Named Entity Recognition (NER) is a standard Natural Language Processing problem which deals with information extraction. The primary objective is to locate and classify named entities in text into predefined categories such as the names of persons, organizations, locations, etc. It is used across industries in use cases related to data enrichment, content recommendation, document information retrieval, customer support, text summarization, advanced search algorithms etc.
NER systems can pull entities from an unstructured collection of natural language documents called as knowledge base. This demo notebook 204-named-entity-recognition.ipynb, shows entity recognition from simple text using OpenVINO™ toolkit and you will see how to create the following pipeline to perform entity extraction.

This sample uses small BERT-large-like model distilled and quantized to INT8 on SQuAD v1.1 training set from larger BERT-large model. The model comes from Open Model Zoo.
precision = "FP16-INT8"
model_name = "bert-small-uncased-whole-word-masking-squad-int8-0002"
Input to such entity extraction model would be text with different content sizes i.e., dynamic into shapes. With OpenVINO™ 2022.1, you can get benefit from dynamic shapes support on CPU. This means that you compile your model with either setting upper bound or undefined shapes which gives ability to perform inference on text with different length on each iteration without any additional manipulations with the network or data. Let’s first initialize the inference engine and read the model.
ie_core = Core()
model = ie_core.read_model(model=model_path, weights=model_weights_path)
Input dimension with dynamic input shapes needs to be specified before loading model. It is specified by assigning either -1 to the input dimension or by setting the upper bound of the input dimension. In scope of this notebook, as the longest input text allowed is 384 i.e. 380 tokens for content + 1 for entity + 3 special (separation) tokens, it is more recommended to assign dynamic shape using Dimension(, upper bound) i.e. Dimension(1, 384) so it’ll use memory more efficiently.
for input_layer in model.inputs:
input_shape = input_layer.partial_shape
input_shape[1] = Dimension(1, 384)
model.reshape({input_layer: input_shape})
compiled_model = ie_core.compile_model(model=model, device_name="CPU")
NLP model takes entities, context and vocabulary as standard input. First, you create a list of tokens from the context & entities and then extract the best entity by trying different parts of the context, comparing the prediction confidence scores. Only the entities which have prediction confidence score more than 0.4 will be captured in the final output and this can be set by the user as per the requirements.
def get_best_entity(entity, context, vocab):
context_tokens, context_tokens_end = tokens.text_to_tokens(
text=context.lower(), vocab=vocab)
entity_tokens, _ = tokens.text_to_tokens(text=entity.lower(), vocab=vocab) network_input = prepare_input(entity_tokens, context_tokens)
input_size = len(context_tokens) + len(entity_tokens) + 3
output_start_key = compiled_model.output("output_s")
output_end_key = compiled_model.output("output_e")
result = compiled_model(network_input)
score_start_end = postprocess(output_start=result[output_start_key][0],
output_end=result[output_end_key][0],
entity_tokens=entity_tokens,
context_tokens_start_end=context_tokens_end,
input_size=input_size)
return context[score_start_end[1]:score_start_end[2]], score_start_end[0]
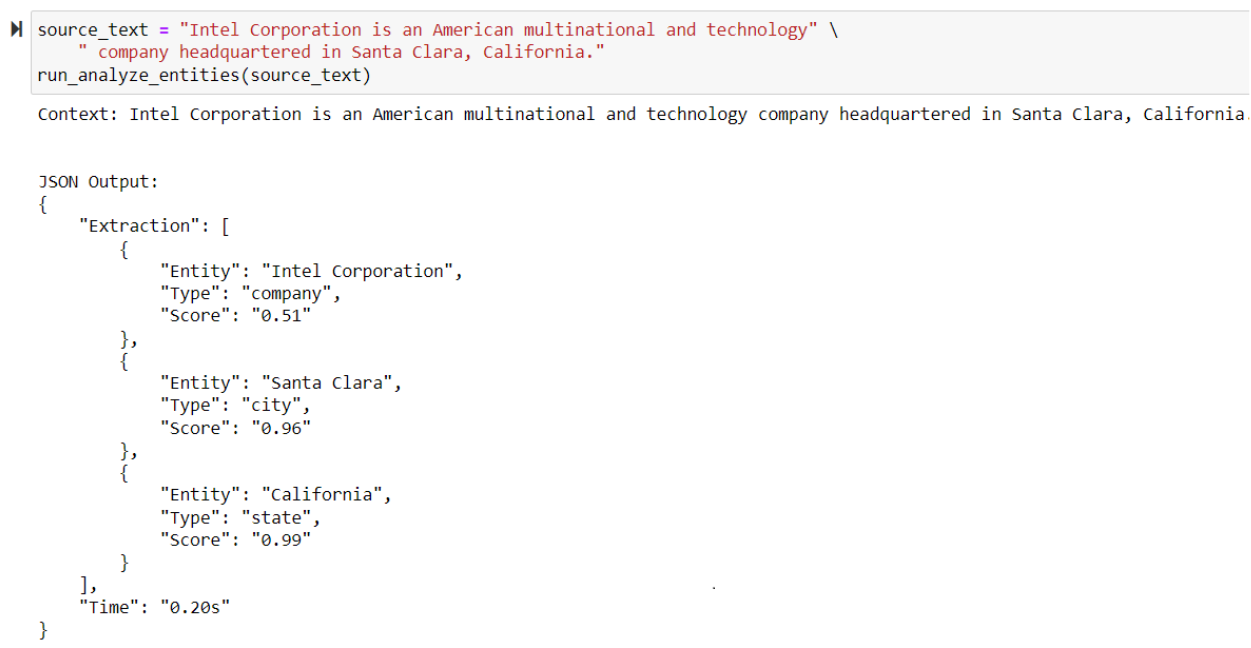
For this example, you can try out named entity recognition for the following entities defined as a simple template.
template = ["building", "company", "persons", "city", "state", "height", "floor", "address"]
And it works! The output will show up as a JSON object containing the extracted entity, context, and the extraction confidence score.
Resources

Notices and Disclaimers
Performance varies by use, configuration, and other factors. Learn more at www.intel.com/PerformanceIndex
No product or component can be absolutely secure.
Intel technologies may require enabled hardware, software or service activation.
The products described may contain design defects or errors known as errata which may cause the product to deviate from published specifications. Current characterized errata are available on request.
© Intel Corporation. Intel, the Intel logo, and other Intel marks are trademarks of Intel Corporation or its subsidiaries. Other names and brands may be claimed as the property of others.

