The exponential growth of data has fed artificial intelligence’s voracious appetite and led to its transformation from niche to omnipresent. An equally important aspect of this AI growth equation is the ever-expanding demands it places on computer system requirements to deliver higher AI performance. This has not only led to AI acceleration being incorporated into common chip architectures such as CPUs, GPUs, and FPGAs but also mushroomed a class of dedicated hardware AI accelerators specifically designed to accelerate artificial neural networks and machine learning applications. While these hardware accelerators can deliver impressive AI performance improvements, software AI accelerators are required to deliver even higher orders of magnitude AI performance gains across deep learning, classical machine learning, and graph analytics, for the same hardware set-up. What’s more is that this AI performance boost driven by software optimizations is free, requiring almost no code changes or developer time and no additional hardware costs.
Let us try to visualize the scope of the cost savings that can be realized through the 10-100X performance gains that can be realized through software AI acceleration. For example, many of the leading streaming media services have tens of thousands of hours of available content. They might want to use image classification and object detection algorithms for content moderation, text identification, and celebrity recognition. The classification criteria might also be different by country based on local customs and government regulations and the process might need to be repeated for ~10% of the content every month, based on new programs and rule changes. Using the list prices of running these AI algorithms on the leading cloud service providers, even a 10X gain in performance through software AI accelerators can lead to approximate cost savings of millions of dollars a month**.
Similar cost savings can also be realized for other AI services such as automatic caption generation and recommendation engines, and of course the savings are even higher for the use cases with 100X performance improvements. While your particular AI workload might be markedly smaller, your savings could still be rather significant.
Software determines the ultimate performance of computing platforms and software acceleration is therefore key to enabling “AI Everywhere” with applications across entertainment, telecommunication, automotive, healthcare, and more.
What is a “software AI accelerator” and how does it compare to a hardware AI accelerator?
A software AI accelerator is a term used to refer to the AI performance improvements that can be achieved through software optimizations for the same hardware configuration. A software AI accelerator can make platforms over 10-100X faster across a variety of applications, models, and use-cases.
The increasing diversity of AI workloads has necessitated a business demand for a variety of AI-optimized hardware architectures. These can be classified into three main categories: AI-accelerated CPU, AI-accelerated GPU, and dedicated hardware AI accelerators. We see multiple examples of all three of these hardware categories in the market today, for example Intel Xeon CPUs with DL Boost, Apple CPUs with Neural Engine, Nvidia GPUs with tensor cores, Google TPUs, AWS Inferentia, Habana Gaudi and many others that are under development by a combination of traditional hardware companies, cloud service providers, and AI startups.
While AI hardware has continued to take tremendous strides, the growth rate of AI model complexity far outstrips hardware advancements. About three years ago, a Natural Language AI model like ELMo had ‘just’ 94 million parameters whereas this year, the largest models reached over 1 trillion parameters. The exponential growth of AI has meant that even 1000X increases in computing performance can be easily consumed to solve ever-more complex and interesting use-cases. Solving the world’s problems and getting to the holy grail of “AI everywhere” is therefore only possible through the orders of magnitude performance enhancements driven by software AI accelerators.
While hardware acceleration is like updating your bike to have the latest and greatest features, software acceleration is more like having a completely re-envisioned mode of travel such as a supersonic jet.

This article specifically lays out the performance data of software AI accelerators on Intel Xeon. However, we believe that similar magnitudes of performance improvements can be achieved on other AI platforms from AI-accelerated CPUs and GPUs to dedicated hardware AI accelerators. We intend to share performance data for our other platforms in future articles but we also welcome other vendors to share their software acceleration results.
AI software ecosystem — performant, productive, and open
As AI use cases and workloads continue to grow and diversify across vision, speech, recommender systems, and more, Intel’s goal has been to provide an unparalleled AI development and deployment ecosystem that makes it as seamless as possible for every developer, data scientist, researcher, and data engineer to accelerate their AI journey from the edge to the cloud.
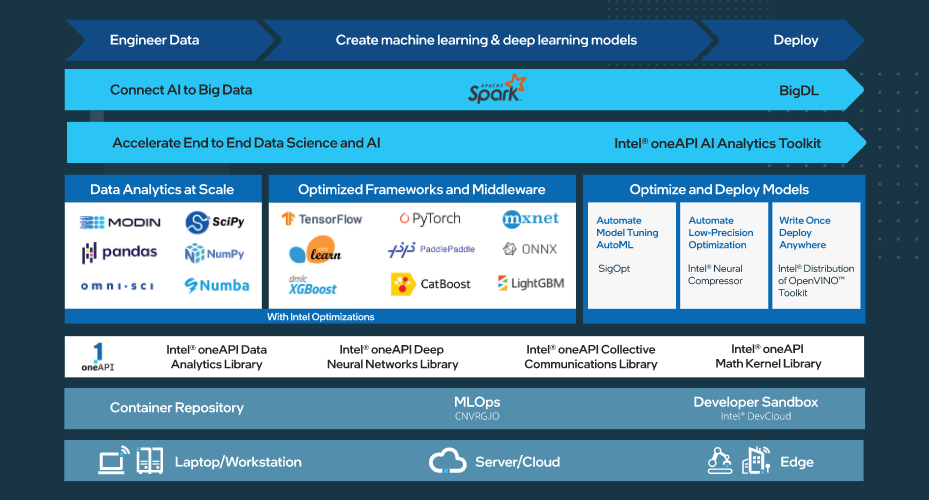
We believe that an end-to-end AI software ecosystem, built on the foundation of an open, standards-based, interoperable programming model, is key to scaling AI and data science projects into production. This core tenet forms the foundation of our 3-pronged AI strategy.
- Build upon the broad AI software ecosystem — First, it is critical for us to embrace the current AI software ecosystem. We want everyone to use the software that they are familiar with in deep learning, machine learning, and data analytics, for example from TensorFlow and PyTorch, SciKit-Learn and XGBoost, to Ray and Spark. We have heavily optimized these frameworks and libraries to help increase their performance by orders of magnitude on Intel platforms designed to deliver drop-in 10-100X software AI acceleration.
- Implement end-to-end data science and AI workflow — Second, we want to innovate and deliver a rich suite of optimized tools for all your AI needs, including data preparation, training, inference, deployment, and scaling. Examples include the Intel oneAPI AI Analytics toolkit to accelerate end-to-end data science and machine-learning pipelines, Intel distribution of OpenVINO toolkit to deploy high-performance inference applications from device to cloud, and Analytics Zoo to seamlessly scale your AI models to big data clusters with thousands of nodes for distributed training or inference.
- Deliver unmatched productivity and performance — Lastly, we provide the tools for deployment across diverse AI hardware by being built on the foundation of an open, standards-based, unified oneAPI programming model and constituent libraries. The multitude of hardware AI architectures in the market today, each with a separate software stack, make for an inefficient and unscalable approach for the developer ecosystem. The oneAPI industry initiative encourages cross-industry collaboration on the oneAPI specification to deliver a common developer experience across all accelerator architectures.
Software AI accelerators in deep learning, machine learning, and graph analytics
Let us delve deeper into the first prong of our three-pronged AI strategy — Software AI Accelerators. Our extensive software optimization work provides a simple way for data scientists to efficiently implement their algorithms, which consist of graphs of operations or kernels. Our libraries and tools provide both kernel optimizations for individual operations (eg.: effective use of SIMD registers, vectorization, cache friendly data access when implementing convolution) and graph level optimizations (using techniques such as batchnorm folding, conv/ReLU fusion and Conv/Sum fusion) across operations. Refer to this talk for more detailed information on our SW optimization techniques.
While some of you may find the implementation details interesting, we’ve done the heavy lifting in abstracting these optimizations for developers, so they don’t need to deal with the intricacies. Whether in deep learning, machine learning, or graph analytics, these Intel optimizations are designed for vast performance gains.
Deep learning
Intel software optimizations through the oneDNN library deliver orders of magnitude performance gains to several popular deep learning frameworks and most of the optimizations have already been up-streamed into the default framework distributions. However, for TensorFlow and PyTorch we also maintain separate Intel extensions as a buffer for advanced optimizations not yet up-streamed.
- TensorFlow — Intel optimizations deliver a 16X gain in image classification inference and a 10X gain for object detection. The baseline is stock TensorFlow with basic Intel optimizations, up streamed to functions in the TensorFlow Eigen library.

Above: Platinum 8380: 1-node, 2x Intel Xeon Platinum 8380 processor with 1 TB (16 slots/ 64GB/3200) total DDR4 memory, uCode 0xd000280, HT on, Turbo on, Ubuntu 20.04.1 LTS, 5.4.0-73-generic1, Intel 900GB SSD OS Drive; ResNet50v1.5,FP32/INT8,BS=128,https://github.com/IntelAI/models/blob/master/benchmarks/image_recognition/tensorflow/resnet50v1_5/README.md;SSDMobileNetv1,FP32/INT8,BS=448,https://github.com/IntelAI/models/blob/master/benchmarks/object_detection/tensorflow/ssd-mobilenet/README.md. Software: Tensorflow 2.4.0 for FP32 & Intel-Tensorflow (icx-base) for both FP32 and INT8, test by Intel on 5/12/2021. Results may vary. For workloads and configurations visit www.Intel.com/PerformanceIndex.
- PyTorch — Intel optimizations deliver a 53X gain for image classification and nearly 5X gain for a recommendation system. We have up-streamed most of our optimizations with oneDNN into PyTorch, while also maintaining a separate Intel Extension for PyTorch as a buffer for advanced optimizations not yet up-streamed. So, for this comparison we created a new baseline by keeping PyTorch with only basic Intel optimizations without oneDNN.

Above: Platinum 8380: 1-node, 2x Intel Xeon Platinum 8380 processor with 1 TB (16 slots/ 64GB/3200) total DDR4 memory, uCode 0xd000280, HT on, Turbo on, Ubuntu 20.04.1 LTS, 5.4.0-73-generic1, Intel 900GB SSD OS Drive; ResNet50 v1.5, FP32/INT8, BS=128, https://github.com/IntelAI/models/blob/icx-launch-public/quickstart/ipex-bkc/resnet50-icx/inference; DLRM, FP32/INT8, BS=16, https://github.com/IntelAI/models/blob/icx-launch-public/quickstart/ipex-bkc/dlrm-icx/inference/fp32/README.md. Software: PyTorch v1.5 w/o DNNL build for FP32 & PyTorch v1.5 + IPEX (icx) for both FP32 and INT8, test by Intel on 5/12/2021. Results may vary. For workloads and configurations visit www.Intel.com/PerformanceIndex.
- MXNet — Intel optimizations deliver 815X and 500X gains for image classification. The situation for MXNet is also different from TensorFlow and PyTorch. We have up streamed all our optimizations with oneDNN. So, for this comparison we created a new baseline without any Intel optimizations.

Above: Platinum 8380: 1-node, 2x Intel Xeon Platinum 8380 processor with 1 TB (16 slots/ 64GB/3200) total DDR4 memory, uCode 0xd000280, HT on, Turbo on, Ubuntu 20.04.1 LTS, 5.4.0-73-generic1, Intel 900GB SSD OS Drive; ResNet50v1,FP32/INT8,BS=128,https://github.com/apache/incubatormxnet/blob/v2.0.0.alpha/python/mxnet/gluon/model_zoo/vision/resnet.py;MobileNetv2,FP32/INT8,BS=128,https://github.com/apache/incubatormxnet/blob/v2.0.0.alpha/python/mxnet/gluon/model_zoo/vision/mobilenet.py. Software: MXNet 2.0.0.alpha w/o DNNL build for FP32 & MXNet 2.0.0.alpha for both FP32 and INT8, test by Intel on 5/12/2021. Results may vary. For workloads and configurations visit www.Intel.com/PerformanceIndex.
Machine learning
Scikit-learn is a popular machine learning software library for Python. It features various classification, regression, and clustering algorithms including support vector machines, random forests, gradient boosting, and k-means. We were able to enhance performance of these popular algorithms significantly by up to 100-200X. These performance gains are available through the Intel Extension for Scikit-learn and the Intel oneAPI Data Analytics Library (oneDAL).
Graph analytics
Graph analytics refers to algorithms used to explore the strength and direction of relationships among entries in large graph databases such as social networks, the internet and search, Twitter, and Wikipedia. Examples of widely used graph analytics algorithms include single-source shortest path, breadth-first search, connected components, page rank, betweenness centrality, and triangle counting. As an example, Intel optimizations show significant improvement with the Triangle Counting Algorithm. The level of optimization increases as graphs get larger, with the largest performance gains of 166X for the largest graphs approaching 50 million vertices and 1.8 billion edges. This article provides a more complete overview of Intel optimizations for several other graph analytics algorithms.
AI everywhere — applications of software AI acceleration
To solve a problem with AI requires an end-to-end workflow. We start from data and each use case has its unique AI data pipeline. An AI practitioner will have to ingest data, pre-process by feature engineering sometimes using machine learning, train the model using deep learning or machine learning, and then deploy the model. The Intel oneAPI AI Analytics Toolkit provides high-performance APIs and Python packages to accelerate all phases of these pipelines and achieve big speed ups through software AI acceleration. Take an in-depth look at two real-world examples (U.S. Census and PLAsTiCC Astronomical Classification) where the Intel oneAPI AI Analytics Toolkit helps data scientists accelerate their AI pipelines in this article.
While we have seen that software AI accelerators are already delivering performance improvements critical to the growth of AI and its promulgation to every domain and use-case, we have opportunities to do even more going forward. We at Intel are working on compiler technologies, memory optimizations, and distributed compute to drive further software AI acceleration. There are also opportunities for the entire AI software community to work together, to truly unleash the power of software AI accelerators — with Intel and other hardware vendors spearheading low-level software and framework optimizations and software vendors leading the higher-level optimizations, which can then come together with an industry standard intermediate representation.
We would also like to encourage AI system builders to place a greater emphasis on software and for developers and practitioners to be relentless in their pursuit for AI performance acceleration opportunities.
(1) Always use the latest versions of deep learning and machine learning frameworks (TensorFlow, PyTorch, MXNet, XGBoost, Scikit-learn and others) that already have many of the intel optimizations up-streamed.
(2) For even greater performance, use the Intel extensions of the frameworks that include all the latest optimizations and are fully compatible with your existing workflows.
Learn more about the drop-in framework optimizations and performance-optimized end-to-end tools that make up the Intel AI software suite and supercharge your AI workflow by up to 100X!
Software AI accelerators in concert with continued hardware AI acceleration can finally get us to a future with “AI everywhere” and a world which is smarter, more connected, and better for all its inhabitants.
Notices and Disclaimers
Performance varies by use, configuration, and other factors. Learn more at www.Intel.com/PerformanceIndex. Performance results are based on testing as of dates shown in configurations and may not reflect all publicly available updates. See backup for configuration details. No product or component can be absolutely secure. Your costs and results may vary. Intel technologies may require enabled hardware, software, or service activation. © Intel Corporation. Intel, the Intel logo, and other Intel marks are trademarks of Intel Corporation or its subsidiaries. Other names and brands may be claimed as the property of others.
** This calculation is an approximation based on publicly available information regarding (a) Hours of streaming content and countries of operation for leading streaming providers such as but not limited to Netflix, Amazon Prime, Disney, and others and (b) Cost of using computer vision and NLP AI services on leading US CSPs including but not limited to AWS, Microsoft Azure, and Google Cloud. This estimation is only intended to be used as an illustration of the scope of the problem and potential cost savings and Intel doesn’t guarantee its accuracy. Your costs and results may vary.
Wei Li is VP & Chief Architect, Machine Learning Software & Performance at Intel.

