AI and data science are rapidly advancing, which brings an ever-increasing amount of data to the table and enables us to derive ideas and solutions that continue to grow more complex every day. But on the other hand, we see that these advances are shifting focus from value extraction to systems engineering. Also, hardware capabilities might be growing at a faster rate than people can learn how to properly utilize them.
This trend either requires adding a new position, a so-called “data engineer,” or requires a data scientist to deal with infrastructure-related issues instead of focusing on the core part of data science — generating insights. One of the primary reasons for this is the absence of optimized data science and machine learning infrastructure for data scientists who are not necessarily software engineers by nature – these can be considered two separate, sometimes overlapping skill sets.
We know that data scientists are creatures of habit. They like the tools that they’re familiar with in the Python data stack, such as pandas, Scikit-learn, NumPy, PyTorch, etc. However, these tools are often unsuited for parallel processing or terabytes of data.
Anaconda® and Intel® are collaborating to solve data scientists’ most critical and central problem: how to make their familiar software stack and APIs scalable and faster? This article introduces Intel Distribution of Modin, part of the Intel oneAPI AI Analytics Toolkit (AI Kit), which is now available from Anaconda’s “defaults” channel (and from conda-forge, too).
Why Pandas Is Not Enough
Though it is an industry standard, pandas is inherently single-threaded for a lot of cases, which makes it slow for huge datasets. It may not even work for datasets that don’t fit in memory. There are other alternatives to solve this issue (e.g., Dask, pySpark, vaex.io, etc.), but none of them provide a fully pandascompatible interface – users would have to modify their workloads accordingly.
What does Modin have to offer you as the end-user? It tries to adhere to the idea of “tools should work for the data scientist, not vice versa.” It offers a simple, drop-in replacement for pandas – you just change your “import pandas as pd” statement to “import modin.pandas as pd” and gain better scalability for a lot of use-cases.
What Modin Offers
By removing the requirement to “rewrite pandas workflow to X framework,” it’s possible to speed up the development cycle for data insights (Figure 1).
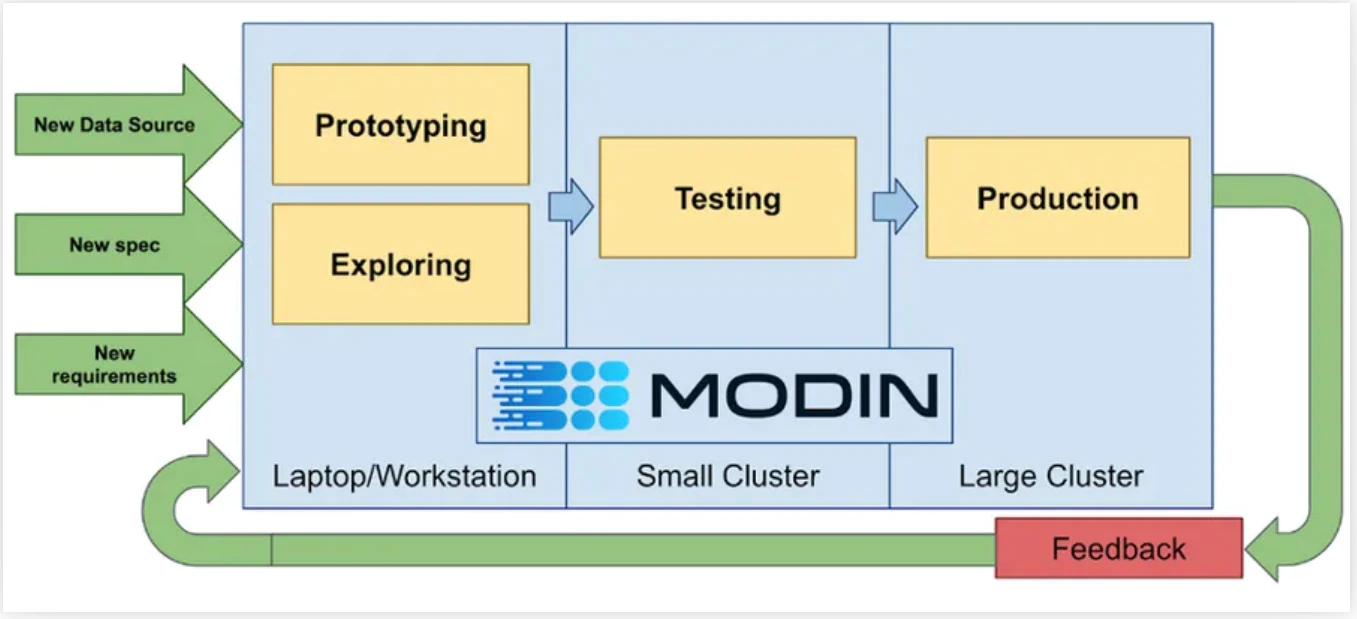
Figure 1. Using Modin in a continuous development cycle
Modin better utilizes the hardware by grid-splitting the dataframe, which allows certain operations to run in a parallel distributed way, be it cell-wise, column-wise, or row-wise (Figure 2). For certain operations, it’s possible to utilize experimental integration with the OmniSci engine to leverage the power of multiple cores even better.

Figure 2. Comparing pandas and Modin DataFrames
By installing Modin through AI Kit or from the Anaconda defaults (or conda-forge) channel, an experimental, even faster OmniSci backend for Modin is also available. It just takes a few simple code changes to activate:
import modin.config as cfg
cfg.Engine.put('native')
cfg.Backend.put('omnisci')
import modin.experimental.pandas as pd
Show Me the Numbers!
Enough with the words, let’s have a look at the benchmarks. For detailed comparison of different Modin engines, please refer to community-measured microbenchmarks, which track performance of different data science operations over commits to the Modin repository.
To demonstrate the scalability of this approach, let’s use a larger, more end-to-end workload running on an Intel Xeon® 8368 Platinum-based server (see full hardware info below) using OmniSci through Modin (Figures 3-5).
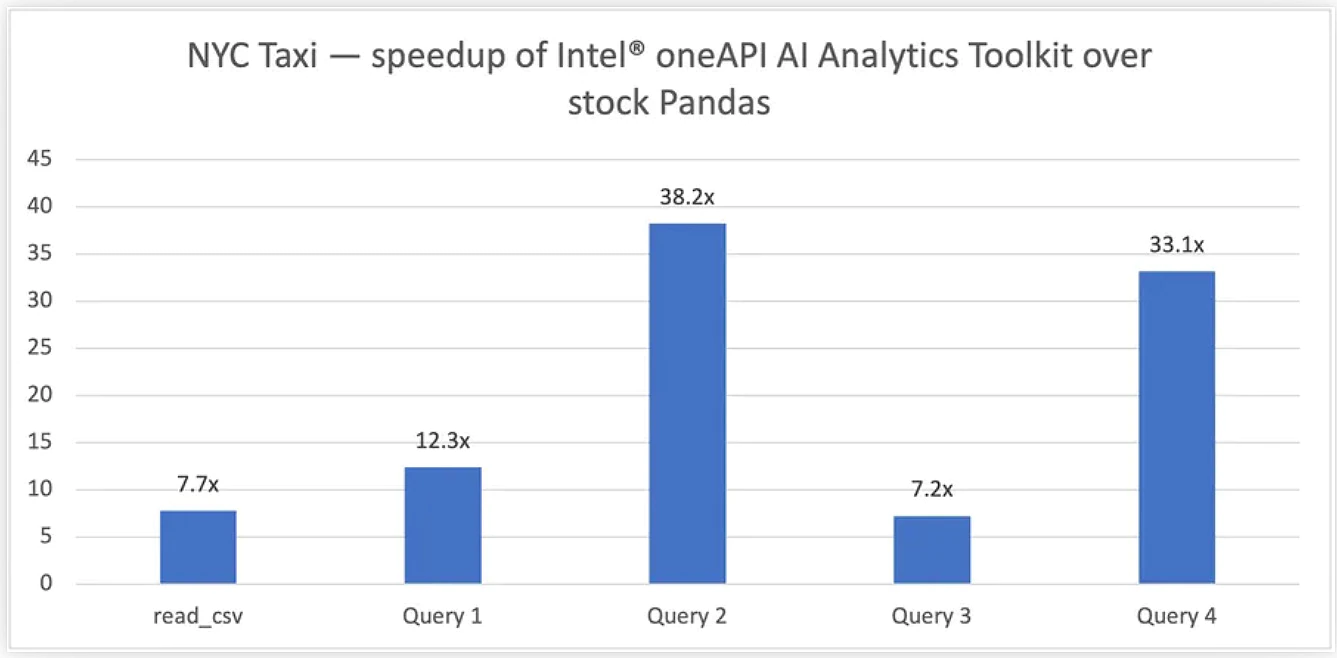
Figure 3. Running the NYC Taxi workload: 200M records, 79.2 GB input dataset
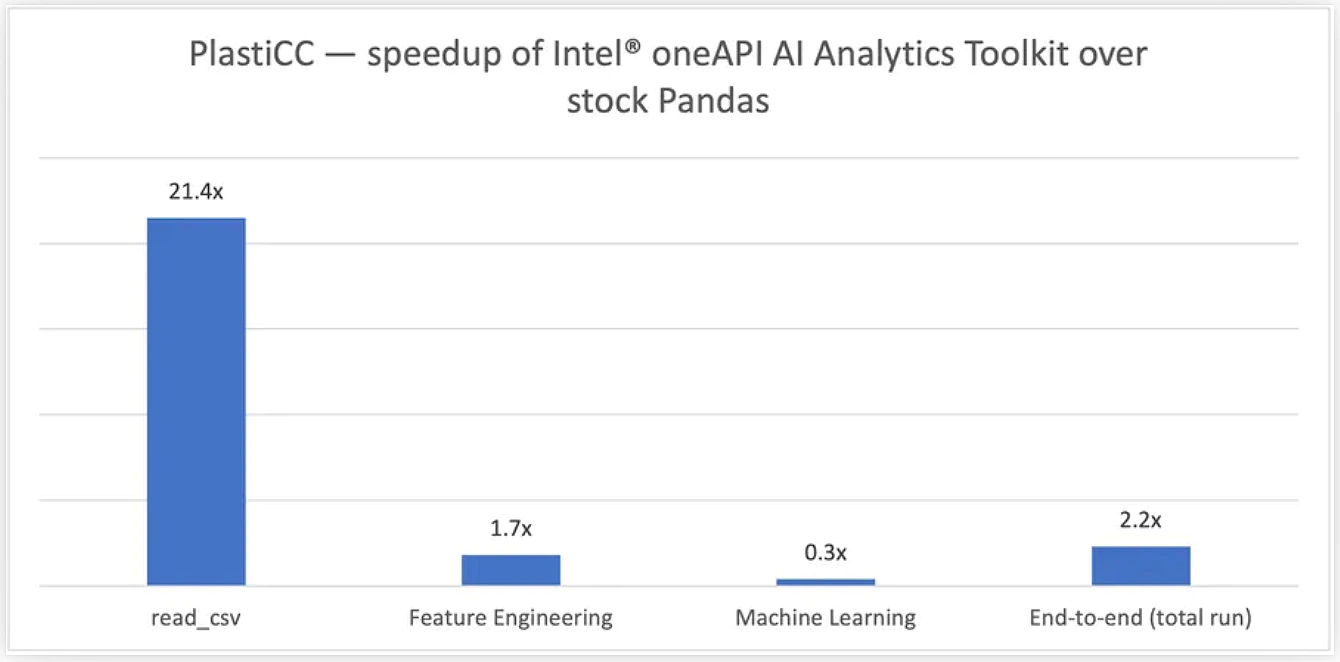
Figure 4. Running the
Census workload: 21M records, 2.1 GB input dataset
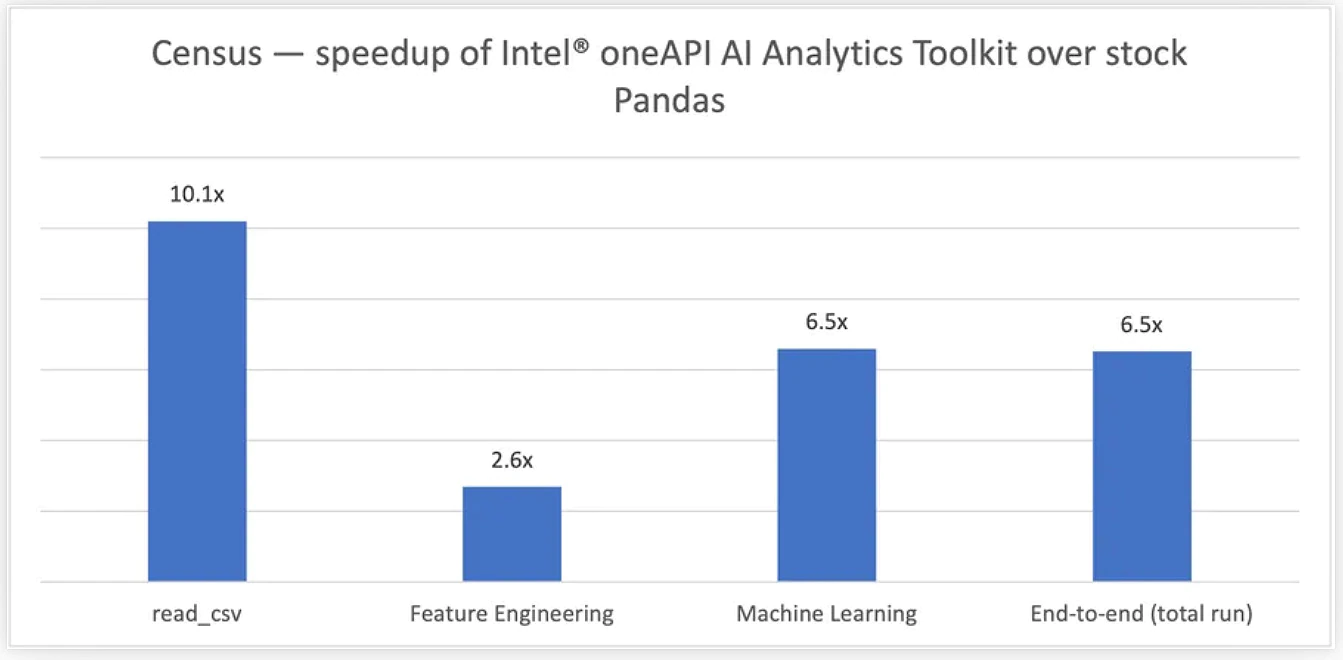
Figure 5. Running the
PlastiCC workload: 460M records, 20 GB input dataset
Hardware information: two 3rd Generation Intel Xeon 8368 Platinum on a C620 board with 512GB (16 slots/32GB/3200) total DDR4 memory, microcode 0xd0002a0, Hyper-Threading on, Turbo on, Centos 7.9.2009, 3.10.0-1160.36.2.el7.x86_64, one Intel 960 GB SSD OS Drive, three Intel 1.9 TB SSD data drives. Software information: Python 3.8.10, Pandas 1.3.2, Modin 0.10.2, OmnisciDB 5.7.0, Docker 20.10.8, tested by Intel on 10/05/2021.
Wait, There’s More
If running on one node is not enough for your data, Modin supports running distributed on a Ray cluster or a Dask cluster. You can also use the experimental XGBoost integration, which will automatically utilize the Ray-based cluster for you without any special set up!
References
This article originally appeared on Anaconda.com and is reprinted with permission.

