynchronous processing might improve the user experience. We can also consider the changes necessary to handle both synchronous and asynchronous processing and how they affect database response. Understanding scalability issues highlights potential changes available for existing systems and enables scalability of new systems from the start.
The next article examines how to improve application scalability and maintenance and takes further steps toward becoming truly cloud-native with cloud-hosted, decoupled services. The process will show you how to make incremental changes to pull apart the monolithic application, retaining value from keeping it running rather than rebuilding it from scratch.
To see how four companies transformed their mission-critical Java applications to achieve better performance, security, and customer experiences, check out the e-book Modernize Your Java Apps.

