As most developers have been using Kafka for several years, many who have used it for cloud-based projects have experienced mixed results.
The cloud offers several well-known benefits like availability and scalability. However, using Kafka in the cloud has traditionally required at least one developer with Kafka admin experience to handle the complexities of cluster creation and deployment.
This article series explores the creation and use of a Kafka cluster using HDInsight, which can provide a far smoother experience than what was previously possible. The first part examines the seamless application setup. This series’ second article explores using HDInsight for streaming data into Kafka. Finally, the third article demonstrates the process of analyzing the streamed data.
Before beginning, let’s give some context to the project.
The Scenario
This demonstration simulates an automated bread bakery that runs 24 hours a day. To maintain simplicity, the hypothetical factory has only three machines: a mixer, a continuous oven, and a packing machine.
Each machine contains several sensors that feed information into a database, which the factory uses for continuous monitoring and quality control purposes. Some sensors collect information at sub-second rates, while other sensors provide point-in-time readings.
Kafka provides an ideal architecture to oversee the collection of this data. In a live environment, the data would feed into a machine-learning model. The model outcome determines expected failures and predictive maintenance schedules. For this example, the data feeds into a NoSQL database. The primary focus is on collecting the data.
Below is a summary of the machines and sensors in the simulated bakery. It also contains the information that generates the data.
| Machine | Sensor | Unit | Expected Value | Standard Deviation | Readings per Second |
| Mixer | Mass | kg | 150 | 4 | 0.2 |
| Mixer | Rotation | rpm | 80 | 20 | continuous |
| Mixer | FillPressure | kPa | 500 | 60 | 10 |
| Mixer | BowlTemp | Degrees Celsius | 25 | 1 | 10 |
| Oven | OvenSpeed | m/s | 0.2 | 0.05 | continuous |
| Oven | ProveTemp | Degrees Celsius | 28 | 0.5 | 1 |
| Oven | OvenTemp1 | Degrees Celsius | 180 | 2 | 5 |
| Oven | OvenTemp2 | Degrees Celsius | 180 | 0.5 | 5 |
| Oven | OvenTemp3 | Degrees Celsius | 220 | 0.1 | 10 |
| Oven | CoolTemp1 | Degrees Celsius | 15 | 2 | 2 |
| Oven | CoolTemp2 | Degrees Celsius | 15 | 5 | 1 |
| Packing | PackSpeed | m/s | 0.2 | 0.05 | continuous |
| Packing | PackCounter | number per second | 5 | 0.1 | 10 |
Note: The example assumes high availability so that the company can scale the database for use at other factories.
The Architecture
Azure has certain requirements for setting up a cluster on HDInsight. For example, selecting fewer than three ZooKeeper nodes enables the initial validation to pass. However, in the instantiation process, the deployment halts because it requires at least three of these nodes.
While this may be possible to reconfigure, this article uses the minimum amount that Azure requires. As many Azure services use the ZooKeeper nodes, it’s most sensible not to interfere with what already works.
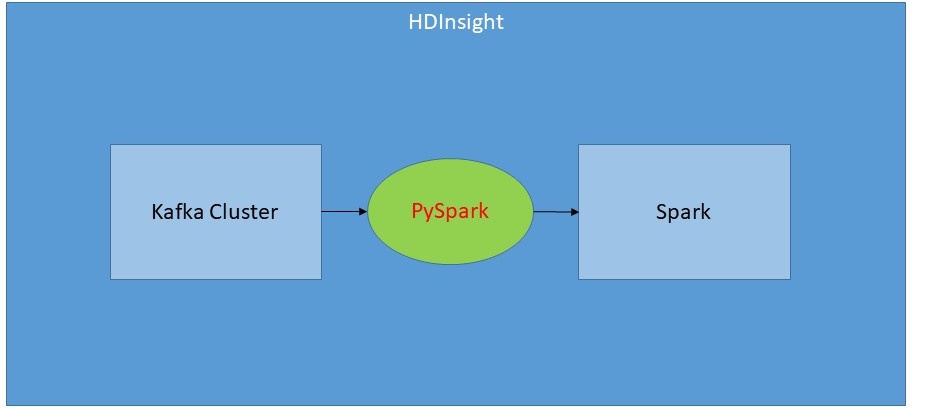
First, we need to create an HDInsight cluster. The cluster consists of Apache Kafka and Apache Spark clusters. The Kafka cluster contains the typical ZooKeeper and Broker nodes while the Spark cluster has the head and worker nodes.


The Implementation
There are several ways to set up an HDInsight cluster and numerous documents and articles describing how to do so. In this tutorial, we’ll use the simplest method, which is to use a custom deployment template in the Azure portal.
Microsoft makes deploying a custom template easy. Additionally, an edited version of the JSON file for upload is available on GitHub.
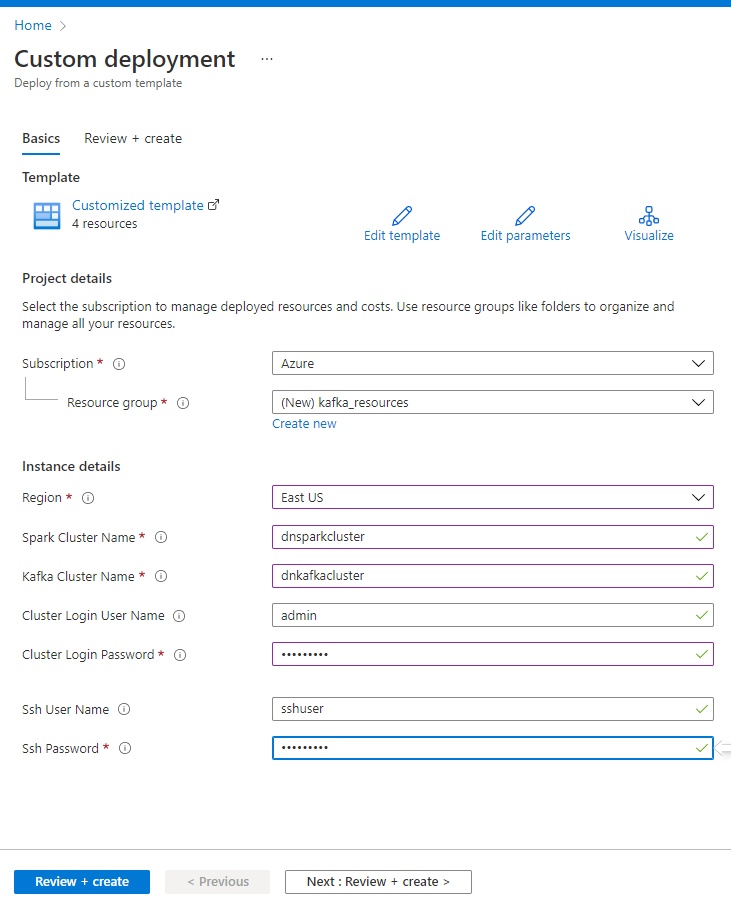
After logging into the Azure portal, the link directs the user to the Custom Template page, where they can enter the information as required.
It’s encouraged to create a new resource group that will encapsulate the entire deployment. As a result, deleting the deployment when finished is a simple process that only requires deleting the resource group.
There are a few points worth mentioning here.
First, setting up a Kafka cluster requires several virtual machines, each with several cores. For the basic account, we may need to increase our quota for the region we choose. We can do so by opening a service ticket from the portal user interface.
Second, Azure charges by the hour for resources used in the clusters. These charges are pro-rated by the minute. This means that as soon as the cluster is active, the Azure user starts paying. Therefore, it’s important to remember to delete the resource group once the exercise is complete.
The environment category for our requirements is “high-end.” To reduce some of these charges, it’s possible to lower the virtual machine specs within the template. This should be completed before filling in the field values because saving the template changes will erase any entered field values.
To begin modifying the template, click Edit Template near the top of the page.
Within the two cluster sections in the template file, there’s a section called computeProfile.
"computeProfile": {
"roles": [
{
The descriptions for each virtual machine are within the roles tag. The instance count and machine size can be set here.
"roles": [
{
"name": "headnode",
"targetInstanceCount": "2",
"hardwareProfile": {
"vmSize": "Standard_D12_v2"
},
"osProfile": {
Use Ctrl-F to find the occurrences of vmSize. Then replace each with Standard_E2_v3. The E2 is a small virtual machine with two cores. The template deploys clusters for live, fault-tolerant operation. This is ideal for a final deployment, but it’s not necessary for our needs.
At this juncture, these are the only required changes.
Click Review and Create. Then Azure begins the deployment process. This process can take between 20 to 45 minutes and can depend heavily on system load in the selected region.
The Simulation
To simulate the processes of a small bakery, it’s necessary to write and deploy a Kafka producer application. This program will generate simulated machine sensor readings at various rates.
The producer.py application is a simple Python script that can be configured from the command line. The default options allow for a quick test, which provides considerable flexibility. When executed through a shell, many concurrent copies of the program can execute. Essentially, a developer can then supply Kafka with as many copies as desired.
To complete this process, submit a PySpark sink job, which analyzes the incoming data. Since PySpark is declarative, declare the processing required and then wait for the results. This will be further examined in the final article of this series.
You can visit GitHub to view the full application as you work through the rest of this series.
Conclusion
Setting up a Kafka cluster on HDInsight is a simple, single-step process. It doesn’t require any Kafka admin skill.
There are many benefits to using Kafka. It excels in replication, structured streaming, in-sequence delivery, and transformation of data. Kafka performs identically whether it’s in-house or on Azure.
The primary difference is in the setup. Any developer who has previously set up a multi-node Kafka cluster knows how difficult it can be. Therefore, they generally defer to a Kafka admin to complete this task.
Using HDInsight TO perform this setup eliminates the hassle and the need to involve another party. All it takes to create a cluster is the completion of a few entries on a form. The simplicity with which it handles this process is unparalleled. Click over to Part Two of the series to explore how to stream data into Kafka.
To learn more about streaming at scale in HDInsight, and Apache Kafka in Azure HDInsight, check out these Microsoft Azure Developer Community resources.

