Intel-Optimized Machine Learning Libraries
Scikit-learn
Scikit-learn is a popular open-source machine learning (ML) library for the Python programming language. It features various classification, regression, and clustering algorithms, including support vector machines, random forests, gradient boosting, k-means, and DBSCAN, and is designed to interoperate with the Python numerical and scientific libraries NumPy and SciPy.
The Intel® Extension for Scikit-learn, made available through Intel® oneAPI AI Analytics Toolkit, boosts ML performance and gives data scientists time back to focus on their models. Intel has invested in optimizing performance of Python itself, with the Intel® Distribution for Python, and has optimized key data science libraries used with scikit-learn, such as XGBoost, NumPy, and SciPy. This article gives more information on installing and using these extensions.
TensorFlow
TensorFlow is another popular open-source framework for developing end-to-end ML and deep learning (DL) applications. It has a comprehensive, flexible ecosystem of tools, libraries, and community resources that let researchers easily build and deploy applications.
To take full advantage of the performance available in Intel® processors, TensorFlow has been optimized using Intel® oneAPI Deep Neural Network Library (oneDNN) primitives. For more information on the optimizations as well as performance data, refer to TensorFlow Optimizations on Modern Intel® Architecture.
Databricks Runtime for Machine Learning
Databricks is a unified data analytics platform for data engineering, ML, and collaborative data science. It offers comprehensive environments for developing data-intensive applications. Databricks Runtime for Machine Learning is an integrated end-to-end environment, incorporating managed services for experiment tracking, model training, feature development and management, and feature and model serving. It includes the most popular ML/DL libraries, such as TensorFlow, PyTorch, Keras, and XGBoost, and also includes libraries required for distributed training, such as Horovod.
Databricks has been integrated with Amazon Web Services, Microsoft Azure, and Google Cloud Platform service. These cloud service providers bring great convenience to manage production infrastructure and run production workloads. Though cloud services are not free, there are opportunities to reduce the cost for ownership by utilizing the optimized libraries. In this article, we will use Databricks on Azure to demonstrate the solution and the performance results we achieved.
Intel Optimized ML Libraries on Azure Databricks
Databricks Runtime for ML includes the stock versions of scikit-learn and TensorFlow. To boost performance, however, we will replace them with Intel-optimized versions. Databricks provides initialization scripts to facilitate customization. They run during the startup of each cluster node. We developed two initialization scripts to incorporate the Intel-optimized versions of scikit-learn and TensorFlow, depending on whether you want to install the statically patched version or not:
- init_intel_optimized_ml.sh installs statically patched scikit-learn and TensorFlow in the runtime environment
- init_intel_optimized_ml_ex.sh installs Intel Extension for Scikit-learn and TensorFlow in the runtime environment.
The following instructions show how to create a cluster. First, copy the initialization script to DBFS:
- Download either init_intel_optimized_ml.sh or init_intel_optimized_ml_ex.sh to a local folder.
- Click the Data icon in the left sidebar.
- Click the DBFS button and then Upload button at the top.
- Select a target directory, for example, FileStore, in the Upload Data to DBFS dialog.
- Browse to the local file previously downloaded in the local folder to upload in the Files box.
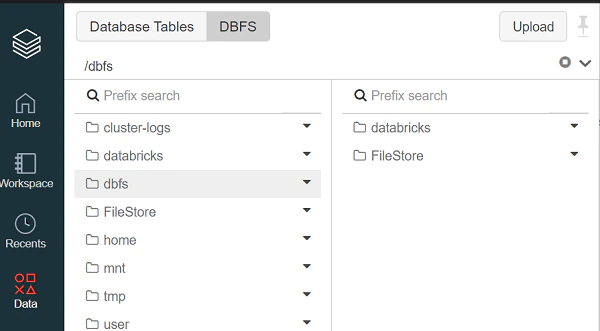
Next, launch the Databricks cluster using the uploaded initialization script:
- Click the Advanced Options toggle on the cluster configuration page.
- Click the Init Scripts tab at the right bottom.
- Select the DBFS destination type in the Destination drop-down menu.
- Specify the path to the previously uploaded initialization script dbfs:/FileStore/init_intel_optimized_ml.sh or dbfs:/FileStore/init_intel_optimized_ml_ex.sh.
- Click Add.
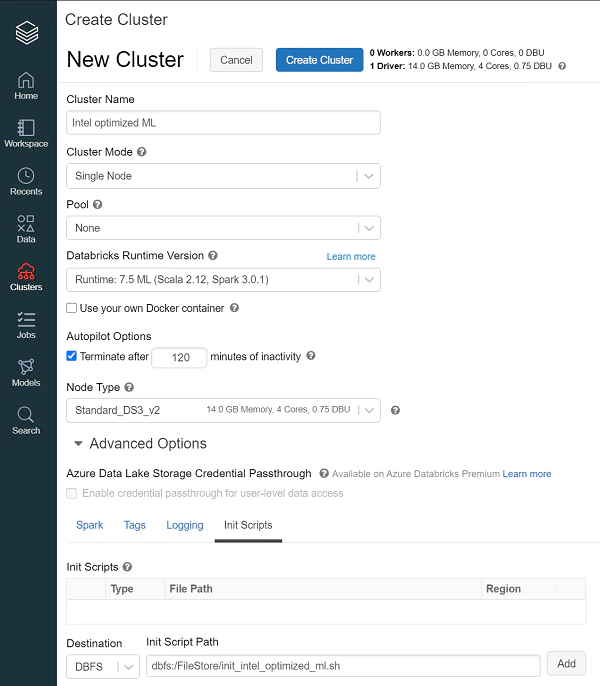
Refer to Intel Optimized ML for Databricks for more detailed information.
Performance Measurements
Scikit-learn Training and Prediction Performance
We used Databricks Runtime Version 7.6 ML for the following benchmarks. We use scikit-learn_bench to compare the performance of common scikit-learn algorithms with and without the Intel optimizations. For convenience, the benchmark_sklearn.ipynb notebook is provided to run scikit-learn_bench on Databricks Cloud.
We compared training and prediction performance by creating one single-node Databricks cluster with the stock library and another with the Intel-optimized version. Both clusters used Standard_F16s_v2 instance type.
The benchmark notebook was run on both clusters. For each algorithm, we set multiple configurations to get accurate training and prediction performance data, and below (Table 1) shows the performance data of one configuration for each algorithm.
| Algorithms | Input Config | Training Time (seconds) | Prediction Time (seconds) |
| | | Stock scikit-learn (baseline) | Intel Extension for Scikit-learn | Stock scikit-learn (baseline) | Intel Extension for Scikit-learn |
| kmeans | config1 | 517.13 | 24.41 | 6.54 | 0.42 |
| ridge_regression | config1 | 1.22 | 0.11 | 0.05 | 0.04 |
| linear_regression | config1 | 3.1 | 0.11 | 0.05 | 0.04 |
| logistic_regression | config3 | 87.5 | 5.94 | 0.5 | 0.08 |
| svm | config2 | 271.58 | 12.24 | 86.76 | 0.55 |
| kd_tree_knn_classification | config4 | 0.84 | 0.11 | 1584.3 | 25.67 |
Table 1 Comparing training and prediction performance (all times in seconds)
For each algorithm, the Intel-optimized version of scikit-learn greatly improved training and prediction performance. For some algorithms, like svm and brute_knn, it achieved order of magnitude speed-up (Figure 1).
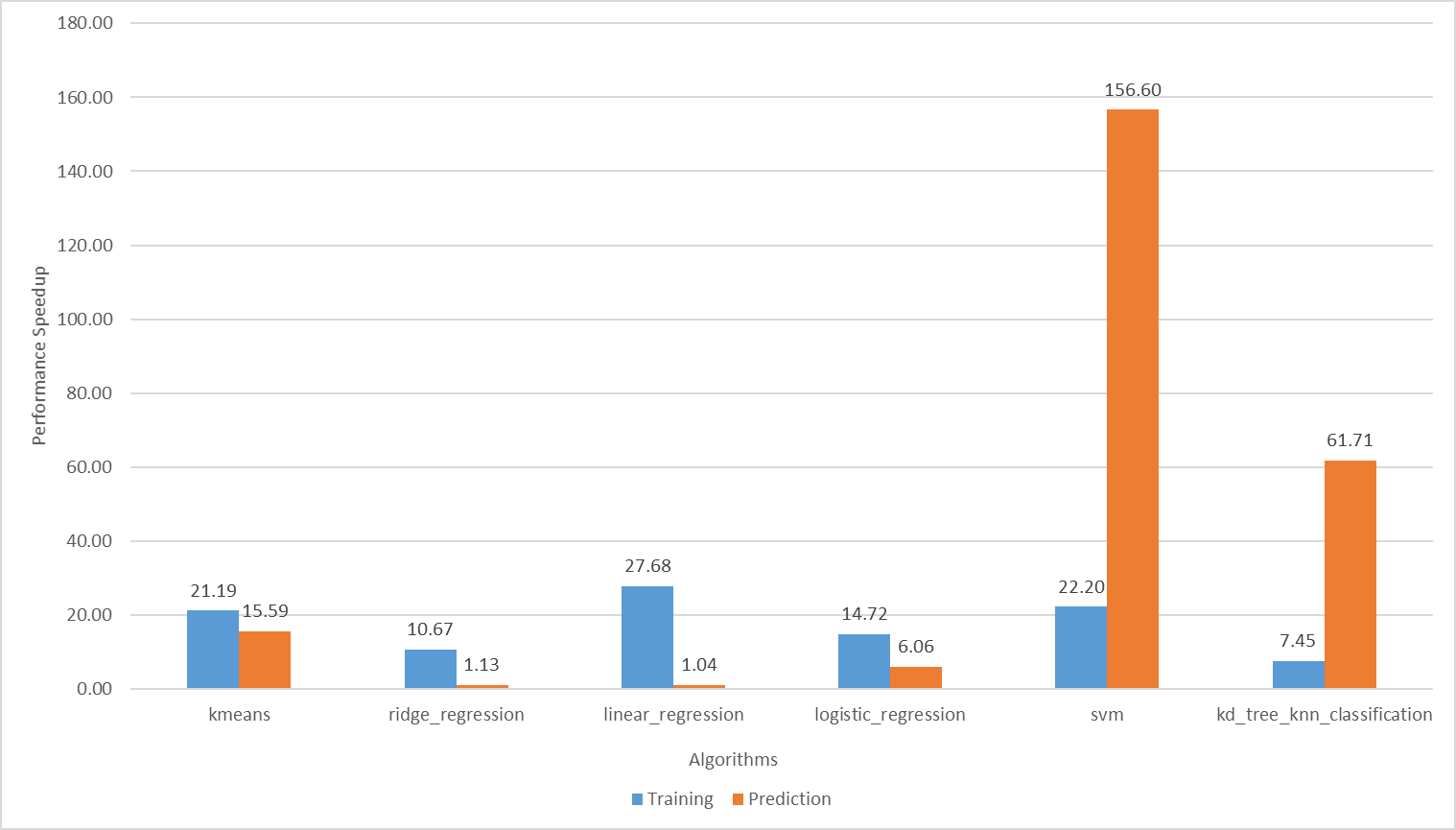
Figure 1 Training and inference speedup of the Intel-optimized scikit-learn over the stock version
TensorFlow Training and Prediction Performance
BERT, or Bidirectional Encoder Representations from Transformers, is a new method of pre-training language representations that obtains state-of-the-art results on a wide range of natural language processing tasks. Model Zoo contains links to pre-trained models, sample scripts, best practices, and step- by-step tutorials for many popular open-source machine learning models optimized by Intel to run on Intel® Xeon® Scalable processors.
We used Model Zoo to run the BERT-Large model on SQuADv1.1 datasets to compare the performance of TensorFlow with and without our optimizations. Once again, we provide a notebook (benchmark_ tensorflow_bertlarge.ipynb) to run the benchmark on the Databricks Cloud. Refer to Run Performance Comparison Benchmarks for more details.
We used Databricks Cloud Single Node with Standard_F32s_v2, Standard_F64s_v2, and Standard_F72s_v2 instance types for the TensorFlow performance evaluation. For each instance type, we compared the inference and training performance between stock TensorFlow and the Intel-optimized TensorFlow. The latter delivers 2.09x, 1.95x, and 2.18x inference performance on Databricks Runtime for ML with Standard_F32s_v2, Standard_F64s_v2, and Standard_F72s_v2 instances, respectively (Figure 2). For training, the Intel-optimized TensorFlow delivers 1.76x, 1.70x, and 1.77x training performance on Standard_F32s_v2, Standard_F64s_v2, and Standard_F72s_v2 instances, respectively (Figure 3).
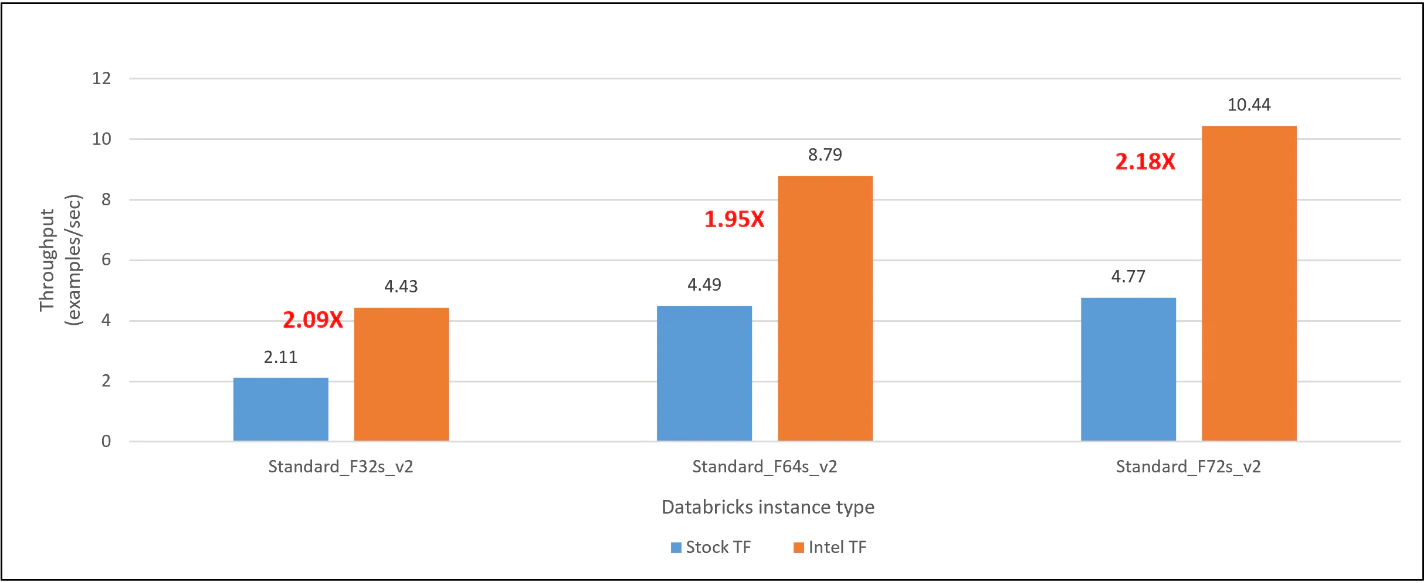
Figure 2 Inference speedup of the Intel-optimized TensorFlow over the stock version
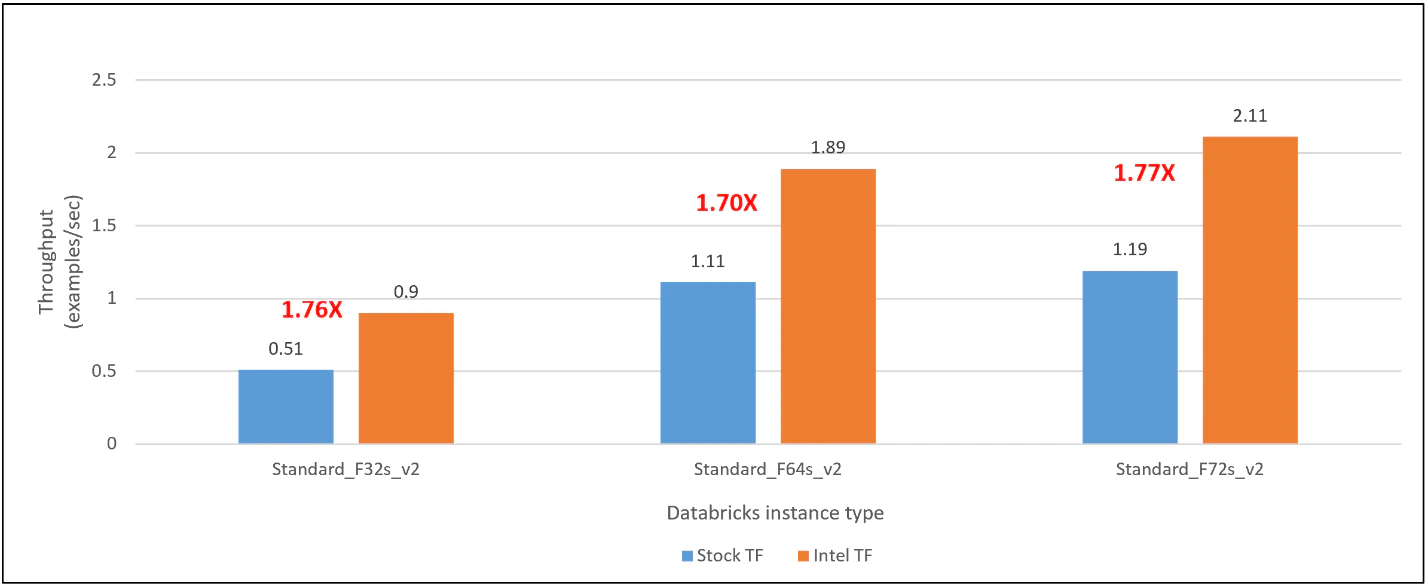
Figure 3 Training speedup of the Intel-optimized TensorFlow over the stock version
Concluding Remarks
The Intel-optimized versions of scikit-learn and TensorFlow deliver significant improvements in training and inference performance on Intel XPUs. We demonstrated that replacing the stock scikit-learn and TensorFlow included in Databricks Runtime for Machine Learning with the optimized versions can improve performance and, hence, reduce cost for customers.

