
Introduction
Would you like to use the PyTorch API with the inference performance gains of OpenVINO™ Toolkit while making minimal code changes? Look no further because today we are pleased to announce, in collaboration with Microsoft, OpenVINO™ integration with ONNX Runtime for PyTorch (OpenVINO™ integration with Torch-ORT for short).
OpenVINO has redefined AI inferencing on Intel® powered devices and has attained unprecedented developer adoption. Today hundreds of thousands of developers use OpenVINO to accelerate AI inferencing across almost all imaginable use cases, from emulation of human vision, automatic speech recognition, natural language processing, recommendation systems, and many others. Based on the latest generations of artificial neural networks, including Convolutional Neural Networks (CNNs), recurrent and attention-based networks, the toolkit extends computer vision and non-vision workloads across Intel hardware (Intel® CPU, Intel® Integrated Graphics, Intel® Neural Compute Stick 2, and Intel® Vision Accelerator Design with Intel® Movidius™ VPUs), maximizing performance. OpenVINO accelerates applications with high-performance, AI, and deep learning inference deployed from edge to cloud.
As the OpenVINO ecosystem grows, we are hearing from PyTorch developers that you would like more seamless methods for accelerating PyTorch models. Before today PyTorch developers wanting to accelerate their models had to convert their model to ONNX and then run it with OpenVINO™ Runtime or convert the ONNX model to OpenVINO™ toolkit IR for inferencing.
This posed several issues for PyTorch developers such as
- Failed ONNX conversion due to PyTorch layers/operators unsupported by ONNX conversion
- Failed ONNX inference due to layers/operators of converted models unsupported by OpenVINO
- Extra steps required for model conversions (PyTorch -> ONNX, ONNX -> OpenVINO IR, etc.)
Why should PyTorch Developers use OpenVINO integration with Torch-ORT?
OpenVINO integration with Torch-ORT gives PyTorch developers the ability to stay within their chosen framework all the while still getting the speed and inferencing power of OpenVINO™ toolkit through inline optimizations used to accelerate your PyTorch applications.
Accelerating PyTorch with Intel® OpenVINO™ integration with Torch-ORT
- Easy Installation — Install OpenVINO integration with Torch-ORT with PIP
- Simple API — No need to refactor existing code, just import OpenVINO integration with Torch-ORT, set your desired target device to run inference and wrap your model and you are good to go!
- Performance — Achieve higher inference performance over stock PyTorch
- Support for Intel devices — Intel CPUs, Intel integrated GPUs, Intel VPUs
- Inline Model Conversion — no explicit model conversion steps required
How it Works
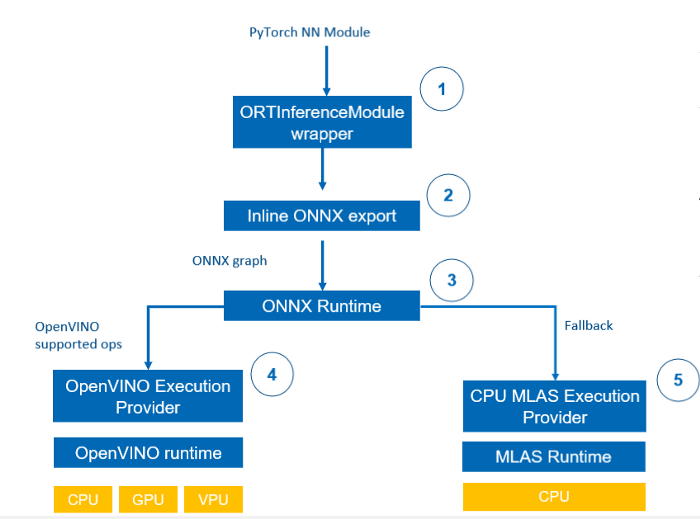
- Users will wrap their
nn.Module in torch_ort.ORTInferenceModule to prepare the module for inference using ONNX Runtime OpenVINO Execution Provider. - The module is exported to an in-memory ONNX graph using torch.onnx.export.
- An ONNX Runtime session is started and the ONNX graph is provided as an input. ONNX Runtime will Partition the graph into subgraphs with supported and unsupported operators.
- All the OpenVINO compatible nodes will be executed by the OpenVINO Execution Provider and can execute on Intel CPUs, GPUs, or VPUs.
- All the other nodes will fallback onto the default CPU MLAS Execution Provider. The CPU MLAS Execution Provider will invoke ONNX Runtime’s own CPU kernels for nodes in the default operator set domain.
Developer Experience
Getting started with OpenVINO integration with Torch-ORT is easy as it follows PyTorch idioms. Below is a code snippet of taking a pretrained NLP BERT model from HuggingFace Transformers and making it compatible with OpenVINO™ integration with Torch-ORT Code Sample
Below are code snippets
Install:
pip install torch-ort-infer[openvino]
python -m torch_ort.configure
Define Model:
from torch_ort import ORTInferenceModule
model = ORTInferenceModule(model)Provider options for different devicesfrom torch_ort import ORTInferenceModule, OpenVINOProviderOptions
provider_options = OpenVINOProviderOptions(backend = "GPU", precision = "FP16")
model = ORTInferenceModule(model, provider_options = provider_options)
Code Sample:
By simply wrapping your nn.Module with ORTInferenceModule you can obtain the benefits of OpenVINO acceleration.
from transformers
import AutoTokenizer, AutoModelForSequenceClassification
import numpy as np
from torch_ort import ORTInferenceModuletokenizer = AutoTokenizer.from_pretrained(
"textattack/bert-base-uncased-CoLA")
model = AutoModelForSequenceClassification.from_pretrained(
"textattack/bert-base-uncased-CoLA")
model = ORTInferenceModule(model)text = "Replace me any text by you'd like ."
encoded_input = tokenizer(text, return_tensors='pt')
output = model(**encoded_input)
logits = output.logits
logits = logits.detach().cpu().numpy()
pred = np.argmax(logits, axis=1).flatten()
print("Grammar correctness label (0=unacceptable, 1=acceptable)")
print(pred)
Full code sample can be found here.
With two lines of code OpenVINO integration with Torch-ORT can help ensure you are getting outstanding inference performance and are leveraging much of what the full OpenVINO toolkit provides. If you are interested in trying it please check out the Github repository and read the detailed documentation available here.
What more you can expect from us:
- Additional code samples (Python scripts, Jupyter Notebooks)
- More TorchVision and HuggingFace Transformers model coverage
Get Started with Intel® DevCloud for the Edge
Intel® DevCloud for the Edge is a cloud development environment that enables developers to develop, and benchmark performance of AI and Computer Vision solutions on Intel Hardware with minimal setup. The Devcloud for the Edge comes pre-installed with OpenVINO™ intergration with Torch-ORT [Beta] with code snippets to help accelerate your development journey. To get started follow the steps below:
Step 1. Register and login for FREE access here
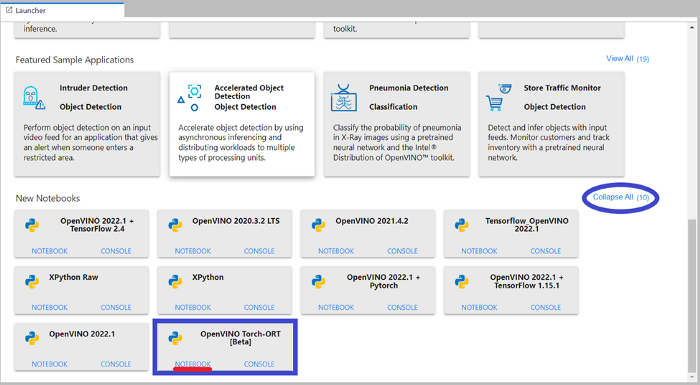
Step 2. Scroll down and Select the OpenVINO™ integration Torch-ORT [beta] Notebook
Step 3. Open Code Snippets, search for “OpenVINO™ integration with Torch-ORT [beta]”, Drag and drop Code snippet into notebook
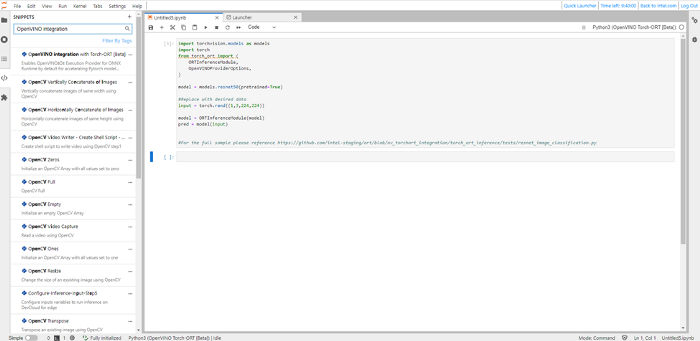
Step 4. Run Cell
If you run into any issues, please contact Intel® DevCloud Support Team.
Resources
Notices and Disclaimers:
Intel technologies may require enabled hardware, software or service activation.
No product or component can be absolutely secure.
Your costs and results may vary.
© Intel Corporation. Intel, the Intel logo, and other Intel marks are trademarks of Intel Corporation or its subsidiaries. Other names and brands may be claimed as the property of others.

