
It’s been a few months since I started my journey here at Intel, and I’m so excited to share with you all what I have been working on. Today, I will walk you through my first notebook on human action recognition. I hope you enjoy it and can apply it in your ongoing developments.
In this blog, you will learn how to work with live human action recognition using the OpenVINO™ AI toolkit in a synchronized schedule.
Human action recognition is an AI capability that can find and categorize an extensive set of activities within a recorded or live video. For example, if you have a large family video collection, and you want to find a specific memory, human action recognition is the simplest and fastest way to do so. Traditional methods would require you to spend a lot of manual effort and time reviewing every video you have until you find the right one. Using human action recognition, you can train AI models to automatically categorize and organize your videos by their recorded activities for you, making it easier to find and access your most cherished memories in a matter of seconds.
This action can also be applied to businesses like manufacturing. For instance, providing human workers with solutions that can recognize their performed tasks, gesture for feedback, and keep them safe by recognizing and alerting managers of any hazards.
But these are just a few examples of what human action recognition can do. Over the next few years, I expect to see a lot more new and exciting use cases in this field. Let me know what other areas you imagine could benefit from this AI capability after running through this notebook. But for now, let’s get started.
About this notebook
For this notebook, I am using the DeepMind Kinetics-400 human action video dataset, which contains 400 actions in total, including Person Actions (e.g., writing, drinking, laughing), Person-Person Actions (e.g., hugging, shaking hands, playing poker), and Person-Object Actions (riding a scooter, doing laundry, blowing a balloon). You can also distinguish a group of Parent-Child interactions, such as braiding or brushing hair, salsa or robot dancing, and playing the violin or the guitar (Figure 1). For more information about the labels and the dataset, see “The Kinetics Human Action Video Dataset” research paper.

Figure 1. Human Action Recognition with OpenVINO™ toolkit
You can run this notebook using your general-purpose computer, no hardware accelerators are required. The great thing about using the AI toolkit OpenVINO is that it is designed to work at the edge, so GPUs, CPUs, and VPUs can be optimized for it to run your AI inference models efficiently. But again, those are not necessary. Various video sources can be used, such as a clip coming from a URL, a locally stored file, or a webcam feed.
I will also be using the Action Recognition model from Open Model Zoo, which provides a wide variety of pre-trained deep learning models and demo applications. The model I am using is based on Video Transformer, with a ResNet34 architecture (Figure 2). It contains two models:
- The Encoder, based on the PyTorch framework, with the input shape of [1x3x224x224] — 1 batch size, 3 color channels, and image dimensions of 224 by 224 pixels; and an output shape of [1x512x1x1], representing embedding of the processed frame.
- The Decoder, also based on the PyTorch framework, with the input shape of [1x16x512] — 1 batch size, 16 frames for duration of the clip in one second, and 512 dimensions of embedding.
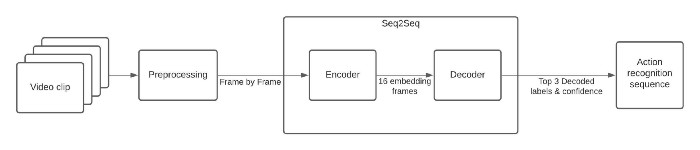
Figure 2. Pipeline of the human action recognition notebook.
I am selecting 16 frames per second to be analyzed — that is the number of frames the Kinetics-400 authors averaged to find the class score. The frames are preprocessed to analyze just the center-cropped image as you can see in the GIF in Figure 1.
Both models create a sequence-to-sequence (Seq2Seq) system to identify the human activities for the Kinetics-400 dataset. Due to a non-exhaustive annotation, the model performance is the best, but it could help us to understand the pipeline.
You can start recognizing your own videos by:
- Preparing your installation using OpenVINO Notebooks.
- Preparing your video source, a webcam or video files with your common activities that you want to detect. Consider the action names to be detected by checking the dataset labels.
- Opening a Jupyter notebook on your computer. The notebook can run under Windows, MacOS, and Ubuntu, over different internet browsers.
Live Action Recognition with OpenVINO™
Now, I will show you some highlights of the notebook:
1. Downloading the models
We are working with Open Model Zoo tools, such as omz_downloader. It is a command line tool that automatically creates a directory structure and downloads the selected model. In this case, it is the “action-recognition-0001” model from Open Model Zoo.
if not os.path.exists(model_path_decoder) or not os.path.exists(model_path_encoder):
download_command = f"omz_downloader " \
f"--name {model_name} " \
f"--precision {precision} " \
f"--output_dir {base_model_dir}"
! $download_command
2. Model initialization
To start inference, initialize the inference engine, read the network and weight from files, load the model on the chosen device — in my case, the CPU — and get input and output nodes.
ie_core = Core()
def model_init(model_path: str) -> Tuple
model = ie_core.read_model(model=model_path)
compiled_model = ie_core.compile_model(model=model, device_name="CPU")
input_keys = compiled_model.input(0)
output_keys = compiled_model.output(0)
return input_keys, output_keys, compiled_model
3. Helper functions
You need a lot of code to prepare and visualize your results. Create a crop-centered ROI, resize the image, and put text info in each frame.
4. AI Functions
Here is where the magic happens.
a. Preprocessing the frame before running the Encoder (preprocessing)
- Before passing the frame through the encoder, prepare the image — scale it to its shortest dimension, to the chosen size, by cropping, centering, and squaring it so that both width and height are equal. The frame must be transposed from Height-Width-Channels (HWC) to Channels-Height-Width (CHW).
def preprocessing(frame: np.ndarray, size: int) -> np.ndarray
preprocessed = adaptive_resize(frame, size)
(preprocessed, roi) = center_crop(preprocessed)
preprocessed = preprocessed.transpose((2, 0, 1))[None,]
return preprocessed, roi
b. Encoder Inference per frame (encoder)
- This function calls the network previously configured for the encoder model (
compiled_model), extracts the data from the output node, and appends it in an array to be used by the decoder.
def encoder(
preprocessed: np.ndarray,
compiled_model: CompiledModel
) -> List
output_key_en = compiled_model.output(0)
infer_result_encoder = compiled_model([preprocessed])[output_key_en]
return infer_result_encoder
c. Decoder inference per set of frames (decoder)
- This function concatenates the embedding layer from the encoder output and transposes the array to match the decoder input size. It calls the network previously configured for the decoder model (
compiled_model_de), extracts the logits (yes, logits are a real thing; you can find out more here) and normalizes them to get confidence values along the specified axis. It decodes top probabilities into corresponding label names.
def decoder(encoder_output: List, compiled_model_de: CompiledModel) -> List
decoder_input = np.concatenate(encoder_output, axis=0)
decoder_input = decoder_input.transpose((2, 0, 1, 3))
decoder_input = np.squeeze(decoder_input, axis=3)
output_key_de = compiled_model_de.output(0)
result_de = compiled_model_de([decoder_input])[output_key_de]
probs = softmax(results_de - np.max(result_de))
decoded_labels, decoded_top_probs = decode_output(probs, labels, top_k=3)
return decoded_labels, decoded_top_probs
Run the complete notebook pipeline
Now, let’s see the notebook in action.
- Select the video for which you would like to run the complete workflow.
video_file = "https://archive.org/serve/ISSVideoResourceLifeOnStation720p/ISS%20Video%20Resource_LifeOnStation_720p.mp4"
run_action_recognition(source=video_file, flip=False, use_popup=False, skip_first_frames=600)
- Select the webcam and run the complete workflow again.
run_action_recognition(source=0, flip=False, use_popup=False, skip_first_frames=0)
Congrats! You’ve done it. I hope you found this topic interesting and useful for your application development. 😉
To learn more about the OpenVINO toolkit and what it can do, visit https://www.openvino.ai/. For more hands-on AI training, check out our AI Dev Team Adventures.
Resources
Notices & Disclaimers
Intel technologies may require enabled hardware, software, or service activation.
No product or component can be absolutely secure.
Your costs and results may vary.
Intel does not control or audit third-party data. You should consult other sources to evaluate accuracy.
Intel disclaims all express and implied warranties, including without limitation, the implied warranties of merchantability, fitness for a particular purpose, and non-infringement, as well as any warranty arising from course of performance, course of dealing, or usage in trade.
No license (express or implied, by estoppel or otherwise) to any intellectual property rights is granted by this document.
© Intel Corporation. Intel, the Intel logo, and other Intel marks are trademarks of Intel Corporation or its subsidiaries. Other names and brands may be claimed as the property of others.

