What makes data relevant to people is its interconnections. What makes data difficult, when it’s in a typical database, is its lack of interconnections.
Interconnections expand on the value of the information that may be extrapolated from disparate, seemingly unrelated, data. Questions regarding clusters or patterns are more easily solved by, and dramatically more apparent in, graph databases. When you store and query data using a graph database such as Neo4j, you can quickly surface critical information, and possibly expose potentially catastrophic issues hidden within complex datasets.
LISTEN NOW
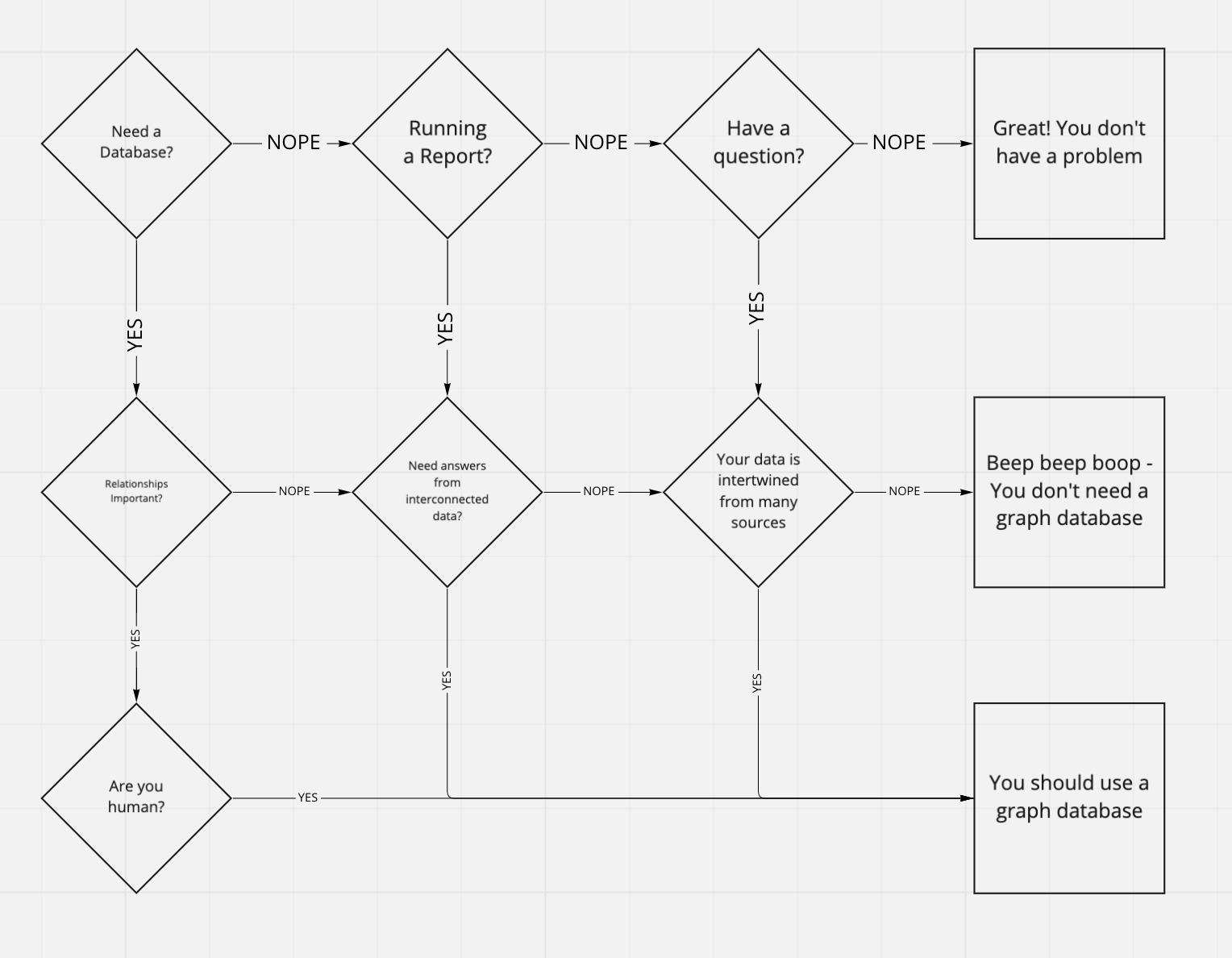
A Good fit for Graph Databases
FOR MORE
Neo4j AuraDB: The Right Graph Database, Not a Graph Add-on
Start Simple
As with any database, your basic questions should always be answerable with little effort. Aggregating information such as totals, averages, max, or min of records or searching and retrieving specific records by particular property values.
To illustrate what this would look like in a graph database, let’s say we have a giant list of users and want to find everyone whose name starts with "adam." The graph data model for this would be a single label type:

User records would have nothing connecting them to any other user or other piece of data, so the entire list can be visualized as a large collection of independent nodes:

The answer to a query for "Adam" would be a subset:
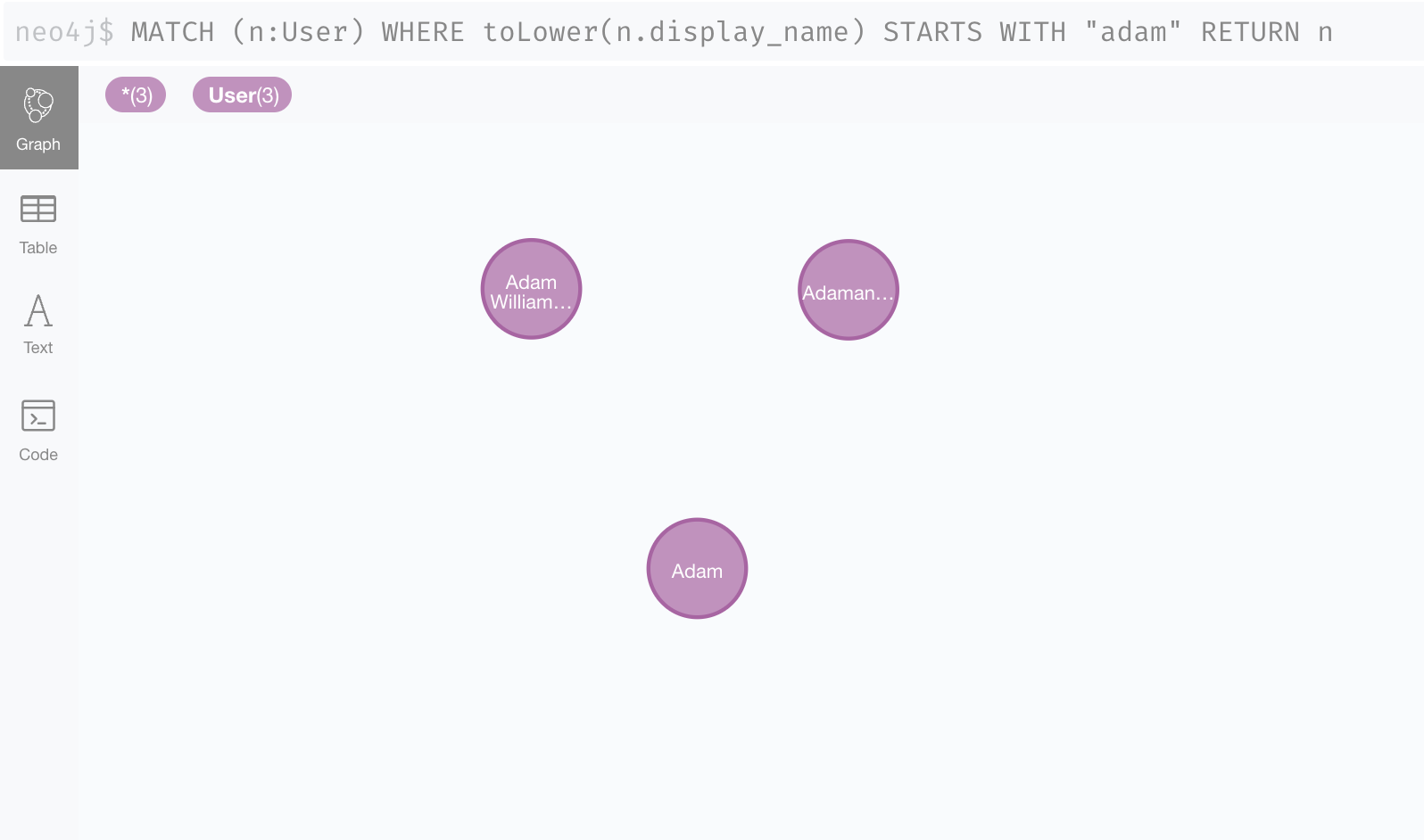
In fact, all similar queries such as ‘who are all the users created after a certain date’ or ‘which users live in a particular city’ would all return such a subset from the total user collection.
As you can see, these types of questions are easily answered by graph databases, but this problem-answer set is not at all a graph-like problem. There are no apparent relationships or associations between users to surface other interesting insights.
Data in Relationships
Now, let’s say a graph database powers an online forum where users are able to post questions. These questions in turn can be answered by other users. An updated data model would look like:

Now, not only is there now more data in the form of additional nodes, but there is data in-between them. For example: What is the number of degrees that separate most users? What subset of users only answers questions when no other answers exist?
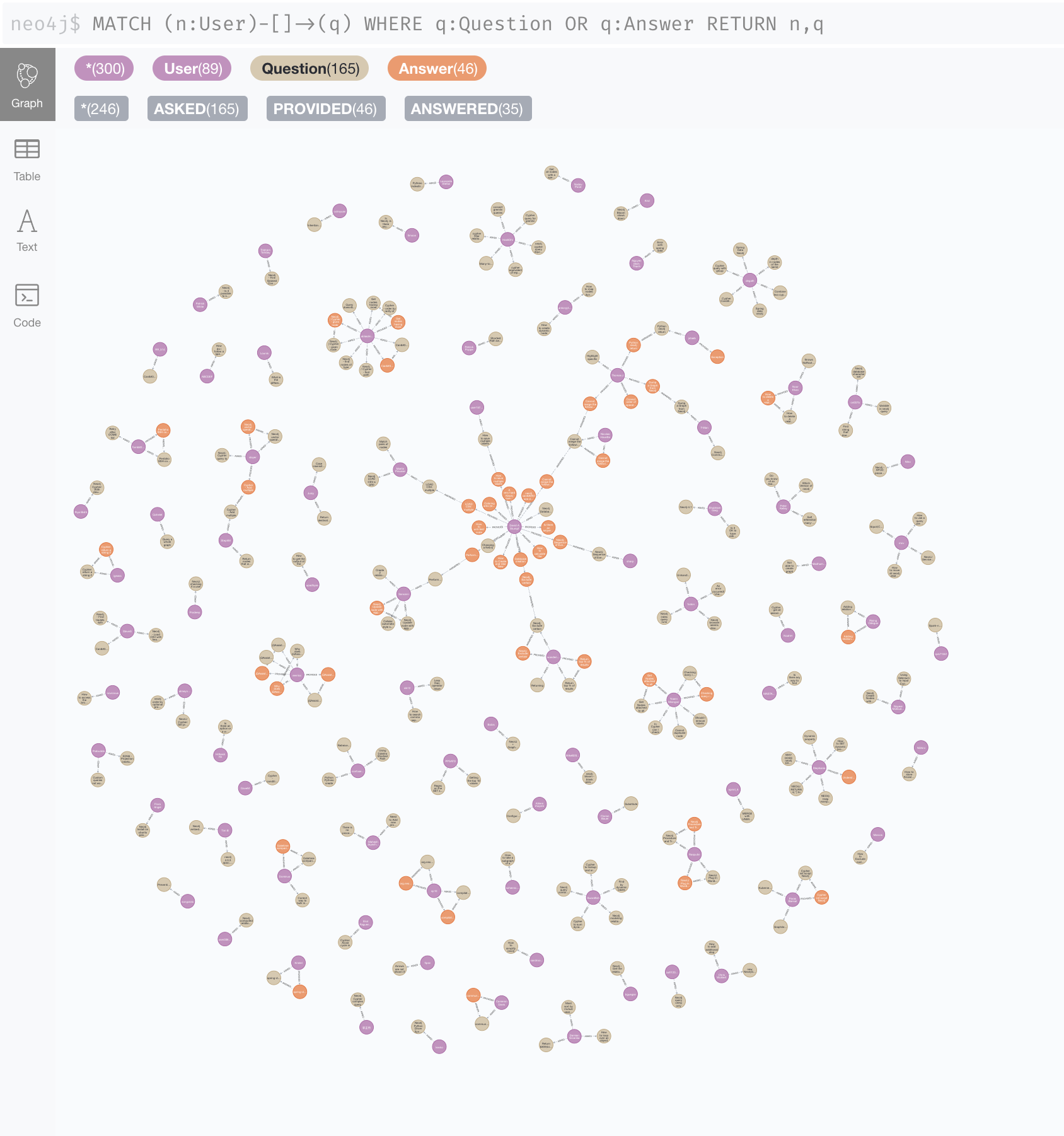
Notice the entire graph of the above data model manifests as a collection of interspersed clusters of nodes, like pock marks on a potato. Their clustered arrangement, in little, separate groups, may give you the impression that most of the questions to which these nodes refer, are not at all related to one another. In reality this is unlikely as users are probably asking questions around a specific context. On a car maintenance forum, for example, users would probably be asking for tips on how to maintain or modify particular car or components types.
So we’re missing something that better ties or categorizes questions together. One way to connect them would be to tag keywords to each question. Lets add a new Node type labeled ‘Tag’, with a keyword being a unique name property.
With this addition, the updated data model becomes:
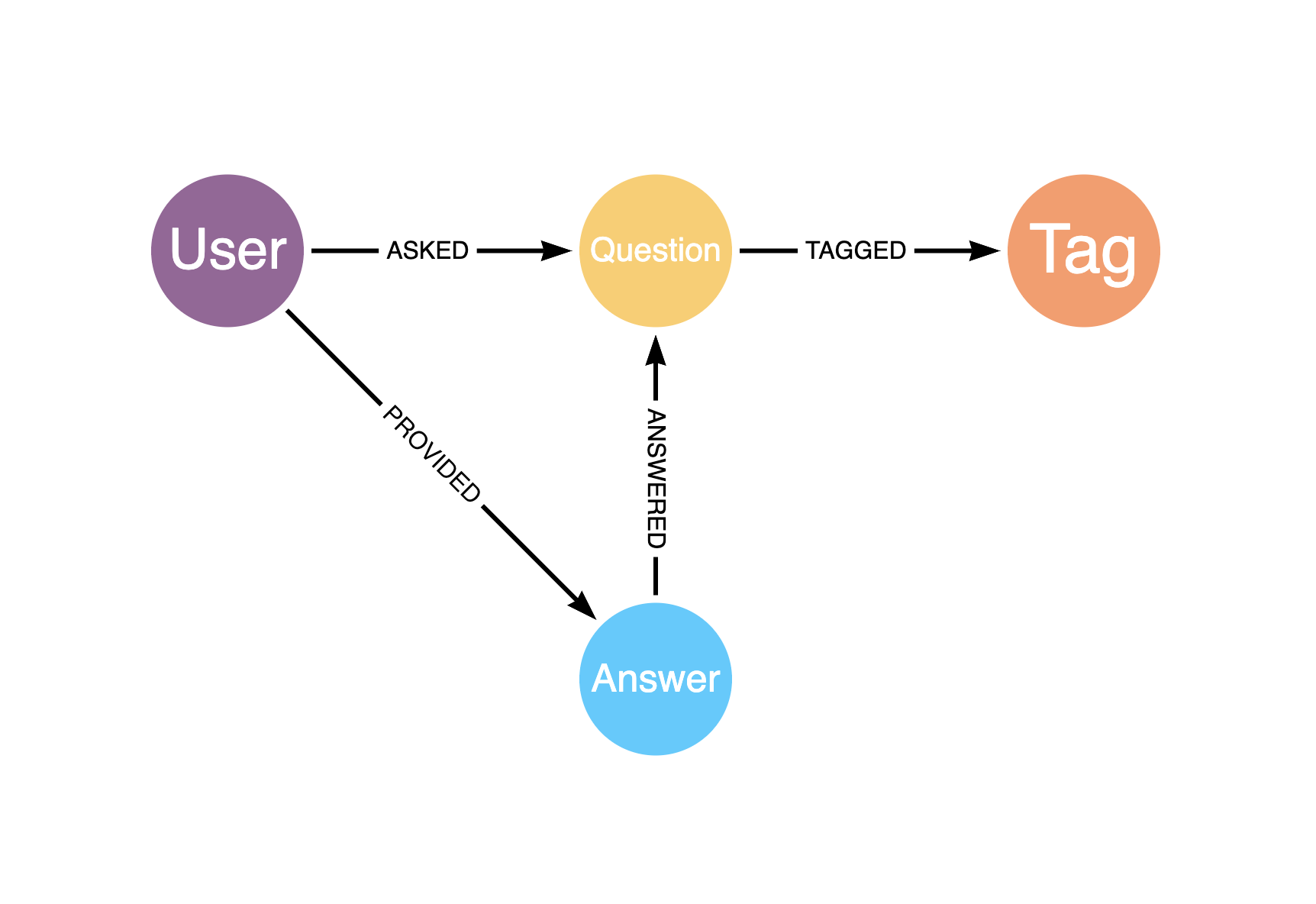
Note there are a few other ways we could have made these keyword associations within Neo4j, but this is the clearest option – a fact which will become more apparent in a moment. For more information on other options and best practices regarding node labeling, see this Medium article by David Allen.
Once we include these tags into our database, we get a much richer network where are all the data nodes are now interlinked:

Graph data like this is simultaneously beautiful and intimidating to look at. Initially you may not know where to start, but this is where graph database visualizations can be incredibly convenient. Just by looking at this visualized graph we can instantly see that most of the questions represented revolve around a tag called ‘cypher’, which is an open sourced query language for graph dbs.
Cypher uses ASCII-art styled syntax that makes it easy to form pattern related queries and run CRUD operations. Knowing how to write Cypher queries will help you get more out of graph db but is not strictly necessary with the availability of interactive visualization tools like Neo4j Bloom.
With Bloom you can quickly explore a dataset by zeroing in on particular nodes, relationships, or patterns to do things like finding clusters or outliers of data, or shortest paths between sets of nodes.
What Next
There are, and always will be, genuine purposes for relational and NoSQL databases – both the tools and the data constructs. But graph database managers such as Neo4j are extremely powerful tools for storing and querying loosely or deeply interconnected information. Not only can they support simple queries from tabular data, but they can also answer important questions that surface from the relationships between that data.
If you’re in software development you’ve probably noticed the data model discussed looks a lot like Stack Overflow, and it is! The actual Stack Overflow data includes nodes for comments, with additional relationships from them to users and questions.
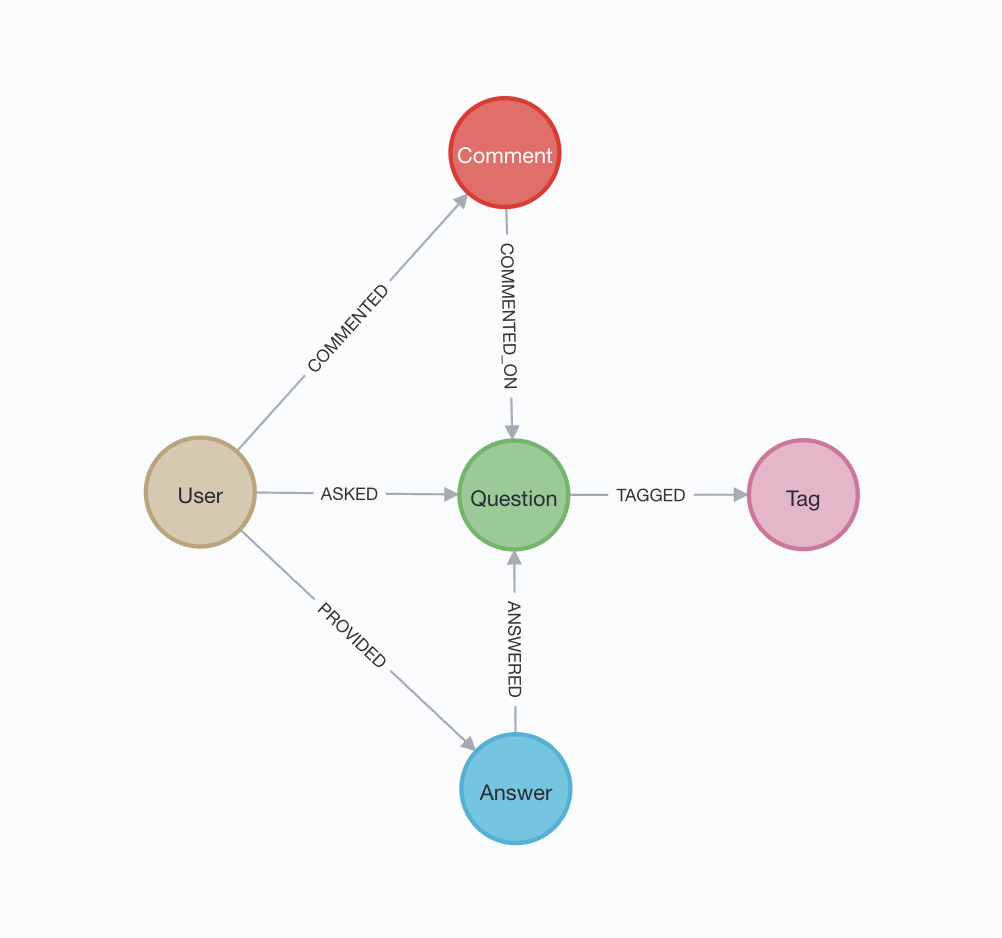
To dive deeper into SO’s data as a graph, see this article on Neo4j’s Stack Overflow sandbox for instructions on spinning up your own free instance. Advanced APOC and Data Science Algorithm libraries are also introduced, which add utilities to import or integrate data from other databases, leverage graph algorithms like Page Ranking, and ability to train or utilize ML models.
Now that your eyes are open to some of the capabilities and possibilities with using graph databases, a world of new insights awaits you.
READ MORE

