
Introduction
In most practical applications, deep learning AI models must be optimized to efficiently use computational resources so they can achieve fast performance. OpenVINO offers several tools for making a model run faster and use less memory: Model Optimizer, Post-training Optimization Tool (POT), and Neural Network Compression Framework (NNCF).
What Does Each Tool Do?
Each tool provides a different set of features for compressing a model and making it run faster on target hardware.
- Model Optimizer converts models from a wide range of frameworks to the OpenVINO format or Intermediate Representation (IR), quickly making the model run more efficiently on Intel hardware. The conversion process optimizes the network topology for performance, space usage, and reduces computational requirements on the target accelerator. Model Optimizer does not impact model accuracy.
- POT allows you to further accelerate the inference speed of your IR model by applying post-training quantization. This allows your model to run faster and use less memory. In some instances, it causes a slight reduction in accuracy.
- NNCF integrates with PyTorch and TensorFlow to quantize and compress your model during or after training to increase model speed while maintaining accuracy and keeping it in the original framework’s format. It can be used for two things: (1) quantization-aware training and other compression techniques in a PyTorch or TensorFlow training pipeline, and (2) post-training quantization of PyTorch or TensorFlow models. NNCF may be easier to use for post-training quantization than POT if you already have a model and training pipeline set up in PyTorch or TensorFlow.
Note: If you don’t have a specific model or framework in mind, you can use OpenVINO Training Extensions (OTE) to train and optimize one of several Intel-provided models on your dataset all in one workflow within OpenVINO. See the OTE Developer Guide for more information.
When Should I Use Model Optimizer, POT, and NNCF?
The best tool to use depends on the model you’re starting with, how much optimization you need, and whether you want to apply optimizations during or after training a model.
- Use Model Optimizer if you have a trained or off-the-shelf model from another framework and want to run it with basic optimizations offered by OpenVINO. Simply convert your model to the OpenVINO format or IR file to improve its performance on Intel hardware with the inference engine or OpenVINO Runtime.
- Use POT if you have a trained or have an off-the-shelf model and want to easily improve its speed beyond the basic optimizations of Model Optimizer. Convert your model to OpenVINO (IR) format, then use POT to further increase its inference speed by performing post-training quantization with a representative dataset. It’s important to note that validation is needed as we’ve changed the model to point where any critical tasks can be impacted when in production.
- Use NNCF if you already have a training pipeline set up in PyTorch or TensorFlow and want to optimize your model for Intel hardware. You can perform post-training quantization on your trained PyTorch, TensorFlow, or ONNX model to easily improve speed without needing to re-run training. If the resulting accuracy isn’t high enough, use NNCF to add compression algorithms (e.g., with quantization-aware training) to your training pipeline to improve the optimized model’s accuracy. Then, use Model Optimizer to convert the quantized model to IR format to run it with the OpenVINO runtime.
The diagram below shows two common use cases and workflows where POT and NNCF are utilized. In both workflows, Model Optimizer is used to convert the model to OpenVINO (IR) format.
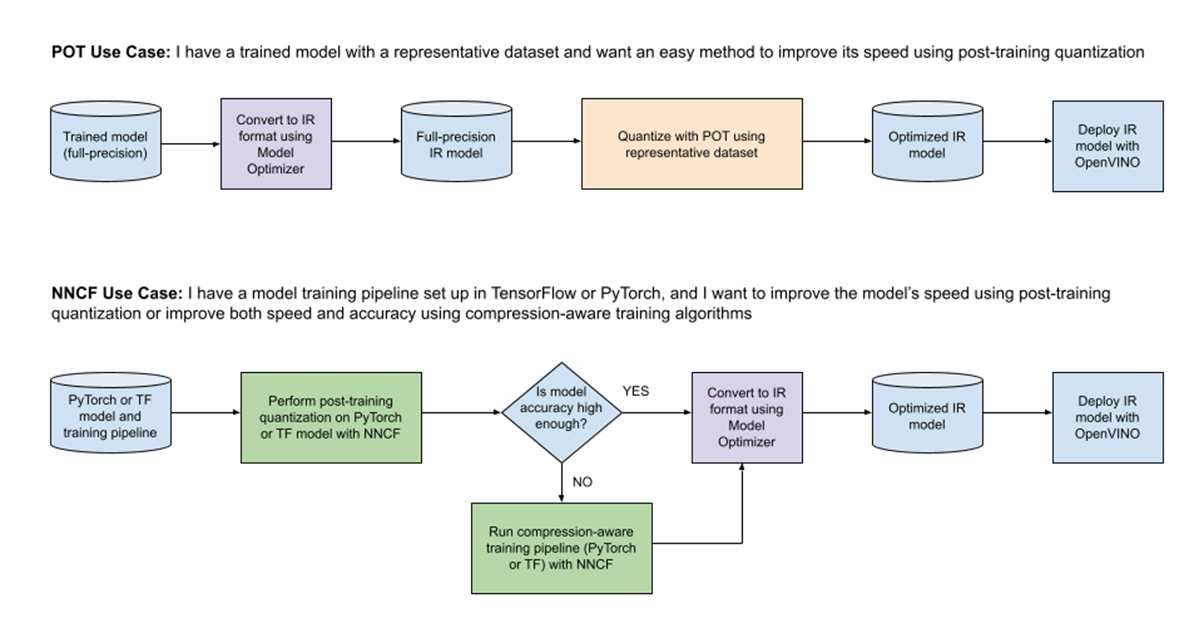
Use Case Table
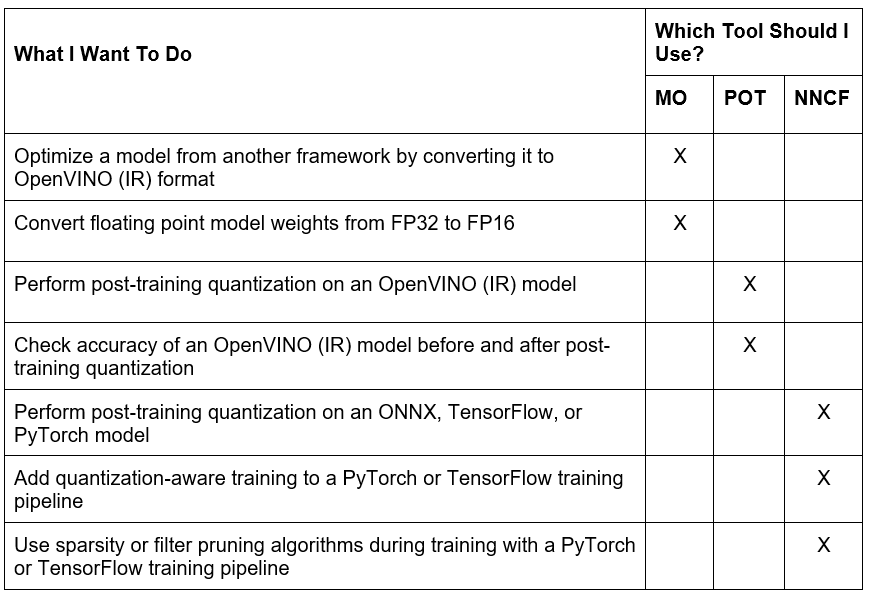
The following table lists other common use cases for model optimization and indicates whether Model Optimizer, POT, or NNCF is recommended for each case.
Where to Go Next
To learn more, check out these links and videos:
- POT: Get started by following this 10-minute example showing how much optimization POT can improve your model’s speed and memory footprint.
- NNCF: Visit the official GitHub repository for detailed documentation and usage examples.
- Find the right solutions in our notebooks demonstrating quantization
Frequently Asked Questions
What is quantization?
Quantization is the process of converting the weights and activation values in a neural network from a high-precision format (such as 32-bit floating point) to a lower-precision format (such as 8-bit integer). Quantization allows neural networks to run two to four times faster compared to networks that have been optimized by Model Optimizer. It also reduces the space required to save the network on disk.
What is quantization-aware training and why would I use it?
Quantization-aware training inserts nodes into the neural network during training that simulate the effect of lower precision. This allows the training algorithm to consider quantization errors as part of the overall training loss that gets minimized during training. The network is then able to achieve better accuracy when quantized.
What is the difference between quantization with NNCF and POT?
POT takes as input a fully trained model and a representative dataset that you supply and uses these to quantize both the weights and activations to a lower-precision format. The advantage here is that the model doesn’t need to be retrained, and you don’t need a training pipeline or deep learning frameworks installed. In contrast, NNCF performs quantization-aware training, requiring you to have a training pipeline and training framework (TensorFlow or PyTorch) installed. NNCF also supports some additional compression algorithms not found in POT (shown below). Both result in an optimized, quantized model that will run faster and take less memory than an unquantized model. The accuracy of a model that has been quantized using post-training quantization in POT will likely be somewhat lower than a model trained with quantization-aware training through NNCF.
Does NNCF support post-training quantization?
Yes, NNCF can run post-training quantization on a model in ONNX, PyTorch, or TensorFlow format. This allows you to quickly improve the speed of your model without leaving your TensorFlow or PyTorch development environment. (If your model is already in OpenVINO (IR) format, then POT is recommended for post-training quantization). An example notebook showing how to perform post-training quantization with NNCF is available in the OpenVINO Toolkit repository on GitHub.
Does POT support quantization-aware training?
No, POT only provides tools for quantizing the model post-training. If you’d like to use quantization-aware training, look into NNCF.
Does POT allow you to tradeoff between speed and accuracy when quantizing a model?
Yes, POT offers an accuracy-aware quantization algorithm where you can specify the maximum range of acceptable accuracy drop. When needed, it will revert some layers from 8-bit precision back to the original precision (which can be either 16 or 32 bit). This will reduce the model’s speed but minimize the drop in accuracy. See the documentation on Accuracy Aware Quantization for information on how to configure accuracy parameters and integrate it into a basic quantization workflow.
Do I need an OpenVINO (IR) model to use POT?
Yes, POT only works on models that have been converted to OpenVINO (IR) format. See the OpenVINO Model Optimizer tool documentation for instructions on how to convert your model to OpenVINO format.
Do I need to install TensorFlow or PyTorch to use NNCF?
Yes, NNCF is intended to be used in conjunction with TensorFlow or PyTorch. To use NNCF, you will need to install and set up a training pipeline with either framework. The NNCF optimizations can then be added to the training pipeline as shown in the usage examples for PyTorch and TensorFlow.
What are the different compression algorithms in NNCF?
The table below (from the NNCF GitHub repository) shows the compression algorithms available in NNCF and whether they are supported with PyTorch, TensorFlow, or both.
╔═════════════════════════════╦══════════════════╦═════════════════╗
║Compression Algorithm ║ PyTorch ║ TensorsFlow ║
╠═════════════════════════════╬══════════════════╬═════════════════╣
║ Quantization ║ Supported ║ Supported ║
║ Mixed-Precision Quantization║ Supported ║ Not Supported ║
║ Binarization ║ Supported ║ Not Supported ║
║ Sparsity ║ Supported ║ Supported ║
║ Filter pruning ║ Supported ║ Supported ║
╚═════════════════════════════╩══════════════════╩═════════════════╝
How do I install Model Optimizer, POT, and NNCF?
Please see the following links for installation instructions for each tool:
Do I need a GPU to use Model Optimizer, POT, and NNCF?
- A GPU is not required to use Model Optimizer. All conversions are performed on the CPU.
- A GPU is not required to use POT. Post-training quantization runs on the CPU and quickly quantizes a model (depending on the size of the model and dataset). The optimized model can be configured to run on a GPU, but the optimization itself only requires a CPU.
- If your PyTorch or TensorFlow training pipeline is configured to run on a GPU, then a GPU is required to run the NNCF compression algorithms during training. If your training pipeline is configured to run on a CPU, then a GPU is not needed, but training typically takes longer.
Which tool should I try first if I want to optimize my model?
First, start with Model Optimizer to convert your model to OpenVINO (IR) format, which applies baseline optimizations to improve model performance. If you want even better performance, you can quantize your model with NNCF or POT. The choice between NNCF and POT depends on your model and training pipeline:
- If you have a model and training pipeline set up in PyTorch or TensorFlow, then use NNCF to optimize the model. Perform post-training quantization on your model with NNCF and then compare performance to the original model. If the accuracy isn’t high enough, add quantization-aware training to your pipeline with NNCF. This allows you to improve the accuracy of your quantized model while still achieving a similar boost in inference speed.
- If you already have a model trained for your application but don’t have a training pipeline set up in PyTorch or TensorFlow, use POT for optimization. After converting your model to OpenVINO (IR) format with Model Optimizer, use POT to perform post-training quantization with a representative dataset. It allows you to boost your model’s speed and evaluate its accuracy after quantization.
Can I train a model using OpenVINO?
OpenVINO is not intended to be a general-purpose neural network training framework. That said, OpenVINO Training Extensions (OTE) can be used to train one of several Intel-provided models with your own dataset, and it supports optimizations using built-in features from POT and NNCF. For more information about OTE and how to use it, please read the OpenVINO Training Extensions Developer Guide for more information about OTE and how to use it.
Where do I find more information about Model Optimizer, POT, and NNCF?
Resources
Notices & Disclaimers
Performance varies by use, configuration, and other factors. Learn more at www.Intel.com/PerformanceIndex.
Performance results are based on testing as of dates shown in configurations and may not reflect all publicly available updates. See backup for configuration details. No product or component can be absolutely secure.
Your costs and results may vary.
Intel technologies may require enabled hardware, software or service activation.
Intel disclaims all express and implied warranties, including without limitation, the implied warranties of merchantability, fitness for a particular purpose, and non-infringement, as well as any warranty arising from course of performance, course of dealing, or usage in trade.
© Intel Corporation. Intel, the Intel logo, OpenVINO and the OpenVINO logo are trademarks of Intel Corporation or its subsidiaries. Other names and brands may be claimed as the property of others.

