Because of their energy efficiency and exceptional performance, heterogeneous systems are now the core architectures for most high-performance computing configurations. These systems use several types of processors, including central processing units (CPUs), graphics processing units (GPUs), and field-programmable gate arrays (FPGAs). As a result, we as developers must navigate increasingly complex environments.
Whether implementing a large-scale system at the edge or a small Internet of things (IoT) device, delivering a complete solution now requires an entire ecosystem of tools. Therefore, it’s more important than ever to simplify the programming environment without sacrificing software portability or the flexibility to work with numerous hardware vendors.
With cross-architecture programming and development using Intel oneAPI and its complementary oneAPI IoT Toolkit, standardization broadens — rather than restricts — what’s possible. Furthermore, the oneAPI IoT Toolkit brings the power of big data to the IoT. So, whether our application is related to healthcare, aerospace, security, or smart homes, it provides the tools needed to design, develop, and deploy our application on various hardware architectures.
This article examines how Intel provides standardized specifications that streamline this environment.
Cross-Architecture IoT
To develop more energy-efficient systems and improve performance, we now develop IoT applications for CPUs, GPUs, and FPGAs. Each new architecture presents additional frameworks and tools that require considerable time to learn. We engineer specialized programming languages and ever more sophisticated tools for building, analyzing, and optimizing our applications.
So, the need for standardized development is clear, but not new. Its necessity triggered the creation of OpenCL, an open standard for developing apps for heterogeneous platforms. While novel and quite useful, OpenCL provided only a low level of abstraction and lacked major functionalities that we then needed to construct.
Afterward, the development world saw two potential OpenCL successors in OpenACC and OpenMP, but each significantly limited performance in ways that severely restricted their usability. Later still, the Khronos Group proposed SYCL as a cross-platform abstraction layer built over OpenCL.
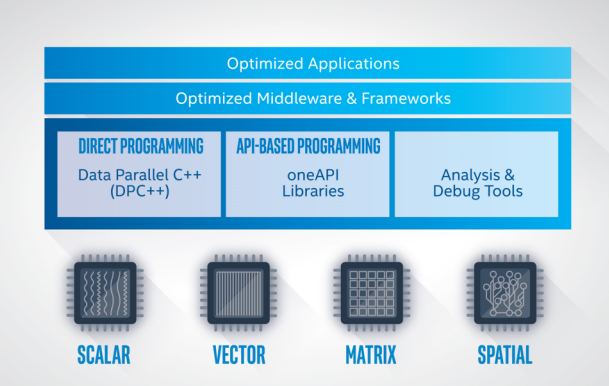
Then Intel developed oneAPI as a unified programming model to aid development for various hardware architectures. The oneAPI model provides a toolkit of runtimes, a set of libraries, and the SYCL programming language. It works to accelerate high-performance computing across the various processor architectures within IoT application development.
oneAPI can also interoperate with other libraries that are based on OpenCL principles. For example, the ArrayFire library is a GPU library developed for high-performance parallel computing used mainly for vector algorithms and image processing. It uses the same principles as oneAPI and can interoperate with oneDNN.
Building for IoT
SYCL supports the development of high-performance apps on CPU, GPU, and FPGA architectures for the IoT. It’s community-driven and built on standards like the International Organization for Standardization (ISO) CPP, ISO C++, and SYCL. The increased level of abstraction associated with DPC++ enables more code reuse across different systems. SYCL eases the burden of adopting new acceleration options in evolving, compute-intensive edge use cases, including network functions, content delivery, and machine learning for voice, video and imaging, among many others.
Libraries for IoT
Intel also extended the ecosystem of tools with pre-optimized libraries to accelerate development for compute-intensive workloads. Applications for math, machine learning, deep learning, and video processing can benefit considerably from these libraries.
One such library is the oneAPI DPC++ Library (oneDPL), which is pre-optimized for data parallelism and offloading. Additionally, there’s the oneAPI Video Processing Library (oneVPL), which is pre-optimized to boost performance on CPUs and GPUs. The oneAPI Deep Neural Network (oneDNN) library combines the C++ standard and parallel Standard Template Library (STL) algorithms, which enable the creation of high-performance deep learning frameworks.
Analysis of Performance on Heterogeneous Systems
With oneAPI comes an improved set of tools for profiling, including the Intel VTune profiler and Advisor. The VTune Profiler enables us to explore SYCL application performance and see which lines of code consume the most resources. We can also optimize performance for any supported hardware accelerators using VTune. Additionally, it features support for popular languages like SYCL, C, C++, Fortran, Python, Java, and Go. It also provides a range of performance analysis types like performance snapshot analysis which provides an overview of the application performance and areas that may require more investigation.
The performance snapshot analysis type makes a suitable starting point. After that, we can have a deeper look at the application by using the Algorithm analysis group type. The Algorithm analysis group type allows us to understand where the application spends most of its time. It includes the Hotspot analysis type, which investigates the call paths and application flow. Another type is the Anomaly detection type. We can analyze the level of nanoseconds and microseconds to uncover sporadic performance anomalies that may cause poor user experience. Moreover, the Algorithm analysis group type contains memory consumption analysis, which is the best way to understand our application memory use over time.
Finally, Intel Advisor is a set of tools to help ensure the program is making the best of the hardware potential by providing tools like the Threading Advisor. The Threading Advisor helps check for threading design options.
Another useful tool is the Offload Advisor, which helps in identifying the opportunities for offloading to GPU and where the offloading can be useful. Offload Advisor along with the Roofline Analysis can help to visualize the performance of CPU or GPU, providing insights for bottlenecks in the system and highlighting where we can optimize.
Intel Advisor also provides the Vectorization and Code Insights tool to help us uncover any unoptimized loops. With the help of Intel Advisor, we can achieve the optimal performance on our platform.
Optimizing Edge Computing Performance
Edge computing is a model that performs computations near the location of the data source. One of its benefits is low processing latency. Edge computing enables IoT devices to filter and process data without transmitting it back and forth, which is extremely useful for real-time applications.
Another advantage of edge computing is bandwidth preservation, which reduces the size of transferred data by performing data compression before sending. Finally, well-designed edge computing can enhance system security and privacy. However, to experience the full potential of these benefits, we must first optimize the performance of our code for our edge-based IoT devices. This can be challenging, as various devices have different hardware configurations, computing options and resource constraints. Access to a tool suite that scales across various computing solutions and supports changing acceleration options can simplify complexity and limit cycles spent to refactor code as needs change.
Code Migration from CUDA
Migrating to a new programming model often requires rewriting code. Fortunately, oneAPI assists us to migrate from CUDA to SYCL using the Intel DPC++ Compatibility Tool (DPCT), generating human-readable code wherever possible. This tool automatically migrates approximately 80 to 90 percent[i] of CUDA code into SYCL and provides tips on how to manually convert the remaining code. You can learn more about converting CUDA to SYCL by reading Using oneAPI to Convert CUDA to SYCL.
As a result, the steps for migrating our code into SYCL are relatively simple. We only need to create a compilation database file through the intercept build system. After that, we can migrate to SYCL using the DPCT and check whether we must manually migrate any remaining code. The final step is to compile our oneAPI DPC++ code using the DPC++ Compiler.
A Case Study
Samsung Medison, specializing in ultrasonic medical systems, is an excellent example of how oneAPI helps improve performance. Samsung partnered with Intel to accelerate image processing in its ultrasound systems resulting in more efficient and accurate diagnosis. They used Intel’s Distribution of OpenVino™ toolkit and OpenCV library with Samsung Medison’s BiometryAssist to automate and simplify fetal measurements. Next, Samsung used the Intel Compatibility Tool to port their existing code to SYCL, allowing them to use one code base to test different accelerator solutions. Samsung tested their migration with Intel VTune Profiler to analyze the code’s performance and streamline their implementation to run efficiently. The IoT solutions from Samsung Medison were further optimized using the Intel oneAPI Base Toolkit.
Conclusion
The evolution of cross-architecture programming has made even more apparent the need for standardized development environments. Fortunately, oneAPI combines performance and abstraction to support multiple architectures and propel development toward this standardization.
Intel’s oneAPI provides tools for the IoT, edge computing, and cross-architectural support that does not restrict us to one manufacturer or vendor. Its DPC++ Compatibility Tool (DPCT) and VTune Profiler can help us optimize performance and uncover additional optimization opportunities.
While its real-world applications have already contributed to medical institutions and personal smart technology, the potential of oneAPI is far from fully realized. There’s plenty of room for your next great cross-architectural project, but the best way to start is to try oneAPI and experience all that it makes possible.
Intel estimates as of September 2021. Based on measurements on a set of 70 HPC benchmarks and samples, with examples like Rodinia, SHOC, and PENNANT. Results may vary.

