Create a file with regular expressions in it, feed it to this tool, and presto! - you have instant, dependency free C code you can use to match said expression from any input stream.
Introduction
Update: Generates more compact code in most cases.
Update 2: Fixed bug with blockend generation.
Update 3: Changed name of XXXX_capture_t to XXXX_match_t.
Update 4: Removed prefixes from common types like match_t and added several command line options. Improved code generation a bit.
I've written so many regular expression engines and code generators for them, it's pretty much instinct at this point. I do it for fun. This time, I did it because it was useful.
I needed to steal a single field out of a JSON result I got from a REST based web service. I needed to do it from a little IoT device, and I didn't want to waste precious program space on an entire JSON library when I just needed one vital, but small piece of data.
What I needed really, was regular expressions, but I didn't want to waste space on a regular expression engine, either.
In the end, that meant a code generator that would generate matcher code, given an input regular expression. Using such an animal, I could get the regular expression capability, but just enough to do the job, without anything that isn't absolutely necessary included in the end result. Rather than feeding a regular expression to a regex engine to be processed and interpreted at runtime, we have code that's cooked to match a hard coded regular expression, and doesn't actually have to be interpreted at runtime.
Understanding this Mess
rxcg is a table driven DFA/non-backtracking code generator. This generates code that runs in O(n) complexity where n is the length of the input string. Overall, that means it only visits each exactly once as it moves from left to right in the stream.
It also means it uses an array/table of data to drive the match rather than hard coded gotos. This trades some speed (in some cases) for size, given that the array based technique renders a smaller flash footprint but may not run absolutely as fast as a goto based orchestration.
This is a no frills setup, in order to keep the final code simple and efficient. It does not support subcapturing groups. You can group, but that just changes operator precedence. It does not subcapture into a group. It does not support anchors such as ^ or $. It does support Unicode, all the way up to UTF-32, and common character classes, including the Unicode ones likes IsLetter and IsDigit.
For flexibility, it uses a callback to retrieve the next UTF-32 codepoint in the input stream. You are responsible for implementing the callback function to retrieve your data, whether it's from a file, a string, or a network. This also means it's your job to turn your stream into UTF-32 codepoints, how ever you can. Fortunately, the generator provides such code and I've included the code in the example that will do that from a UTF-8 or ASCII file or string.
The input file is in the Reggie/Rolex file format.
It is a line based format where each line is formed similar to the one that follows:
CIdent<ignoreCase>= '[A-Z_][0-9A-Z_]*'
or more generally as EBNF:
identifier [ "<" attributes ">" ] "=" ( "'" regexp "'" | "\"" literal "\"" )
Each attribute is an identifier followed optionally by = and a JSON style string, boolean, integer or other value. If the value isn't specified, it's true meaning ignoreCase above is set to true. Note how literal expressions are in double quotes and regular expressions are in single quotes!
There are a couple of available attributes, listed as follows:
ignoreCase - Indicates that the expression should be interpreted as case-insensitiveblockEnd - Indicates a multi-character ending condition for the specified symbol. When encountered, the matcher will continue to read until the blockEnd value is found, consuming it. This is useful for expressions with multiple character ending conditions like C block comments, HTML/SGML comments and XML CDATA sections. Remember to use double quotes if the blockEnd is a string, or single quotes if it's a regular expression.
The regular expression language supports as above basic non-backtracking constructs and common character classes, as well as [:IsLetter:]/[:IsLetterOrDigit:]/[:IsWhiteSpace:]/etc. that map to their .NET counterparts. Make sure to escape single quotes since they are used in the file to delimit expressions.
The tool is a command line based application that takes an input file and an optional /size <capture_size> argument from which it generates two files: Name.h and Name.c where Name is the name of the input file. For MyMatch.rl, the tool would generate MyMatch.h and MyMatch.c.
The /size argument indicates the size of the capture buffer. When matching, the matched text codepoints are returned, but they can't be greater than the indicated size or the capture will be clipped. This can be a numeric value, or the name of a #define'd macro like CAPTURE_SIZE.
The code generator itself is written in C# and uses my FastFA regular expression engine, which is also used in my other project Reggie. In fact, I shamelessly ripped off a ton of that code to use in this project, so go to that link for a rundown. I could have written a Reggie plugin to do this, but honestly, Reggie is a bit heavy handed for this, and I wanted to pare it down some, especially for IoT, where doing things like lexing is counterproductive.
Using this Mess
The command line tool is simple enough. Let's start with the using screen:
Usage: rxcg.exe <input> [/size <capture_size>] [/ifstale] [/stdint] [/prefix]
<input> The input file to use
<capture_size> The size of the capture
buffer. Default is 256
<ifstale> Only generate if source
is newer than target
<prefix> Generate a prefix for
the match struct
<stdint> Use <stdint.h>
The first parameter is required, and is the input file in Rolex lexer format as described above. The rest of the parameters are optional:
<capture_size> can be a literal value, or a preprocessor macro that indicates the size of the capture buffer.<ifstale> will skip the generation of the source files unless the input is newer than the ouput.<prefix> will put the name of the file before common times like match_t like previous versions did.<stdint> will cause the generated code to use <stdint.h> for its numeric types.
Coding this Mess
Using the generated code first involves making a callback. This is easy if you only care about 7-bit ASCII and you cheat by casting each ASCII character to int32_t, but for Unicode support, some actual work is required on your part.
The example project includes two basic callback implementations - one for a string and one for a file. In each case, we need to track the input and where we are within it so we can return the next character each time we're called, or -1 when the end is reached. These implementations are also provided as part of the generated code but #if 0'ed out.
Here's the string implementation:
typedef struct string_cb_state {
char* sz;
} string_cb_state_t;
int32_t string_callback(
unsigned long long* out_advance,
void* state) {
string_cb_state_t* ps = (string_cb_state_t*)state;
int32_t cp;
if (!*ps->sz) {
*out_advance = 0;
return -1;
}
uint8_t byte = (uint8_t)*ps->sz;
if ((byte & 128) == 0) {
cp = ((uint32_t) *ps->sz & ~128);
*out_advance = 1;
}
if ((byte & 224) == 192) {
cp=((uint32_t) ps->sz[0] & ~224) << 6 |
((uint32_t) ps->sz[1] & ~192);
*out_advance = 2;
}
if ((byte & 240) == 224) {
cp=((uint32_t) ps->sz[0] & ~240) << 12 |
((uint32_t) ps->sz[1] & ~192) << 6 |
((uint32_t) ps->sz[2] & ~192);
*out_advance = 3;
}
if ((byte & 248) == 240) {
cp=((uint32_t) ps->sz[0] & ~248) << 18 |
((uint32_t) ps->sz[1] & ~192) << 12 |
((uint32_t) ps->sz[2] & ~192) << 6 |
((uint32_t) ps->sz[3] & ~192);
*out_advance = 4;
}
ps->sz+=*out_advance;
return cp;
}
Most if this mess is dealing with Unicode. Aside from that, all we're doing is advancing the pointer in state which is of type string_cb_state_t, and return -1 when we're through.
The file one is similar, although in some ways simpler, since the state is simply a FILE handle and it keeps and advances its own cursor. Note that on Arduino, you'd use a File object and work with that instead, but the example is standard C.
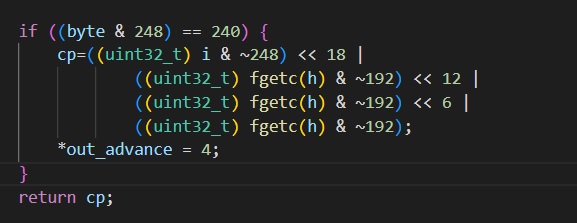
int32_t file_callback(
unsigned long long* out_advance,
void* state) {
FILE* h = (FILE*)state;
int32_t cp;
int i = fgetc(h);
if (i==-1) {
*out_advance = 0;
return -1;
}
uint8_t byte = (uint8_t)i;
if ((byte & 128) == 0) {
cp = ((uint32_t) i & ~128);
*out_advance = 1;
}
if ((byte & 224) == 192) {
cp=((uint32_t) i & ~224) << 6 |
((uint32_t) fgetc(h) & ~192);
*out_advance = 2;
}
if ((byte & 240) == 224) {
cp=((uint32_t) i & ~240) << 12 |
((uint32_t) fgetc(h) & ~192) << 6 |
((uint32_t) fgetc(h) & ~192);
*out_advance = 3;
}
if ((byte & 248) == 240) {
cp=((uint32_t) i & ~248) << 18 |
((uint32_t) fgetc(h) & ~192) << 12 |
((uint32_t) fgetc(h) & ~192) << 6 |
((uint32_t) fgetc(h) & ~192);
*out_advance = 4;
}
return cp;
}
After the string one, this one should be obvious.
Note that all of these routines assume the stream is either 7-bit ASCII or valid UTF-8. No checking is done so Very Bad Things(TM) can happen, particularly with the string callback if an otherwise invalid stream is fed to it.
Let's explore how to use it now.
For each named regular expression in the input file, a function called match_Name() is generated, where Name is the name on the left hand side of the = in the input file.
Consider the following line in the file Example.rl:
Identifier = '[_[:IsLetter:]][_[:IsLetterOrDigit:]]*'
This will generate a function named match_Identifier() which can then be used to find strings that match that Unicode expression.
int main(int argc, char** argv) {
char* test =
"a1234 foobar /*5678 abc123 */ -";
unsigned long long pos = 0;
string_cb_state_t st;
st.sz = test;
while (1) {
match_t c =
match_Identifier(&pos,
string_callback,
&st);
if (0 == c.length) {
return 0;
}
for(int i = 0;i<c.length;++i) {
printf("%c",(char)c.capture[i]);
}
printf("\n");
}
}
The idea here is to call the match function over and over, each time getting a new match_t until one comes back with a length of 0, indicating that the end of the input was reached.
Note that the capture buffer itself consists of int32_t values, not char like one might expect. This matcher captures UTF-32 codepoints, not characters. That accounts for the code near the end to loop through and print the contents of capture. Note also that the capture buffer is not null terminated.
Note: You should define ARDUINO as a constant on your compiler's command-line if you want to use this with the Arduino framework. In the alternative, modify the generated header to unconditionally #include <Arduino.h>, or just make sure it's included after Arduino.h.
Points of Interest
This code generates the smallest element type necessary to hold the DFA arrays. That means if it's an ASCII expression and the state machine is small enough, it will use int8_t as the array element type. Otherwise, it will use int16_t or int32_t as necessary. One matcher routine is used per array type. This means between 1 and 3 matcher implementations will be generated to handle all of the matches. They're all nearly identical, and here's what they look like, with block end code included:
(Forgive the wrapping, this routine is long and deep.)
match_t Example_runner32(int32_t* dfa, int32_t* blockEnd,
unsigned long long* position, Example_callback callback, void* callback_state) {
match_t result;
result.position = 0;
result.length = 0;
unsigned long long adv = 0;
int tlen;
int32_t tto;
int32_t prlen;
int32_t pmin;
int32_t pmax;
int32_t i, j;
int32_t ch;
int32_t state = 0;
int32_t acc = -1;
int done;
unsigned long long cursorPos = *position;
ch = callback(&adv, callback_state);
while (ch != -1) {
result.length = 0;
result.position = cursorPos;
acc = -1;
done = 0;
while (!done) {
start_dfa:
done = 1;
#if defined(ARDUINO) && !defined(CORE_TEENSY) && !defined(ESP32)
acc = (int32_t)pgm_read_dword((uint32_t*)(dfa + (state++)));
tlen = (int32_t)pgm_read_dword((uint32_t*)(dfa + (state++)));
#else
acc = dfa[state++];
tlen = dfa[state++];
#endif
for (i = 0; i < tlen; ++i) {
#if defined(ARDUINO) && !defined(CORE_TEENSY) && !defined(ESP32)
tto = (int32_t)pgm_read_dword((uint32_t*)(dfa + (state++)));
prlen = (int32_t)pgm_read_dword((uint32_t*)(dfa + (state++)));
#else
tto = dfa[state++];
prlen = dfa[state++];
#endif
for (j = 0; j < prlen; ++j) {
#if defined(ARDUINO) && !defined(CORE_TEENSY) && !defined(ESP32)
pmin = (int32_t)pgm_read_dword((uint32_t*)(dfa + (state++)));
pmax = (int32_t)pgm_read_dword((uint32_t*)(dfa + (state++)));
#else
pmin = dfa[state++];
pmax = dfa[state++];
#endif
if (ch < pmin) {
break;
}
if (ch <= pmax) {
if (result.length < 256) {
result.capture[result.length++] = ch;
}
ch = callback(&adv, callback_state);
++cursorPos;
state = tto;
done = 0;
goto start_dfa;
}
}
}
if (acc != -1) {
if (blockEnd != NULL) {
state = 0;
while (ch != -1) {
acc = -1;
done = 0;
while (!done) {
start_block_end:
done = 1;
#if defined(ARDUINO) && !defined(CORE_TEENSY) && !defined(ESP32)
acc = (int32_t)pgm_read_dword((uint32_t*)
(blockEnd + (state++)));
tlen = (int32_t)pgm_read_dword((uint32_t*)
(blockEnd + (state++)));
#else
acc = blockEnd[state++];
tlen = blockEnd[state++];
#endif
for (i = 0; i < tlen; ++i) {
#if defined(ARDUINO) && !defined(CORE_TEENSY) && !defined(ESP32)
tto = (int32_t)pgm_read_dword((uint32_t*)
(blockEnd + (state++)));
prlen = (int32_t)pgm_read_dword((uint32_t*)
(blockEnd + (state++)));
#else
tto = blockEnd[state++];
prlen = blockEnd[state++];
#endif
for (j = 0; j < prlen; ++j) {
#if defined(ARDUINO) && !defined(CORE_TEENSY) && !defined(ESP32)
pmin = (int32_t)pgm_read_dword((uint32_t*)
(blockEnd + (state++)));
pmax = (int32_t)pgm_read_dword((uint32_t*)
(blockEnd + (state++)));
#else
pmin = blockEnd[state++];
pmax = blockEnd[state++];
#endif
if (ch < pmin) {
break;
}
if (ch <= pmax) {
if (result.length < 256) {
result.capture[result.length++] = ch;
}
ch = callback(&adv, callback_state);
++cursorPos;
state = tto;
done = 0;
goto start_block_end;
}
}
}
}
if (acc != -1) {
return result;
}
else {
if (result.length < 256) {
result.capture[result.length++] = ch;
}
ch = callback(&adv, callback_state);
++cursorPos;
}
state = 0;
}
state = 0;
continue;
}
else {
if (result.length > 0) {
return result;
}
}
}
ch = callback(&adv, callback_state);
++cursorPos;
state = 0;
}
}
result.length = 0;
return result;
}
It's provided as a curiosity for the interested reader. Note that the blockend portion is only generated if used. Anyway, we aren't going to explore it in detail because it walks arrays that are generated from the regular expression, and by the time those arrays are cooked, all of the interesting logic is baked in. Walking it is efficient, but not intuitive.
History
- 5th September, 2022 - Initial submission
- 15th September, 2022 - Made code generation more compact by eliminating blockend code if not used
- 15th September, 2022 - Fixed bug where regular match array was being generated for a blockend
- 16th September, 2022 - Changed naming slightly
- 15th November, 2023 - Added several features and changed naming

