In this post, we look at how to investigate or debug the BigQuery usage.
This article appeared first on https://www.pascallandau.com/ at BigQuery: Monitor Query Costs via INFORMATION_SCHEMA.
Cost monitoring in Google BigQuery can be a difficult task, especially within a growing organization and lots of (independent) stakeholders that have access to the data. If your organization is not using reserved slots (flat-rate pricing) but is billed by the number of bytes processed (on-demand pricing), costs can get quickly out of hand, and we need the means to investigate or "debug" the BigQuery usage in order to understand:
- who ran queries with a high cost
- what were the exact queries
- when did those queries run (and are they maybe even running regularly)
Previously, we had to manually set up query logging via Stackdriver as explained in the article Taking a practical approach to BigQuery cost monitoring but in late 2019, BigQuery introduced INFORMATION_SCHEMA views as a beta feature that also contain data about BigQuery jobs via the INFORMATION_SCHEMA.JOBS_BY_* views and became generally available (GA) at 2020-06-16.
Examples
SELECT
creation_time,
job_id,
project_id,
user_email,
total_bytes_processed,
query
FROM
`region-us`.INFORMATION_SCHEMA.JOBS_BY_USER
SELECT * FROM `region-us`.INFORMATION_SCHEMA.JOBS_BY_PROJECT
SELECT * FROM `region-us`.INFORMATION_SCHEMA.JOBS_BY_ORGANIZATION
Working Example
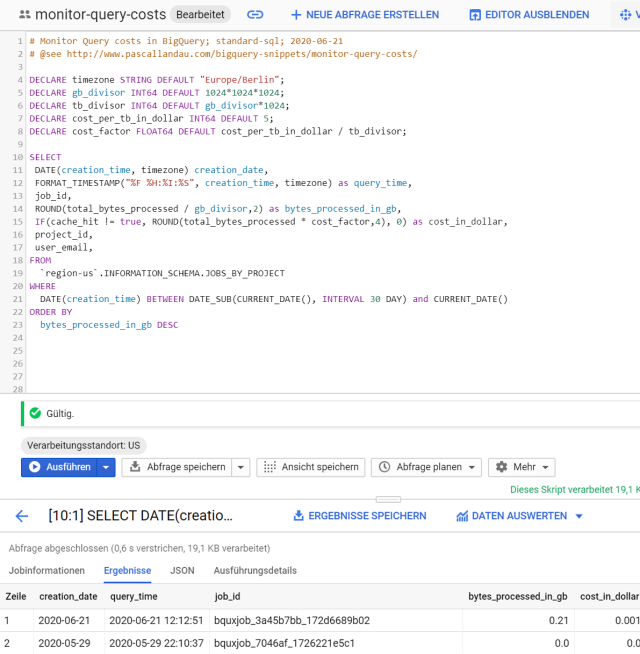
# Monitor Query costs in BigQuery; standard-sql; 2020-06-21
# @see http://www.pascallandau.com/bigquery-snippets/monitor-query-costs/
DECLARE timezone STRING DEFAULT "Europe/Berlin";
DECLARE gb_divisor INT64 DEFAULT 1024*1024*1024;
DECLARE tb_divisor INT64 DEFAULT gb_divisor*1024;
DECLARE cost_per_tb_in_dollar INT64 DEFAULT 5;
DECLARE cost_factor FLOAT64 DEFAULT cost_per_tb_in_dollar / tb_divisor;
SELECT
DATE(creation_time, timezone) creation_date,
FORMAT_TIMESTAMP("%F %H:%I:%S", creation_time, timezone) as query_time,
job_id,
ROUND(total_bytes_processed / gb_divisor,2) as bytes_processed_in_gb,
IF(cache_hit != true, ROUND(total_bytes_processed * cost_factor,4), 0) as cost_in_dollar,
project_id,
user_email,
FROM
`region-us`.INFORMATION_SCHEMA.JOBS_BY_USER
WHERE
DATE(creation_time) BETWEEN DATE_SUB(CURRENT_DATE(), INTERVAL 30 DAY) and CURRENT_DATE()
ORDER BY
bytes_processed_in_gb DESC
- This query will select the most interesting fields in terms of cost monitoring from the
INFORMATION_SCHEMA.JOBS_BY_USER view for all jobs that have been run in region US in the currently selected project. - The
cost_in_dollar is estimated by calculating the total_bytes_processed in Terabyte and multiplying the result with $5.00 (which corresponds to the cost as of today 2020-06-22). Also, we only take those costs into account if the query was not answered from the cache (see the cache_hit != true condition). - The
creation_time is converted to our local timezone. - The results are restricted to the past 30 days by using the
WHERE clause to filter on the partition column creation_time. - Feel free to replace
JOBS_BY_PROJECT with JOBS_BY_USER or JOBS_BY_ORGANIZATION
Run on BigQuery
Open in BigQuery UI
Notes
While playing around with the INFORMATION_SCHEMA views, I've hit a couple of gotchas:
- The different views require different permissions.
- The views are regionalized, i.e., we must prefix the region (see
region-us in the view specification) and must run the job in that region (e.g. from the BigQuery UI via More > Query Settings > Processing location) - It is not possible to mix multiple regions in the query, because a query with processing location
US can only access resources in location US. Though it would be very helpful for organizations that actively use different locations, something like this is not possible:
SELECT * FROM
(SELECT * `region-us`.INFORMATION_SCHEMA.JOBS_BY_ORGANIZATION)
UNION ALL
(SELECT * `region-eu`.INFORMATION_SCHEMA.JOBS_BY_ORGANIZATION)
- Data is currently only kept for the past 180 days.
- The
JOBS_BY_USER view seems to "match" the user based on the email address. My user email adress is a @googlemail.com address; in the user column, it is stored as @gmail.com. Thus, I get no results when using JOBS_BY_USER. JOBS_BY_USER and JOBS_BY_PROJECT will use the currently selected project by default. A different project (e.g., other-project) can be specified via:
SELECT * FROM `other-project.region-us`.INFORMATION_SCHEMA.JOBS_BY_PROJECT
- The full
query is not available for JOBS_BY_ORGANIZATION.
Due to technical constraints, this article is capped at 40000 characters. Read the full content at BigQuery: Monitor Query Costs via INFORMATION_SCHEMA

