Jacobi iterative method
The Jacobi iterative method is used to find approximate numerical solutions for systems of linear equations of the form Ax = b in numerical linear algebra, which is diagonally dominant. The algorithm starts with an initial estimate for x and iteratively updates it until convergence. The Jacobi method is guaranteed to converge if matrix A is diagonally dominant.
CUDA to SYCL migration approach
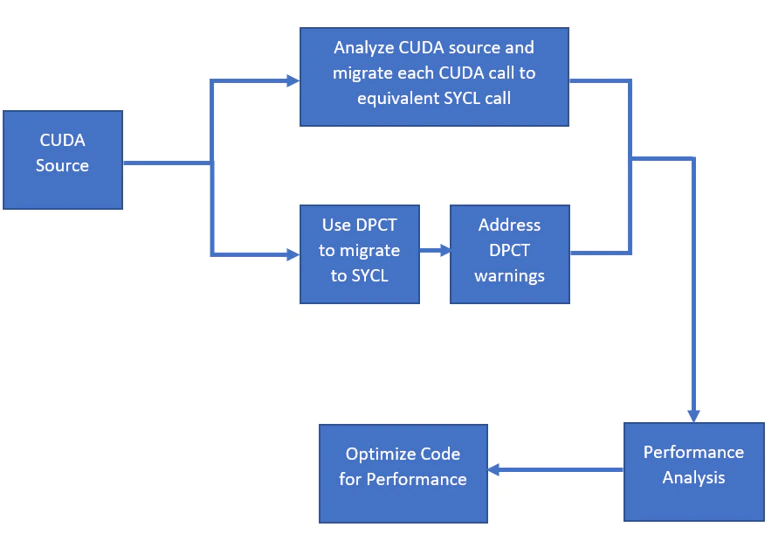
This document covers two approaches for CUDA to SYCL migration:
- The first approach is using the Intel® DPC++ Compatibility Tool to automatically migrate CUDA source to SYCL source. The tool migrates 80 to 90 percent of the code and generates a warning for the rest, which has to be manually migrated to SYCL. We look at Intel DPC++ Compatibility Tool generated warnings and learn how to migrate the code that was not migrated by the Intel DPC++ Compatibility Tool. This approach helps to accelerate the migration of CUDA source to SYCL and has proven especially helpful for large code bases.
- The second approach is manual migration by analyzing CUDA source and replacing all CUDA-specific calls with equivalent SYCL calls. This approach helps a CUDA developer to understand SYCL programming. Once the migration is complete, we do performance analysis using VTuneTM Profiler and Intel® Advisor Roofline to understand the performance bottlenecks. We then look at optimizing the code for performance. Review the SYCL 2020 Specification for more details.
The following flow diagram shows the approach used for CUDA to SYCL migration:
Using Intel® DPC++ Compatibility Tool for migration
The Intel DPC++ Compatibility Tool and how to use it
The Intel DPC++ Compatibility Tool is a component of the Intel® oneAPI Base Toolkit that assists the developer in the migration of a program that is written in CUDA to a program written in DPC++.
Although Intel DPC++ Compatibility Tool automatically migrates most of the code, some manual work is required for a full migration. The tool outputs warnings to indicate how and where manual intervention is needed. These warnings have an assigned ID of the form "DPCT10XX" that can be consulted in the Developer Guide and Reference. This guide contains a list of all the warnings, their description and a suggestion to fix it.
Migrate CUDA to SYCL using Intel DPC++ Compatibility Tool
The Intel DPC++ Compatibility Tool helps transfer CUDA-based code to SYCL and generates human-readable code, with the original identifiers from the original code preserved. The tool also detects and transforms standard CUDA index computations to SYCL. The goal of this sample is to perform the migration process from CUDA to SYCL using the Intel DPC++ Compatibility Tool and demonstrate portability obtained by the migrated SYCL code in different GPU and CPU devices. The tool works by intercepting the build process and replacing CUDA code with the SYCL counterpart.
This CUDA source is migrated to SYCL mainly by replacing the CUDA expressions for the SYCL equivalent and transforming the kernel invocation to a submission to a SYCL queue of a parallel_for with a lambda expression.
The Intel DPC++ Compatibility Tool migrated code for Jacobi iterative can be found at sycl_dpct_output.
To ensure you have the CUDA versions and required tools, please see Intel DPC++ Compatibility Tool system requirements
Follow these steps to migrate the CUDA Jacobi iterative sample to SYCL:
- Make sure the system has Nvidia CUDA SDK installed (in the default path) and you have installed the Intel DPC++ Compatibility Tool from the Intel® oneAPI Base Toolkit.
- Set the environment variables, the setvars.sh script is in the root folder of your oneAPI installation, which is typically /opt/intel/oneapi/
. /opt/intel/oneapi/setvars.sh
- Get the CUDA implementation of the Jacobi iterative method from: JacobiCUDA_Sample.
- Go to the CUDA source folder and generate a compilation database with the tool
intercept-build. This creates a JSON file with all the compiler invocations and stores the names of the input files and the compiler options.
intercept-build make
- Use the Intel DPC++ Compatibility Tool to migrate the code; it will store the result in the migration folder
dpct_output.
Intel DPC++ Compatibility Tool Options that Ease Migration and Debug | --keep-original-code | Keep original CUDA code in the comments of generated SYCL file. Allows easy comparison of original CUDA code to generated SYCL code. |
| --comments | Insert comments explaining the generated code |
| ---always-use-async-handler | Always create cl::sycl::queue with the async exception handler |
dpct -p compile_commands.json
- Verify the migration and address any Intel DPC++ Compatibility Tool warnings generated by consulting the diagnostics reference for detailed information about the Intel DPC++ Compatibility Tool warnings.
- Adapt the makefile to use the DPCPP compiler when appropriate and remove the CUDA-specific compilation flags.
For more information refer to Intel® DPC++ Compatibility Tool Best Practices.
Implement unmigrated SYCL code
Once the Intel DPC++ Compatibility Tool migrates the code, the unmigrated code can be identified by the warnings. These warnings have an assigned ID, which can be resolved by manual workarounds by referring to the Developer Guide and Reference.
The Intel DPC++ Compatibility Tool complete migrated code for Jacobi iterative can be found at sycl_dpct_migrated.
Warnings generated with migration and manual workaround:
- DPCT1025: The SYCL queue is created ignoring the flag and priority options.
cudaStreamCreateWithFlags(&stream1, cudaStreamNonBlocking);
CUDA Streams equivalent in DPCPP would be queues, hence Intel DPC++ Compatibility Tool creates SYCL queues, ignoring the flag and priority options.
sycl::queue *stream1;
- DPCT1065: Consider replacing
sycl::nd_item::barrier() with sycl::nd_item::barrier(sycl::access::fence_space::local_space) for better performance if there is no access to global memory.
cg::sync(cta);
Inside a kernel, Intel DPC++ Compatibility Tool suggests replacing barrier() for better performance if there is no access to global memory. In this case the user should check the memory accesses and do the modification.
- DPCT1007: Migration of this CUDA API is not supported by the DPC++ Compatibility Tool.
cg::thread_block_tile<32> tile32 = cg::tiled_partition<32>(cta);
atomicAdd(sum, temp_sum);
Many CUDA device properties don't have a SYCL equivalent, are slightly different, or aren't currently supported. On many occasions this will cause the retrieval of incorrect values. For this reason, the user must manually review and correct the information queries to the device.
Following is the workaround for the above code:
sub_group tile_sg = item_ct1.get_sub_group();
int tile_sg_size = tile_sg.get_local_range().get(0);
atomic_ref<double, memory_order::relaxed, memory_scope::device,
access::address_space::global_space> at_sum { *sum };
at_sum.fetch_add(temp_sum);
- DPCT1039: The generated code assumes that "sum" points to the global memory address space. If it points to a local memory address space, replace "
dpct::atomic_fetch_add" with
"dpct::atomic_fetch_add<double, sycl::access::address_space::local_space>"
atomicAdd(sum, temp_sum);
For better Memory access and performance, we need to specify the access address space to global or local space.
sycl::atomic<int> at_sum(sycl::make_ptr<int,sycl::access::address_space::global_space>((int*) sum));
sycl::atomic_fetch_add<int>(at_sum, temp_sum);
- DPCT1049: The work-group size passed to the SYCL kernel may exceed the limit. To get the device limit, query
info::device::max_work_group_size. Adjust the work-group size if needed.
Intel DPC++ Compatibility Tool suggests querying info::device::max_work_group_size to get the device limit and adjust the work-group size accordingly.
cgh.parallel_for(nd_range<3>(nblocks * nthreads, nthreads),
[=](nd_item<3>item_ct1) [[intel::reqd_sub_group_size(ROWS_PER_CTA)]] {
JacobiMethod(A, b, conv_threshold, x_new, x, d_sum, item_ct1, x_shared_acc_ct1.get_pointer(), b_shared_acc_ct1.get_pointer());
});
- DPCT1083: The size of local memory in the migrated code may be different from the original code. Check that the allocated memory size in the migrated code is correct.
Some types have a different size in the migrated code than in the original code; for example, sycl::float3 compared to float3. So, the allocated size of local memory should be validated in the migrated code.
- When the block size is specified with a macro and used to create a
sycl::range, the expanded value should be changed back to the macro. When this is the case, the tool leaves the original macro commented.
Analyzing CUDA source
The CUDA implementation of the Jacobi iterative method is available at: JacobiCUDA_Sample.
The CUDA source for the Jacobi iterative method implementation is in the following files.
- main.cpp—host code for:
- setting up CUDA stream
- memory allocation on GPU
- initialization of data on CPU
- copy data to GPU memory for computation
- kickoff computation on GPU
- verify and print results
- jacobi.cu —kernel code for Jacobi iteration method computation that runs on GPU
- defining kernel
- allocate shared local memory
- cooperative groups for partitioning of thread blocks
- using warp primitives
- using atomics for adding up sum values of tiles
CUDA code has just two files: main.cpp and jacobi.cu. The main.cpp includes CPU implementation of Jacobi method memory allocation, initialization, kernel launch, memory copy, and execution time calculation using an SDK timer.
The jacobi.cu includes the kernels, Jacobi method and final error. The Jacobi method involves loading the vectors into shared memory for faster memory access and partitions thread blocks into tiles. Then, reduction of input data is performed in each of the partitioned tiles using warp-level primitives. These intermediate results are then added to a final sum variable via an atomic add. This also results in faster implementation, avoiding unnecessary block-level synchronizations.
This sample application demonstrates the CUDA Jacobi iterative method using key concepts such as stream capture, atomics, shared memory and cooperative groups.
Migrating from CUDA to SYCL
In this section we will migrate the CUDA code to SYCL by analyzing the CUDA code and identifying relevant SYCL features. The underlying concepts of CUDA and SYCL are similar, but understanding the nomenclature for each language is essential to migrating a CUDA code to a SYCL code. Review the SYCL 2020 Specification for more details.
The CUDA code in main.cpp and jacobi.cu will be migrated to SYCL versions in main.cpp and jacobi.cpp.
CUDA headers and SYCL headers
In the CUDA implementation, the cuda_runtime.h header is used, which defines the public host functions, built-in type definition for the CUDA runtime API, and function overlays for the CUDA language extensions and device intrinsic functions.
#include <cuda_runtime.h>
The SYCL implementation uses this single header to include all of the API interface and the dependent types defined in the API.
#include <CL/sycl.hpp>
CUDA streams and SYCL queues
A CUDA stream is a sequence of operations that execute on the device in the order in which they are issued by the host code. The host places CUDA operations within a stream (for example, kernel launches, memory copies) and continues immediately. The device then schedules work from streams when resources are free. Operations within the same stream are ordered first-in, first-out (FIFO). Different streams, on the other hand, may execute their commands out of order with respect to one another or concurrently.
SYCL has queues that connect a host program to a single device. Programs submit tasks to a device via the queue and may monitor the queue for completion. In a similar fashion to CUDA streams, SYCL queues submit command groups for execution asynchronously. However, SYCL is a higher-level programming model, and data transfer operations are implicitly deduced from the dependencies of the kernels submitted to any queue.
In the CUDA implementation, the first step is to create a new asynchronous stream. The flag argument determines the behavior of the stream. cudaStreamNonBlocking Specifies that work running in the created stream may run concurrently with work in stream 0 (the NULL stream), and that the created stream should perform no implicit synchronization with stream 0. CUDA streams are used to perform asynchronous memset and memcpy to implement the concurrent model, and then launch the kernel with the stream specified so that they will return to the host thread immediately after call. CUDA streams are set up as follows (main.cpp):
cudaStream_t stream1;
checkCudaErrors(cudaStreamCreateWithFlags(&stream1, cudaStreamNonBlocking));
In SYCL we use queues in a similar fashion to CUDA streams; queues submit command groups for execution asynchronously. The SYCL runtime handles the execution order of the different command groups (kernel + dependencies) automatically across multiple queues in different devices. We can set up a SYCL queue as follows with in_order queue property and we use default_selector(); this will determine the SYCL device to be used. The default selector chooses the first available SYCL device. The system resources required by the queue are released automatically after it goes out of scope. The in_order queue will make sure that the kernel computation starts only after the memcpy operations are complete and no overlap of kernel execution occurs.
sycl::queue q{sycl::default_selector(),sycl::property::queue::in_order()};
More information can be found in SYCL queue.
Memory allocation on GPU device—cudaMalloc and sycl::malloc_device
We must first allocate memory on the GPU device in order to use it to copy data to GPU memory, so that it is available for computation on GPU. The cudaMalloc function can be called from the host or the device to allocate memory on the device, much like malloc for the host. The memory allocated with cudaMalloc must be freed with cudaFree.
In CUDA, memory allocation on GPU is done as follows using the cudaMalloc function:
checkCudaErrors(cudaMalloc(&d_b, sizeof(double) * N_ROWS));
checkCudaErrors(cudaMalloc(&d_A, sizeof(float) * N_ROWS * N_ROWS));
In SYCL, memory allocation on the accelerator device is accomplished using the sycl::malloc_device function as follows:
d_b = sycl::malloc_device<double>(N_ROWS, q);
d_A = sycl::malloc_device<float>(N_ROWS * N_ROWS, q);
The sycl::malloc_device returns a pointer to the newly allocated memory on the specified device on success. This memory is not accessible on the host. Memory allocated by the sycl::malloc_device must be deallocated with sycl::free to avoid memory leaks.
More information on Unified Shared Memory (USM) concepts and memory allocations can be found at SYCL USM.
Memory copy from host to GPU memory
Once memory is allocated on the GPU, we must copy the memory from host to device, so that the data is available at the device for computation.
In CUDA, memory is copied from host to GPU using cudaMemsetAsync as follows. Memory is copied asynchronously with respect to the host, so the host places the transfer into the stream and the call may return immediately. The operation can optionally be associated to a stream by passing a non-zero stream argument. If the stream is non-zero, the operation may overlap with operations in other streams.
checkCudaErrors(cudaMemsetAsync(d_x, 0, sizeof(double) * N_ROWS, stream1));
checkCudaErrors(cudaMemsetAsync(d_x_new, 0, sizeof(double) * N_ROWS, stream1));
checkCudaErrors(cudaMemcpyAsync(d_A, A, sizeof(float) * N_ROWS * N_ROWS, cudaMemcpyHostToDevice, stream1));
checkCudaErrors(cudaMemcpyAsync(d_b, b, sizeof(double) * N_ROWS, cudaMemcpyHostToDevice, stream1));
CUDA streams are synchronized using cudaStreamSynchronize, which blocks the host until all issued CUDA calls in the stream are complete.
checkCudaErrors(cudaStreamSynchronize(stream));
In SYCL, we use memcpy to copy memory from host to device memory. To initialize memory, memset can be used to initialize the vector with data as shown:
q.memset(d_x, 0, sizeof(double) * N_ROWS);
q.memset(d_x_new, 0, sizeof(double) * N_ROWS);
q.memcpy(d_A, A, sizeof(float) * N_ROWS * N_ROWS);
q.memcpy(d_b, b, sizeof(double) * N_ROWS);
The first argument is memory address pointer with value; this must be a USM allocation. SYCL memcpy copies data from the pointer source to the destination. Both source and destination may be either host or USM pointers.
Memory is copied asynchronously, but before any of the memory can be used, we need to ensure that the copy is complete by synchronizing using:
q.wait();
wait() will block the execution of the calling thread until all the command groups submitted to the queue have finished execution.
More information about SYCL memcpy and asynchronous copy and synchronizing data can be found at SYCL queue and memcpy and wait.
This completes the host side CUDA code (main.cpp) migration to SYCL:
The CUDA host code for main.cpp can be found at main.cpp.
The SYCL code for host code main.cpp can be found at main.cpp.
The next sections explain CUDA kernel code (jacobi.cu) migration to SYCL.
Offloading computation to GPU
The CUDA kernel code is in jacobi.cu. The computation happens in two kernels, Jacobi method and final error. These computations are offloaded to the device. In both Jacobi method and final error computations we use shared memory, cooperative groups, and reduction. Vectors are loaded into shared memory for faster and frequent memory access to the block. Cooperative groups are used in further dividing the work group into subgroups. Because the computation shown above happens inside subgroups, which eliminates the need of block barriers, and are apt for the low granularity of reduction algorithm having each thread run much more efficiently or distributing the work effectively. The reduction is performed using sync() to synchronize over different thread blocks, rather than the entire grid, so the implementation is a lot faster at avoiding synchronization block. Shift group left is a SYCL primitive used to do the computation within the subgroup to add all the thread values and are passed on to the first thread. And all the subgroup sums are added through atomic add.
Final error is used to calculate the error sum between CPU and GPU computations to validate the output. Warpsum is added with the absolute value of x subtracted with 1 (each thread value is added), and then all the warpsum values are added to the blocksum. The final error is stored in the g_sum.
In CUDA, a group of threads is named a thread block or simply a block. This is equivalent to the SYCL concept of work-group. Both block and work-group can access the same level of the hierarchy and expose similar synchronization operations.
A CUDA stream is a sequence of CUDA operations, submitted from host code. These operations are executed asynchronously in order of submission. If no CUDA stream is given a default CUDA stream is created, and all operations are submitted to the default stream.
In a similar fashion to CUDA streams, SYCL queues submit command groups for execution asynchronously. However, SYCL data transfer operations are implicitly deduced from the dependencies of the kernels submitted to any queue.
In CUDA, a kernel is launched with the following parameters: nblocks specifies the dimension and size of the grid, nthreads specifies the dimension and size of each block, a third parameter specifies the number of bytes in shared memory that is dynamically allocated per block, and stream specifies the associated stream, an optional parameter that defaults to 0.
JacobiMethod<<<nblocks, nthreads, 0, stream>>> (A, b, conv_threshold, x, x_new, d_sum);
In SYCL, kernel constructs like single_task, parallel_for, and parallel_for_work_group each take a function object or a lambda function as one of their arguments. The code within the function object or lambda function is executed on the device.
q1.submit([&](handler &cgh) {
cgh.parallel_for(nd_range<3>(nblocks * nthreads, nthreads), [=](nd_item<3> item_ct1) {
JacobiMethod(A, b, conv_threshold, x, x_new, d_sum, item_ct1, x_shared_acc_ct1.get_pointer(), b_shared_acc_ct1.get_pointer(), stream_ct1);
});
});
After the queue setup, in our command group we submit a kernel using parallel_for. This function will execute the kernel in parallel on several work-items. An nd_range specifies a 1-, 2-, or 3-dimensional grid of work items that each executes the kernel function, which are executed together in work groups. The nd_range consists of two 1-, 2-, or 3 dimensional ranges: the global work size (specifying the full range of work items) and the local work size (specifying the range of each work group).
The nd_item describes the location of a point in a sycl::nd_range. An nd_item is typically passed to a kernel function in a parallel_for. In addition to containing the ID of the work item in the work group and global space, the nd_item also contains the sycl::nd_range defining the index space.
CUDA thread block and SYCL work-group
In CUDA, Cooperative Groups provide device code APIs for defining, partitioning, and synchronizing groups of threads. We often need to define and synchronize groups of threads smaller than thread blocks in order to enable greater performance and design flexibility.
An instance of thread_block is a handle to the group of threads in a CUDA thread block that you initialize as follows:
cg::thread_block cta = cg::this_thread_block();
Every thread that executes that line has its own instance of the variable block. Threads with the same value of the CUDA built-in variable blockIdx are part of the same thread block group.
In SYCL, a single execution of a given kernel is organized into work-groups and work-items. Each work-group contains the same number of work-items and is uniquely identified by a work-group ID. Additionally, within a work-group, a work-item can be identified by its local ID, and the combination of a local ID with a work-group ID is equivalent to the global ID.
auto cta = item_ct1.get_group();
SYCL get_group returns the constituent element of the group ID representing the work-group’s position within the overall nd_range in the given dimension.
Shared local memory access
In CUDA, shared memory is on-chip and is much faster than local and global memory. Shared memory latency is roughly 100x lower than uncached global memory latency. Threads can access data in shared memory loaded from global memory by other threads within the same thread block. Memory access can be controlled by thread synchronization to avoid a race condition (__syncthreads).
__shared__ double x_shared[N_ROWS];
__shared__ double b_shared[ROWS_PER_CTA + 1];
In SYCL, shared local memory (SLM) is on-chip in each work-group; the SLM has much higher bandwidth and much lower latency than global memory. Because it is accessible to all work-items in a work-group, the SLM can accommodate data sharing and communication among hundreds of work-items, depending on the work-group size. Work-items in the work-group can explicitly load data from global memory into SLM. The data stays in SLM during the lifetime of the work-group for faster access. Before the work-group finishes, the data in the SLM can be explicitly written back to the global memory by the work-items. After the work-group completes execution, the data in SLM becomes invalid.
accessor<double, 1, access_mode::read_write, access::target::local> x_shared_acc_ct1(range<1>(N_ROWS), cgh);
accessor<double, 1, access_mode::read_write, access::target::local> b_shared_acc_ct1(range<1>(ROWS_PER_CTA + 1), cgh);
CUDA thread block synchronization and SYCL barrier synchronization
Synchronization is used to synchronize the states of threads sharing the same resources.
In CUDA, Synchronization is supported by all thread groups. We can synchronize a group by calling its collective sync() method, or by calling the cooperative_groups::sync() function. These perform barrier synchronization among all threads in the group.
cg::sync(cta);
In SYCL, to synchronize the state of memory, we use the item::barrier(access::fence_space) operation. It makes sure that each work-item within the work-group reaches the barrier call. In other words, it guarantees that the work-group is synchronized at a certain point in the code.
item_ct1.barrier();
item::barrier emits a memory fence in the specific space - it can be either access::fence_space::local_space, ::global_space or ::global_and_local. A fence ensures that the state of the specified space is consistent across all work-items within the work-group.
CUDA cooperative group and SYCL subgroup
CUDA Cooperative Groups and SYCL subgroup aim to extending the programming model to allow kernels to dynamically organize groups of threads so that threads cooperate and share data to perform collective computations.
In CUDA, Cooperative Groups provides you with the flexibility to create new groups by partitioning existing groups. This enables cooperation and synchronization at finer granularity. The cg::tiled_partition() function partitions a thread block into multiple tiles.
cg::thread_block_tile<32> tile32 = cg::tiled_partition<32>(cta);
Each thread that executes the partition will get a handle (in tile32) to one 32-thread group.
In SYCL, sub groups allow partition of a work-group which map to low-level hardware and provide additional scheduling guarantees. The subgroup is an extension to the SYCL execution model, and it is hierarchically between the work_group and work_item. SYCL implementations often map sub-groups to low-level hardware features: for example, it is common for work-items in a sub-group to be executed in SIMD on hardware supporting vector instructions.
sub_group tile_sg = item_ct1.get_sub_group();
The set of sub-group sizes supported by a device is device-specific, and individual kernels can request a specific sub-group size at compile-time. This sub-group size is a compile time constant. In order to achieve the best performance, we need to try to match the optimal sub group size to the size of the compute units on the hardware. If not set, the compiler will attempt to select the optimal size for the subgroup.
[[intel::reqd_sub_group_size(SIZE)]]
CUDA warp primitives and SYCL group algorithms
Primitives were introduced to make warp-level programming safe and effective. CUDA executes groups of threads in single instruction, multiple thread (SIMT) fashion. We can achieve high performance by taking advantage of warp execution.
In CUDA, thread_block_tile::shfl_down() is used to simplify our warp-level reduction and eliminates the need for shared memory.
for (int offset = tile32.size() / 2; offset > 0; offset /= 2) {
rowThreadSum += tile32.shfl_down(rowThreadSum, offset);
}
Each iteration halves the number of active threads and each thread adds its partial sum to the first thread of the block.
In SYCL, the equivalent to CUDA shfl_down is shift_group_left, which moves values held by the work-items in a group directly to another work-item in the group, by shifting values a fixed number of work-items to the left.
for (int offset = tile_sg.get_local_range().get(0) / 2; offset > 0; offset /= 2) {
rowThreadSum += shift_group_left(tile_sg,rowThreadSum, offset);
}
CUDA atomics and SYCL atomics
Atomic operations are operations that are performed without interference from any other threads. Atomic operations are often used to prevent race conditions, which are common problems in multithreaded applications.
In CUDA, atomicAdd() reads a word at some address in global or shared memory, adds a number to it, and writes the result back to the same address. No other thread can access this address until the operation is complete. Atomic functions do not act as memory fences and do not imply synchronization or ordering constraints for memory operations.
if (tile32.thread_rank() == 0) {
atomicAdd(&b_shared[i % (ROWS_PER_CTA + 1)], -rowThreadSum);
}
In SYCL, the equivalent is atomic_ref, which supports float, double data types. The set of supported orderings is specific to a device, but every device is guaranteed to support at least memory_order::relaxed.
if (tile32_sg.get_local_id()[0] == 0) {
atomic_ref<double, memory_order::relaxed, memory_scope::device, access::address_space::local_space> at_h_sum { b_shared[i % (ROWS_PER_CTA + 1)]};
at_h_sum.fetch_add(-rowThreadSum);
}
The template parameter space is permitted to be access::address_space::generic_space, access::address_space::global_space or access::address_space::local_space.
This completes the kernel side CUDA code (jacobi.cu) migration to SYCL:
The CUDA kernel code for jacobi.cu can be found at jacobi.cu.
The SYCL kernel code for jacobi.cpp can be found at jacobi.cpp.
This concludes all the CUDA migration to SYCL. We have source files main.cpp and jacobi.cpp that can be compiled for any GPU using the appropriate SYCL compiler, rather than having source in CUDA that can only run on Nvidia GPUs.
With this SYCL source, we can compile to run Jacobi iterative on Intel® GPUs or CPUs using oneAPI DPC++ Compiler. Or we can compile to run on Nvidia GPUs/AMD GPUs using the open source LLVM compiler or hipSYCL compiler.
SYCL allows our source code to be portable across CPUs and GPUs from different vendors rather than being locked to a vendor-specific hardware.
Tools for performance analysis
Intel® VTune™ Profiler
Intel® VTune Profiler is a performance analysis tool for serial and multi-threaded applications. It helps to analyze algorithm choices and identify where and how applications can benefit from available hardware resources. The data collector profiles your application using the OS timer, interrupts a process, collects samples of all active instruction addresses with the sampling interval of 10ms, and captures a call sequence (stack) for each sample. By default, the collector does not gather system-wide performance data, but focuses on your application only. Review the Get Started with Intel® VTune™ Profiler for more details.
To collect profiling data the following script can be run in the command line:
source /opt/intel/oneapi/setvars.sh
bin="jacobiSYCL"
prj_dir="vtune_data"
echo $bin
rm -r ${prj_dir}
echo "Vtune Collect hotspots"
vtune -collect gpu-hotspots -result-dir ${prj_dir} $(pwd)/${bin}
echo "Vtune Summary Report"
vtune -report summary -result-dir ${prj_dir} -format html -report-output $(pwd)/vtune_${bin}.html
Make sure the above script "vtune_report.sh" file is in the same location as the application binary, make any necessary changes to the binary name in script if your binary name is different, run the script to collect VTune Profiling data and generate html report, the HTML report will look like this:
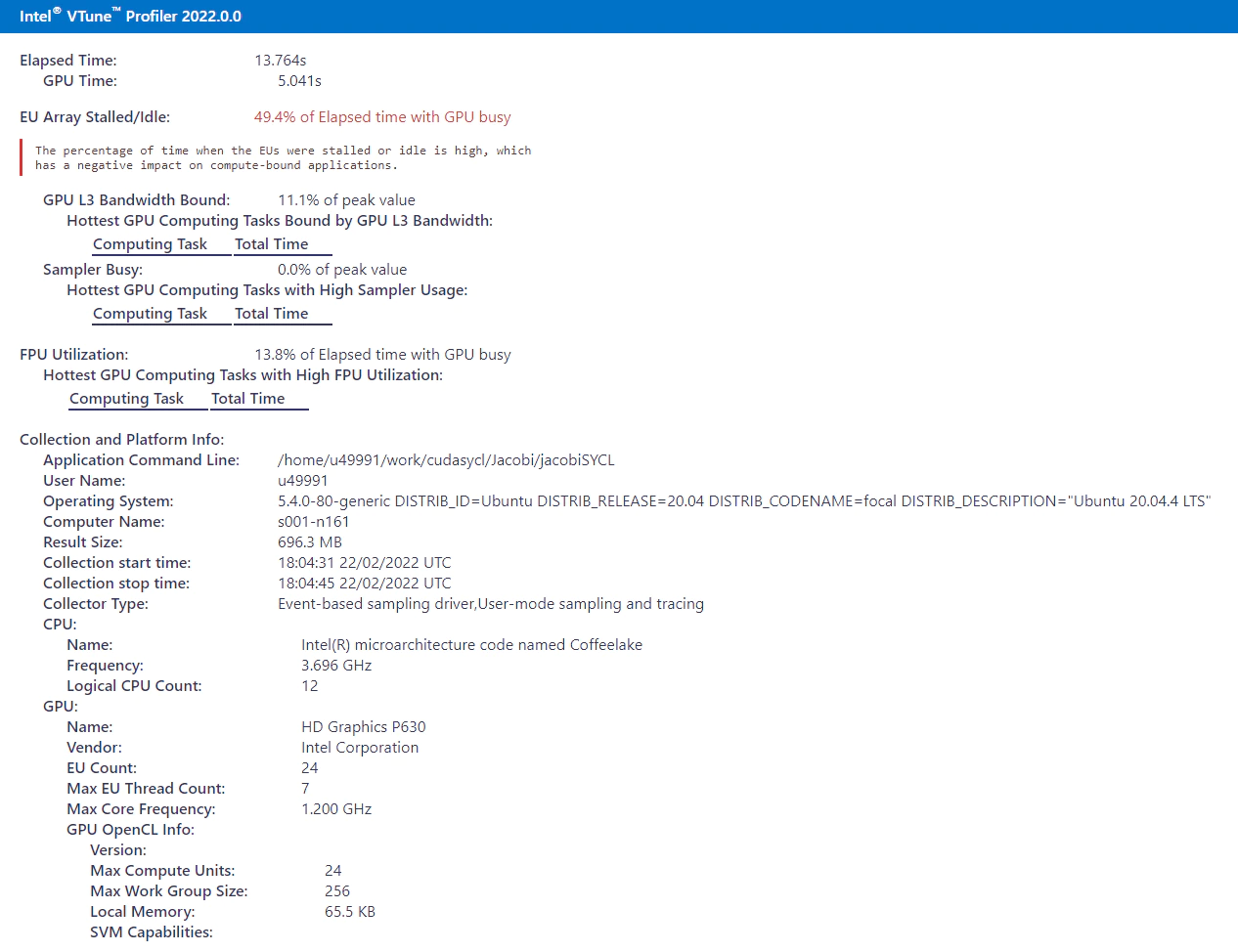
Figure 1: VTuneTM Profiler metrics.
Figure 1 is the snapshot from VTune Profiler, which represents the total elapsed time of the Jacobi iterative SYCL migrated code. The total elapsed time is 13.764s, out of which GPU time is 5.041s. The report also describes the idle time of the GPU; throughout the execution period only 50 percent of the GPU core bandwidth is utilized, which is good scope for improvement.
Intel® Advisor Roofline
A Roofline chart is a visual representation of application performance in relation to hardware limitations, including memory bandwidth and computational peaks. Roofline requires data from both the survey and trip counts with flops analysis types. You can choose to run these analyses separately or use a shortcut command that will run them one after the other. Review the Get Started with Intel® Advisor for more details.
To collect profiling data the following script can be run in the command line:
source /opt/intel/oneapi/setvars.sh
bin="jacobiSYCL"
prj_dir="./roofline_data"
echo $bin
rm -r ${prj_dir}
advisor --collect=survey --project-dir=${prj_dir} --profile-gpu -- ./${bin} -q
advisor --collect=tripcounts --project-dir=${prj_dir} --flop --profile-gpu -- ./${bin} -q
advisor --report=roofline --gpu --project-dir=${prj_dir} --report-output=./roofline_gpu_${bin}.html -q
Make sure the above script "roofline_report.sh" file is in the same location as the application binary, make any necessary changes to the binary name in script if your binary name is different, run the script to collect Intel Advisor Roofline data and generate html report, the HTML report will look like this:
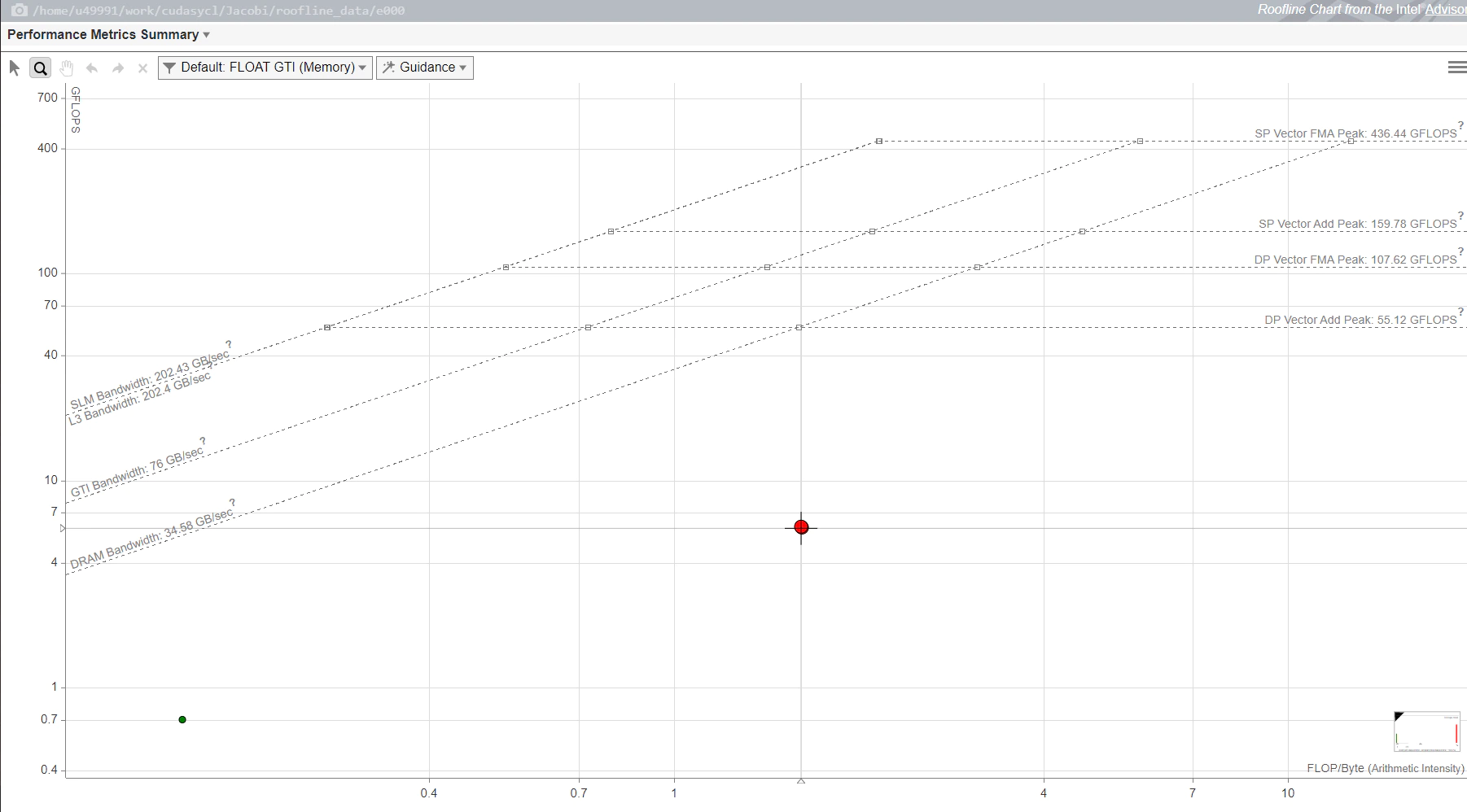
Figure 2: GPU Roofline chart.
The GPU Roofline chart shows performance of the application in terms of memory and compute. The x‑axis represents the arithmetic intensity and y-axis represents the compute performance. This report shows that the maximum possible attainable bandwidth using DRAM is 34.58 GB/sec, GTI bandwidth is 76 GB/sec, L3 bandwidth is 202.4 GB/sec, and SLM bandwidth is 202.43 GB/sec—the maximum attainable compute performance of both single precision and double precision for vector FMA and vector add.
In the chart, each dot represents a loop or function in the application. The dot's position indicates the performance of the loop or function, which is affected by its optimization and its arithmetic intensity. The dot's size and color indicate how much of the total application time the loop or function takes. Large red dots take up the most time and are the best candidate for optimization. Small green dots take up relatively little time, so are likely not worth optimizing.
Optimizing SYCL code for performance
Reduction operation optimization
shift_group_left moves values held by the work-items in a group directly to another work-item in the group, by shifting values a fixed number of work-items to the left.
for (int offset = tile_sg.get_local_range().get(0) / 2; offset > 0; offset /= 2) {
rowThreadSum += shift_group_left(tile_sg, rowThreadSum, offset);
}
The above code snippet depicts the Jacobi iterative code before optimization. Here the shift_group_left has been replaced with reduce_over_group to get better performance.
reduce_over_group implements the generalized sum of the array elements internally by combining values held directly by the work-items in a group. The work-group reduces a number of values equal to the size of the group and each work-item provides one value.
rowThreadSum = reduce_over_group(tile_sg, rowThreadSum, sycl::plus<double>());
The above code snippet depicts the Jacobi SYCL optimized code. By using reduce_over_group API reduction of approximately 35% has been observed in the runtime of the application on Intel GPU.
Atomic operation optimization
fetch_add atomically adds operand to the value of the object referenced by this atomic_ref and assigns the result to the value of the referenced object. Here, the atomic fetch_add is used to sum all the subgroup values into temp_sum variable.
if (tile_sg.get_local_id()[0] == 0) {
atomic_ref<double, memory_order::relaxed, memory_scope::device, access::address_space::global_space> at_sum{*sum};
at_sum.fetch_add(temp_sum);
}
The above code snippet depicts the Jacobi iterative code before optimization. The optimized implementation removes fetch_add from the code and directly adds the value of temp_sum to global variable at_sum.
if (tile_sg.get_local_id()[0] == 0) {
atomic_ref<double, memory_order::relaxed, memory_scope::device,
access::address_space::global_space>
at_sum{*sum};
at_sum += temp_sum;
}
By removing fetch_add reduction of approximately 5% has been observed in the runtime of the application on Intel GPU..
The previous code depicts the Jacobi SYCL optimized code.
The SYCL migrated optimized code for Jacobi iterative can be found at sycl_migrated_optimized.
Source Code Links
| CUDA source | Github link |
| SYCL source—manual migration 1-1 mapping | Github link |
| SYCL source—manual migration with optimization applied | Github link |
| SYCL source—DPCT output with unmigrated code | Github link |
| SYCL source—DPCT output with implemented unmigrated code | Github link |
References

