This article introduces the Unit of Code, Web Inversion, and Virtual Source Files. It gives a high-level view of some of the broader project concepts.
Introduction/Recap
Web development is more complicated than it needs to be. One contributor is naming collision avoidance. Another is the complexity of managing CSS cascades. Underlying these and other factors is the "Too Much Stuff" factor.
A lot of the practices and approaches we use were developed in the early web days. The web was slow and unreliable, tooling was weak, and many features of the standards had limited if any support. Pages were 1-Shot (everything loaded upfront). Linked resources loaded in total, all into the same namespace. You know the problems and remedies. Every technology advancement seemed to add more to the problem - CSS Sheets kept getting bigger, scripts kept growing bigger. More scripts, more sheets... Too Much Stuff!
In its simplest form, a browser is just a viewer. Anything not seen in the view at any moment is excess baggage. The technology landscape has changed radically since the early days, but not our approaches. We still use a Big Document, document-centric approach, full of excess. I call this the "Just In Case" approach: Load everything you will need, and more (just in case) right up front. But with modern technologies, it's just as easy to load "Just In Time", resulting in faster, more dynamic, and easier to manage web applications.
Unit of Code
Before jumping into "Too much Stuff", I want to provide a brief introduction to "Unit of Code".
In it simplest form, a Unit of Code (UOC) is a sequence of instructions that will execute to completion without delay or interruption, that expresses a single, identifiable purpose or "thought".
Simplified: Continuous, related lines of code that do not branch (including calls and new) or block, that we can name. Fragments and Directives are associated with UOCs.
The UOC is a "fundamental particle" - all code can be expressed in terms of UOC groupings and hierarchies. A "simplest" UOC has limited value - Code that can't create anything or call anything doesn't have many compelling use-cases. If you remember the whole Machine thing, we can see this as - machine (the abstraction), workspace (below), instructions (UOC steps). A UOC Machine runs in three steps:
- Init - Init sets up the environment. It sets variables, and can go outside to get values. It can get objects, but using an object (read its values) in an UOC would require some kind of interruption/call. Required values must be extracted into local value types.
This is the WorkSpace. - Run - The UOC runs, altering local value types. This is the "run uninterrupted" part.
Revisiting Work: Work is a Resource expending Energy, to execute Instructions, to effect desired Change. - Alter Resources - This is the "desired Change". We need to change something external to be useful. (Technically, we tell the resource to change. We can't change things we don't own.)
Work/Energy here includes the same Work/Energy ideas from classical physics. Most of the standard equations apply. The equations are expressed in value|measure sets (4 | meters). One purpose for creating the UOC is to provide a "Software Standard Unit" for developing measurable dimensions of work/code for use in these and other equations. That's not very import here, but crucial to planning and management. Many approaches put management/profiling metrics "over" methodologies. Here it is built-in, from the ground up.
All software is a composition of UOCs, that (each) have defined, standard measurable aspects.
If all the "parts" are measurable, the "whole" should be measurable, and any section should also be measurable. UOC's provide more useful metrics than "Number of Lines of Code".
A UOM Machine can be (partially) represented by the image below. "Unit of Code" is replaced with the name/identifier. The number (1, here) defines the position in the hierarchy. Two formats for hierarchies are dotted (1.1.2.3) or slashed (/1/1/2/3/).
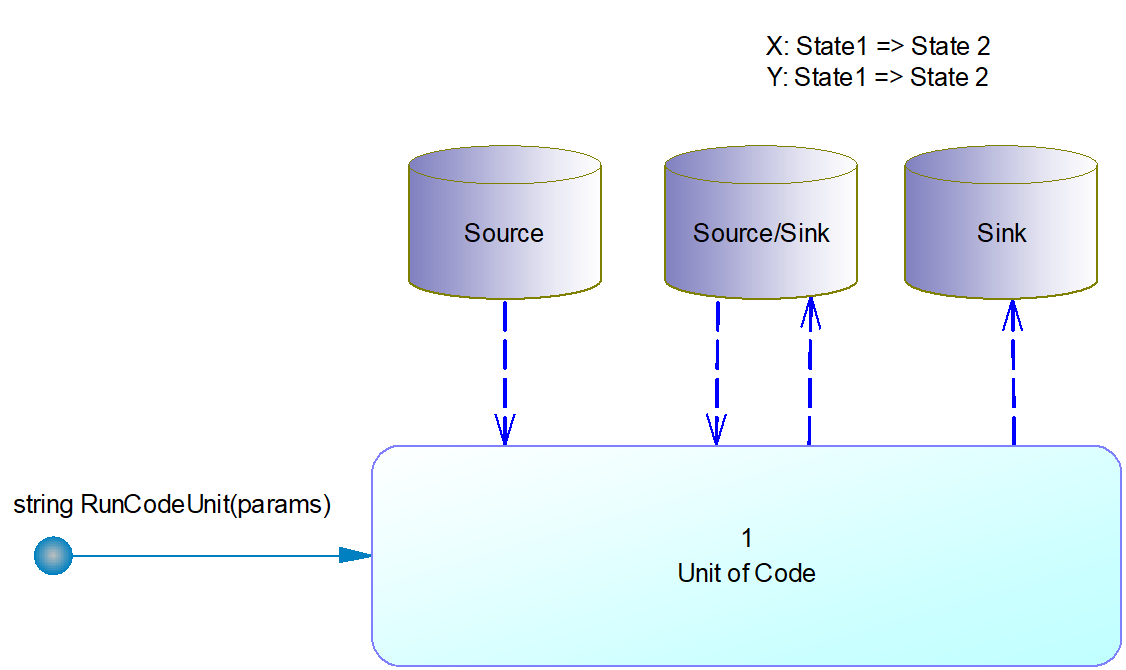
This final UOC section is just informational, but worth introducing.
We can define a UOC from two perspectives:
- The Method perspective - "Do your job with these items and give me the result".
- The Change perspective - "Change Items X,Y in this way".
"Wash the dishes and put them away." - Method
"Change the dirty dishes in the sink into clean dishes on the shelf." - Change
Let's look at UOC Perspectives for these dishes.
Method Perspective
The Method Perspective specifies through Action.
The actions are identified by Signature. The signature contains a name that should describe what it does, a list of inputs, and a single (possibly compound) return item;
The method perspective viewer is aware of two "actions" - Wash.., PutAway...
It initiates actions and processes results. This is a Push approach.
To know more than the public interface, the viewer has to look inside or have prior knowledge.
The signature says nothing about what it changes.
Functional Analysis has the concept of a Pure Function - a function that only returns a value and alters nothing. It "has no Side Effects".
Using the Method Perspective:
Dishrack.Dishes = WashDishes(Sink.Dishes);
Shelf.Dishes = PutAway(Dishrack.Dishes);
Change Perspective
The change perspective specifies with Alteration.
It can only alter existing resources, never create.
Alterations are also identified by signature.
The signature defines the items that will be read and/or changed and a return value if any.
Alterations also have a Pure Alteration, that only alters and returns nothing.
The CP viewer sees "data ports". It responds to changes on the data port.
It does not see (or have a way to) start the process.
Alteration is reactive and can be styled as a Pull process. The desired changes are specified by the "desires" of the code/processes that use it.
Using the Change Perspective:
result/void = DoDishes(in Sink.Dishes, out Shelf.Dishes);
Fusion
Neither approach provides a comprehensive view of the work. But the non-Pure versions obscure more information than the Pure versions. The UOC is a combination of the Pure Versions.
Method Side: Used for flow control only. Business Data is never returned, only status information.
Change Side: Only Alters Resources.
There's more, but for this article the important part is that we can compose increasingly complex software structures/components from Units of Code and "Grouped" UOC's.
UOCs come up later here and in other articles.
Inversion
Now, about that Stuff...
Web Inversion is a concept that flips a few aspects of web architecture. This section walks through the inversion concept.
Current
A basic web application looks something like this:

A browser invokes a GET operation on a web server, that returns an HTML Document. The document contains a lot of stuff. But apparently not enough. Links pull in more. Unless you own the link, links are risky business. Over the past couple of years, several stories related to links breaking thousands of web sites have made world news. I think most telling about the current state of web development is the thousands of sites (some from major players) that went down when a developer pulled his "library" code. His one line of code library. Developers that copy-paste others code are bad enough, but at least they see what they are putting in their apps, and "make it their own". Blindly linking is bad, but linking to a single, external line of code is inexcusable.
There are many variations on this. Linking a large library for a single function, or in C# using an entire namespace for a small, uncoupled class - if it's open source - copy and attribute to the source! Make code yours. You are free from forced changes and their impact. Assess changes to the source and incorporate accordingly.
The things we put in the browser have different impacts. Some just take a little more memory and bandwidth. Others impact background processing. Some steal resources from the main thread. In fact, almost everything is going to steal something from the main thread.
The main thread is becoming more overburdened as GUIs get more animated and interactive. A customer comes to you and says, "Build a pretty animated, application for me that implements these business functions. Oh, and deliver it in chunks of code that each run in about 10 milliseconds". Does that constraint sound familiar? As CSS adds more, and more complex, "transitions over time" browsers are becoming video players in addition to everything else. They have built-in support, all the way down to frame-based clocks. To prevent video stutter, your business logic can only use the thread for the time the browser doesn't need it, on each frame - a few milliseconds.
We need to get stuff off the main thread. Two things can do this are:
- Remove stuff we don't need at the moment.
- Shift processing.
We can do these together.
Intermediate
There are several ways to remove code and a few places to move it. There are priorities for which code to move - reducing the DOM size offers some of the best gains.
One way to get this off main is with Web Workers. It's common for workers to use a Remote Procedure Call approach. Creating workers isn't cheap though - you wouldn't move every function into its own worker. Some code moves better than other. Workers can't use the Window DOM. Makes sense. But Workers have no concept of HTML or even XML. No XML Support makes no sense - not every hierarchy is an HTML Document, and not every HTML Document is "live".
Code can be moved off the DOM, but remain in the Window/EC. We can create WebAPIs backed by Server Processes, not Browser Executive Processes, to help.
Web Content falls into three categories: HTML, JavaScript, CSS.
All have major sub-categories.
- Markup (HTML)
- Custom Elements (HTML/JS)
- Script (JS)
- Classes (JS)
- Skeleton (CSS)
- Skin (CSS)
I avoid mixing CSS that affects box layout (Skeleton) with styling/theming (Skin) CSS. Especially when using the CSSOM and dynamic styling.
We can create WebAPIs around these items. I use Elements, Classes, Sheets, and some type of Controller APIs. But there is no standard or framework. We can move code into the API instances. Idle code is still in the browser, but not on the critical path. Through the API we can move it off the browser and onto the server, sending to the browser on-demand. Some code can be moved and executed on the server, sync'ing over a realtime connection. The Web Server can host logic (Business Service shown), or it can be moved to out-of-web-process services.
Whole-file content can be moved around, but we can also just send "Only what we need, and only when we need it". The server balances the workload of the browser by moving dynamically constructed "pieces" in and out of the API implementations in realtime. To do this, we need a good approach for "managing the pieces".
Software Manufacturing
I spent a lot of time in manufacturing environments. Without a doubt - Software Development is a Manufacturing Process. Not Art or Science! (OK, It's a mix. But it's not a "Craft" unless you're a pre-industrial "Code Cobbler"). In other articles, I will show how a Lean Manufacturing (aka Toyota) approach is a better fit for modern (especially business) software than Stage-Gated (aka Waterfall) or Agile (aka (to me) Freefall) approaches. You may have seen the term "Kanban" related to agile approaches. Kanban is straight out of Lean Manufacturing, though slightly mal-applied.
Aside
The term "Waterfall" is a derogatory term for staged approaches. Staged approaches are iterative, but over whole stages - if the next stage doesn't accept your work, you do it again. The term Waterfall described organizations that just, "threw the work over the waterfall". The next stage couldn't "climb up the falls" to make you do it again. Waterfall is not a "failed methodology". It's about failed organizations.
I coined the term "Freefall" as the Agile equivalent. The Manifesto specifically talks about design as a "real thing", i.e., formal design documents, just lightweight. These serve as an anchor/reference. On each iteration, you update the design docs to reflect the current code (create an as-is), plan the next sprint and update a to-be specification. Then you build to the incremental to-bes. Rinse, repeat. When you hear someone say, "The Software is the Design", the organization is failed, and Freefall is pending. You'll never reach an undefined and moving target. And when there's nothing to "grab on to" (no reference design) - you're in freefall.
Other signs of failed organizations are ones that use terms like "Agile Project Management". Think about it.
Both Staged and Agile have their strengths but serve different (and complimentary) purposes - Staged is Big Picture and Agile works well for more granular work inside stages.
Parts
The Web Server is sending "parts" to the browser. The Unit of Code represents the smallest meaningful "executable" (not .exe). A Unit of Code is the smallest Part we have. It has a PartNumber. Code can be specified as a hierarchical Bill of Materials (BOM), where the materials are Units of Code and assemblies composed of UOCs. The UOCs can be "mixed-in" - ordered UOCs within containers (e.g., Method) or used as the entire body of a container.
An Abstract Syntax Tree (AST) is a BOM. If the "code result" is a BOM, Wouldn't it make sense to work with BOMs early on?
The entire tree can be constructed from the bottom up in realtime, but that isn't efficient or necessary. At each node, the Node UOCs and child nodes are assembled into a cached part.
For example, Fragments (identified by a Directive) are a UOC. We can use better directives:
class Context {
static raw = "";
static state = new Map();
static get State() { return this.raw; }
}
class Niche extends HTMLElement {...}
We could send each small part, but that could be a lot of sends. Better is to "cache". A BOM Node holds the BOM and Assembly:
Node BOM
<part name="assem" pn="xxxx" rev="current">
<part name="Context" pn="xxxx" rev="current"/>
<part name="Niche" pn="xxxx" rev="54.2.1"/>
</part>
Node Assembly
class Context {
static raw = "";
static state = new Map();
static get State() { return this.raw; }
}
class Niche extends HTMLElement {...}
Once built, an assembly only needs to be rebuilt if one of its parts changes. When a part changes, it ripples through the code. Lean principles include: "Build Quality In". Each node has built-in tests that cover (only) its behavior. If a node detects a BOM change, it reassembles and runs the tests (updated as needed).
Each node in the assembly that is updated and passes test notifies the nodes that use it. Those nodes do the same. Change ripples up, tested at each level. It's easy to identify points of failure. This should all be automated so the rippling is almost immediate. We can use "current" if we don't need a specific version of a part or a specific part number. We can build a current or any historical version of the code at any time. The is no One Version, there are BOMs of versioned parts. Every node can draw from the "current" version of its parts, any numbered version, or even One-Off custom versions.
This approach works for any development, not just JIT scenarios. There are straightforward ways to manage all of this, including a new IDE/Extension that can toggle between Sim/Test mode and Dev mode on the fly.
It is simple to manage script this way, but compiled languages are more complex. I've identified some changes that I think could improve this significantly.
Inverted
In the fully inverted model, the Window becomes nothing but a display and event source.
The BIOS immediately creates a WebWorker and hands control to the Worker. The Worker communicates with the Server and runs all business logic. It updates the Window. The Web Server is demoted to a simple bridge between the Server Logic and Worker Client Logic - two parts of a single process with a "horizontal" alignment, capable of synchronous or asynchronous operation..
The Window gets updated by the Worker through a DOM Driver. (JIT as usual). You can't get everything off the main thread, (but close), and there are some things that really do belong in the Window. Business code and display code each have their own thread. Workers can spawn other workers, so this can scale and multi-thread pretty well.
The Wrong Stuff
While working through all of this and trying to get the pieces to fit, I realized something.
We Manage the Wrong Stuff
Coding and modeling are blurred these days. We model and use models more than we may realize.
Models take many forms. Simulations and Weather Models are code-based models. TypeScript is a model of JS that gets rendered into JS. When you start a project from a template or populate a template, you are working with models. Once you start looking, models are everywhere. Modeling is even getting integrated into the build pipeline with Source Generators. The generator is a model that gets rendered before other code gets processed.
If I explained this well, you should be able to see that with BOMs, we don't need things like namespaces or source files. We certainly need Compilation Units, but do they need to be static files? And how "human readable" do they need to be?
An Item Master if a flat list of all the parts, down to the UOC, keyed by Part Number. That's all we really need. The rest is configuration management. Our source files can be virtual (Virtual Source Files), composed of parts stored in a database (or similar), and built in the IDE on the fly. Many structural/organizational decisions become easier when we don't need to worry as much about naming and namespaces. These don't go away, but they take a different form and purpose.
We shouldn't be managing static source files.
We should be managing the source of (our) virtual source files.
For Thought
If we accept that a lot of getting to a source file is modeling, managing static source files is a little like rendering the first frame of an animation and doing the rest by hand. Taking this idea a step farther (and explored in another article) is making everything "modeled".
Instead of a database or source files, all parts/UOCs can be stored as model items - good tools support full version control, backend databases, simulation, analysis, and more. Getting to the evasive Visual Coding is just a step away.
This (mostly) removes the "Human Readable Factor" from source, making it potentially more efficient.
History
- 22nd September, 2022: Original version

