This article contains a quick guide on how to design a AXI4 stream interface in Vitis HLS, a description of what is Vitis HLS and why you might prefer to use it for your FPGA designs.
Introduction
Designing external IP cores in stream interfaces is very common in many applications where there is a requirement of a stream of data. This could be image and video processing, or many RF applications such as FDM (frequency division multiplexing) and OFDM (Orthogonal Frequency Division Multiplexing).
There are many ways you could do this, but in this article, I will share the design of an AXI4 stream interface in Vitis HLS. I used this as a hardware accelerator IP on the MiniZed FPGA development board from Avnet. This approach is great for developers who may not be familiar with RTL design, or are looking for ways to optimize their stream interface designs.
What is Vitis HLS?
Vitis is a high-level synthesis tool (HLS), created by Xilinx. It allows developers to synthesize C, C++ and OpenCL functions into an FPGA logic fabric. Vitis HLS is used for developing RTL IP for Xilinx devices using Vivado Design suite. If you want to learn more about Vitis HLS, I suggest reading the resources provided by Xilinx.
The Vitis HLS tool automates much of the code implemented in C/C++ to achieve low latency and high throughput.
Here is the Vitis HLS design flow:
- Compile, simulate and debug C/C++ algorithm
- View reports to analyze and optimize design
- Synthesize the C/C++ algorithm into RTL design
- Verify RTL design using RTL co-simulation
- Package the RTL implementation into a compiled object file, or export as RTL IP
Why Use Vitis HLS?
You might be wondering why to use Vitis HLS if you can write a custom RTL algorithm in verilog/VHDL.
Well, the answer is simple: it's easier to write C/C++ functions. If you go with the RTL development workflow with verilog/VHDL, then first you would have to understand the algorithm, then write the RTL design and simulation test-bench. If it works, then you would have to write an AXI protocol wrapper along with the test-bench.
This approach takes time in each iterative step. Plus, if your simulation works well, then it does not necessarily mean that it will work the same way on your hardware (FPGA).
If you go with the Vitis HLS workflow, you would need to write the algorithm in C/C++, run it through the simulation and co-simulation in the same software, and analyze/optimize the design if you need to.
Next, you would just need to add PRAGMA for your algorithm for AXI protocol and other I/O if necessary. Finally, if you are happy with the design, you can export the synthesized RTL IP to be used in Vivado.
With Vitis HLS, you can also set target clock frequency during synthesis and Vitis HLS will optimize your algorithm to ensure it achieves timing.
This type of workflow will save you a lot of time debugging and optimizing your design by using a single application. This is why engineers are starting to modify their FPGA design services to include Vitis HLS as an option for algorithm design, and why you might want to consider adding it to your expertise.
Using the Code
Here’s an example experiment below that explains how to design an AXI4 stream interface in Vitis HLS. The target FPGA is the MiniZed FPGA development board from Avnet.
First, we create the Stream_generate_mix.cpp file:
#include "stream_generate_mix.h"
void fnv_hash(unsigned int*x,unsigned int *y,unsigned int *z){
*z = (*x * 0x01000193) ^ *y;
}
void stream_mixin(
hls::stream<data_t> &mixin,
uint32_t *temp_genmixin)
{
#pragma HLS INLINE off
data_t mixin_buff;
unsigned int mixin_count = 0;
do{
#pragma HLS PIPELINE
mixin_buff = mixin.read();
temp_genmixin[mixin_count] = mixin_buff.data;
mixin_count++;
if(mixin_count == 32){
mixin_count = 0;
}
}while(!mixin_buff.last);
}
void stream_dagin(
hls::stream<data_t> &dagin,
uint32_t *temp_dagin)
{
#pragma HLS INLINE off
data_t dagin_buff;
uint32_t dagin_array[32];
unsigned int dagin_count = 0;
do{
#pragma HLS PIPELINE
dagin_buff = dagin.read();
temp_dagin[dagin_count] = dagin_buff.data;
dagin_count++;
if(dagin_count == 32){
dagin_count = 0;
}
}while(!dagin_buff.last);
}
void generate_mix(uint32_t *mixin, uint32_t *dagin, uint32_t *mixout)
{
generate_mix_loop:for(unsigned int i = 0; i < 32; i++){
#pragma HLS UNROLL
fnv_hash(mixin, dagin, mixout);
}
}
void stream_mixout(
uint32_t *mixout_array,
hls::stream<data_t> &mixout)
{
data_t mixout_buff;
unsigned int mixout_count = 0;
mixout_loop:for(unsigned int i = 0; i < 32; i++){
mixout_buff.data = mixout_array[i];
if(i == 31){
mixout_buff.last = 1;
}
else{
mixout_buff.last = 0;
}
mixout.write(mixout_buff);
}
}
void stream_generate_mix(
hls::stream<data_t> &mixin,
hls::stream<data_t> &dagin,
hls::stream<data_t> &mixout)
{
#pragma HLS INTERFACE mode=ap_ctrl_none port=return
#pragma HLS DATAFLOW
#pragma HLS INTERFACE mode=axis register_mode=both port=mixout register
#pragma HLS INTERFACE mode=axis register_mode=both port=dagin register
#pragma HLS INTERFACE mode=axis register_mode=both port=mixin register
uint32_t mixin_array[32];
uint32_t dagin_array[32];
uint32_t mixout_array[32];
stream_mixin(mixin, mixin_array); stream_dagin(dagin, dagin_array); generate_mix(mixin_array, dagin_array, mixout_array); stream_mixout(mixout_array, mixout); }
Generate_mix is the function we want to accelerate.
Mixin and dagin are inputs to this function. Mixout is the output of this function.
Both inputs and outputs are 32-bit size. Here the PRAGMA HLS UNROLL will unroll the for loop to achieve faster calculation.
void generate_mix(uint32_t *mixin, uint32_t *dagin, uint32_t *mixout)
{
generate_mix_loop:for(unsigned int i = 0; i < 32; i++){
#pragma HLS UNROLL
mixout[i] = fnv_hash(mixin[i], dagin[i]);
}
}
Stream_mixin and stream_dagin are 2 separate functions. These two are implemented as AXI4 stream data in functions, which takes input data from the stream interface.
The mixin stream input data stores data into mixin_array. Stream_dagin input takes data and stores it in the dagin_array. When the data is received, the generate_mix function does the computation and stores the data in mixout_array.
Once the output data is ready, the stream_mixout function sends data from mixout_array to downstream modules via AXI-4 stream interface.
Adding the AXI interface is simple and efficient in Vitis HLS, you can do so by using PRAGMA.
Stream_generate_mix function is the top-module, to achieve max throughput DATAFLOW, PRAGMA is added to allow each function to work in parallel.
Now we add the testbench:
#include "stream_generate_mix.h"
int main(){
hls::stream<data_t> mixin;
hls::stream<data_t> dagin;
hls::stream<data_t> mixout;
data_t mixin_stream;
data_t dagin_stream;
data_t dataout;
mixin_stream.data = 0xa8184851; mixin_stream.last = 0; mixin.write(mixin_stream);
mixin_stream.data = 0x154f4b4f; mixin_stream.last = 0; mixin.write(mixin_stream);
mixin_stream.data = 0x19975771; mixin_stream.last = 0; mixin.write(mixin_stream);
mixin_stream.data = 0x7cef52db; mixin_stream.last = 0; mixin.write(mixin_stream);
mixin_stream.data = 0x5102240a; mixin_stream.last = 0; mixin.write(mixin_stream);
mixin_stream.data = 0x42dddb99; mixin_stream.last = 0; mixin.write(mixin_stream);
mixin_stream.data = 0xb215e865; mixin_stream.last = 0; mixin.write(mixin_stream);
mixin_stream.data = 0x4eca0185; mixin_stream.last = 0; mixin.write(mixin_stream);
mixin_stream.data = 0xc1c2dfc9; mixin_stream.last = 0; mixin.write(mixin_stream);
mixin_stream.data = 0x6ece31eb; mixin_stream.last = 0; mixin.write(mixin_stream);
mixin_stream.data = 0x3c6209d0; mixin_stream.last = 0; mixin.write(mixin_stream);
mixin_stream.data = 0xbbc62b1d; mixin_stream.last = 0; mixin.write(mixin_stream);
mixin_stream.data = 0x74d075ae; mixin_stream.last = 0; mixin.write(mixin_stream);
mixin_stream.data = 0xff1ffd18; mixin_stream.last = 0; mixin.write(mixin_stream);
mixin_stream.data = 0x204b4b69; mixin_stream.last = 0; mixin.write(mixin_stream);
mixin_stream.data = 0x8c93affd; mixin_stream.last = 0; mixin.write(mixin_stream);
mixin_stream.data = 0xa8184851; mixin_stream.last = 0; mixin.write(mixin_stream);
mixin_stream.data = 0x154f4b4f; mixin_stream.last = 0; mixin.write(mixin_stream);
mixin_stream.data = 0x19975771; mixin_stream.last = 0; mixin.write(mixin_stream);
mixin_stream.data = 0x7cef52db; mixin_stream.last = 0; mixin.write(mixin_stream);
mixin_stream.data = 0x5102240a; mixin_stream.last = 0; mixin.write(mixin_stream);
mixin_stream.data = 0x42dddb99; mixin_stream.last = 0; mixin.write(mixin_stream);
mixin_stream.data = 0xb215e865; mixin_stream.last = 0; mixin.write(mixin_stream);
mixin_stream.data = 0x4eca0185; mixin_stream.last = 0; mixin.write(mixin_stream);
mixin_stream.data = 0xc1c2dfc9; mixin_stream.last = 0; mixin.write(mixin_stream);
mixin_stream.data = 0x6ece31eb; mixin_stream.last = 0; mixin.write(mixin_stream);
mixin_stream.data = 0x3c6209d0; mixin_stream.last = 0; mixin.write(mixin_stream);
mixin_stream.data = 0xbbc62b1d; mixin_stream.last = 0; mixin.write(mixin_stream);
mixin_stream.data = 0x74d075ae; mixin_stream.last = 0; mixin.write(mixin_stream);
mixin_stream.data = 0xff1ffd18; mixin_stream.last = 0; mixin.write(mixin_stream);
mixin_stream.data = 0x204b4b69; mixin_stream.last = 0; mixin.write(mixin_stream);
mixin_stream.data = 0x8c93affd; mixin_stream.last = 1; mixin.write(mixin_stream);
dagin_stream.data = 0x2d78ca64; dagin_stream.last = 0; dagin.write(dagin_stream);
dagin_stream.data = 0x7013973a; dagin_stream.last = 0; dagin.write(dagin_stream);
dagin_stream.data = 0x2ba38005; dagin_stream.last = 0; dagin.write(dagin_stream);
dagin_stream.data = 0xd65b0e87; dagin_stream.last = 0; dagin.write(dagin_stream);
dagin_stream.data = 0x4ae28b63; dagin_stream.last = 0; dagin.write(dagin_stream);
dagin_stream.data = 0x45562bcf; dagin_stream.last = 0; dagin.write(dagin_stream);
dagin_stream.data = 0x3f0359e2; dagin_stream.last = 0; dagin.write(dagin_stream);
dagin_stream.data = 0xb13a0b2e; dagin_stream.last = 0; dagin.write(dagin_stream);
dagin_stream.data = 0xfccc25ea; dagin_stream.last = 0; dagin.write(dagin_stream);
dagin_stream.data = 0x0f28bfa0; dagin_stream.last = 0; dagin.write(dagin_stream);
dagin_stream.data = 0x08f15dab; dagin_stream.last = 0; dagin.write(dagin_stream);
dagin_stream.data = 0xe2432196; dagin_stream.last = 0; dagin.write(dagin_stream);
dagin_stream.data = 0x6c2a1198; dagin_stream.last = 0; dagin.write(dagin_stream);
dagin_stream.data = 0x310d15a5; dagin_stream.last = 0; dagin.write(dagin_stream);
dagin_stream.data = 0x81abef7b; dagin_stream.last = 0; dagin.write(dagin_stream);
dagin_stream.data = 0x515dca4b; dagin_stream.last = 0; dagin.write(dagin_stream);
dagin_stream.data = 0x858a4a1a; dagin_stream.last = 0; dagin.write(dagin_stream);
dagin_stream.data = 0x12f6ccc2; dagin_stream.last = 0; dagin.write(dagin_stream);
dagin_stream.data = 0x476434c0; dagin_stream.last = 0; dagin.write(dagin_stream);
dagin_stream.data = 0xbf7cd5b4; dagin_stream.last = 0; dagin.write(dagin_stream);
dagin_stream.data = 0xc3430958; dagin_stream.last = 0; dagin.write(dagin_stream);
dagin_stream.data = 0xc7129b62; dagin_stream.last = 0; dagin.write(dagin_stream);
dagin_stream.data = 0x46e72eb9; dagin_stream.last = 0; dagin.write(dagin_stream);
dagin_stream.data = 0x2f931315; dagin_stream.last = 0; dagin.write(dagin_stream);
dagin_stream.data = 0x98bf46c7; dagin_stream.last = 0; dagin.write(dagin_stream);
dagin_stream.data = 0x6fc53dca; dagin_stream.last = 0; dagin.write(dagin_stream);
dagin_stream.data = 0x735be2c2; dagin_stream.last = 0; dagin.write(dagin_stream);
dagin_stream.data = 0x7d6eba54; dagin_stream.last = 0; dagin.write(dagin_stream);
dagin_stream.data = 0xc68ae2a4; dagin_stream.last = 0; dagin.write(dagin_stream);
dagin_stream.data = 0xbedc3876; dagin_stream.last = 0; dagin.write(dagin_stream);
dagin_stream.data = 0x94d4ad9d; dagin_stream.last = 0; dagin.write(dagin_stream);
dagin_stream.data = 0xeac2ff68; dagin_stream.last = 1; dagin.write(dagin_stream);
stream_generate_mix(mixin, dagin, mixout);
for(unsigned int i = 0; i < 32; i++){
dataout = mixout.read();
printf("mixout[%d]:%x \r",i,dataout.data);
}
}
Finally, we add the header file:
#include <iostream>
#include "stdio.h"
#include "string.h"
#include "hls_stream.h"
#include "ap_axi_sdata.h"
#include "ap_int.h"
typedef ap_axis<32,0,0,1> data_t;
void stream_generate_mix(
hls::stream<data_t> &mixin,
hls::stream<data_t> &dagin,
hls::stream<data_t> &mixout);
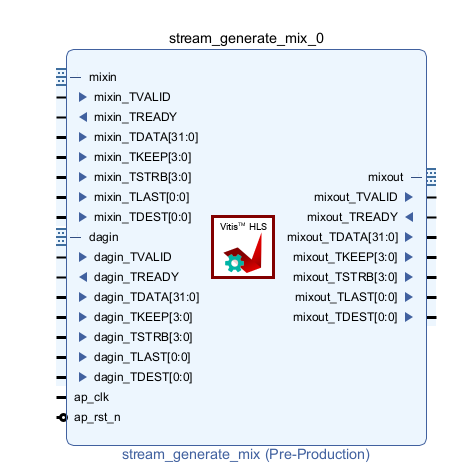
Once the IP is generated and exported, it needs to be added to Vivado block design. Here is an image of the stream_generate_mix IP:
Here is Device utilisation:

I hope this helps you understand how AXI-4 stream interface is implemented in Vitis HLS with lower latency and higher throughput.
History
- 10th June, 2022: Initial version

