This article describes how to implement a named pipe server for communicating with client applications. The server will be in its own thread and can be controlled from the main thread. Any client connections and IO will be offloaded to worker threads.
Introduction
Windows comes with a variety of ways to implement communication between processes, also known as 'Inter Process Communication' or IPC. One of these ways is called Named Pipes and allows a process to receives data from multiple clients and respond. Named pipes have a couple of APIs to set up and configure the pipe, and use the generic file IO functions for actual communication.
Microsoft has examples for various scenarios including ones with asynchronous IO. These are great examples to understand pipes, and they are guaranteed to be correct, but they have the infrastructure code intermingled with the application logic. And while there is a multithreaded example, it sidesteps things like dealing with dynamic buffer sizes or dealing with user supplied completion routines.
In this article, I will show how to build a named pipe server that:
- keeps all connection handling away from the main application threads
- performs all data processing asynchronously in a configurable pool of threads, using a user supplied message handler.
- does not use locking to ensure thread safety
- hides all named pipe infrastructure away from the application logic.
By doing this, we get a named pipe server that can be used as a reusable component. In this first article, I will describe how to implement the server side and connection handling. The actual IO handling is covered in Part 2. The reason for splitting this topic is that the first part is logically separate form the actual IO handling. The IO can be implemented in different ways so by doing things like this, I can easily make a Part 3 to cover a different IO implementation.
The overall idea is that someone can simply add a named pipe server to their project without having to worry about the implementation details, and supply a function that will be executed for each message that is received from a client. This function has the following format:
typedef void (*PipeWorkerMessageHandler)(
void* context,
CHandle& pipeHandle,
CIOBuffer& input,
CIOBuffer& output);
The concept is similar to providing a function for a thread. context is a pointer that is supplied to the PipeWorkerMessageHandler function when it is executed. This is the only way to give that function access to application context data without using global variables. input and output are simply about the IO. It is up to the function to do something with the input data and if it wants to send a response message, it can put data in the output buffer.
In typical situations, pipeHandle is not used since sending and receiving data is done via the IO buffers. However, named pipes support functionality for impersonation and other things, for which the handle is needed. Additionally, the message handler may decide to close the connection. For operations such as these, it needs the pipeHandle which is why the server provides it. Depending on how the handle is closed, specific cleanup may be needed in the IO handler. We'll cover that too in Part 2.
Designing CNamedPipeServer
Since we're building a component that is running asynchronously to do work, it makes sense to visualize it with a state diagram:
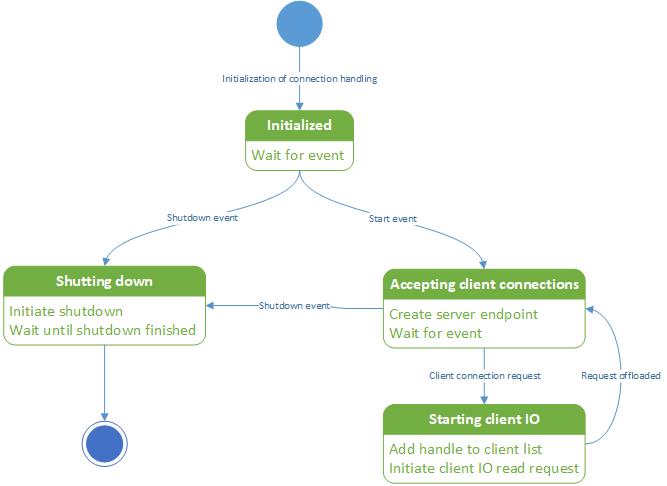
After creating the object and initializing all internal variables, the pipe server is initialized, but idle. It's just waiting in the Initialized state until the object owner makes a decision. It doesn't start servicing connection requests immediately because the application itself may still be initializing itself. For example, Microsoft SQL Server accepts client connections via named pipe. But initializing the named pipe handling is just one aspect of the overall application startup. It makes sense to block all communication until the application has determined that all other subsystems are up and running. Based on what the application decides, the state can then change to shutting down, or accepting client connections.
There is a reason that the component cannot be shutdown instantly. The component is running asynchronously. What that component is doing at any exact given time is essentially unknowable. It is possible or even likely that it is doing something that requires cleaning up. We cannot just yank it out of existence without repercussions so instead we tell it to take all necessary actions to shut down. The final state transition depends on the component itself.
Note that the transition to shutting down can happen only when it is either waiting in the initialized state or when it is accepting client connections. If it is performing whatever actions it is taking in starting client IO, it cannot be interrupted. Should a signal to shutting down be sent at that time, it will simply not be acted upon. Any new connection will be offloaded completely before the server can act on the shutdown signal.
Design wise, that is all for now. The design of the IO handler will be handled in Part 2.
Win32 Named Pipe API Reference
Before diving into the design itself, it's important to discuss some of the win32 APIs that are relevant when working with named pipes, in particular at the server side.
IO itself is relatively easy to discuss later because IO is performed using the same ReadFile, WriteFile, ... APIs that are also used with regular file IO. But on the server side, a couple of extra functions are important for the purpose of managing the pipe object.
This section is perhaps a bit dry and boring. If you just want to know how the overall pipe server is designed, you could skip it. But for understanding some design choices or details, you need the information that is supplied in this chapter.
Creating a Pipe
We can create a pipe using the function call CreateNamedPipe. This function has an unfortunate name. While it does create the named pipe kernel object with the specified name, it would be more correct to say that if creates the kernel object if it doesn't yet exist and creates a single server-side connection endpoint to which a single client can connect.
It is not necessary to have multiple such endpoints (open handles) in parallel because this handle is used in a wait operation, waiting for a client to connect. When a client connects, it gets offloaded into an IO pool and a new endpoint is created to prepare for the next client. As long as the next connection is available for connection before the connection timeout elapses, a client will never know if the server is temporarily busy offloading the previous connection.
HANDLE CreateNamedPipeW(
LPCwSTR lpName,
DWORD dwOpenMode,
DWORD dwPipeMode,
DWORD nMaxInstances,
DWORD nOutBufferSize,
DWORD nInBufferSize,
DWORD nDefaultTimeOut,
LPSECURITY_ATTRIBUTES lpSecurityAttributes );
lpName is the devicename of the pipe. It should be of the format \\.\Pipe\pipename. dwOpenMode sets some important properties of the pipe that determine how it can be used. The ones we use are:
PIPE_ACCESS_DUPLEX which allows data to be transferred in both directions.FILE_FLAG_OVERLAPPED which enables asynchronous read and write operations. This one is important because we want to build a server that performs IO and connection management in an asynchronous manner. If we don't specify this flag, all IO becomes synchronous.
dwPipeMode specifies how we use the pipe. Basically there are two ways: to use it as a stream of individual, separate messages or a stream of bytes. This choice does, of course, depend on what it is you're trying to do. Some things are a natural fit for messages (command and control of a service application) or a byte stream (audio streaming). I'm building a component that is for message based IO so we use the following values:
PIPE_TYPE_MESSAGE which specifies that every write operation into the pipe is treated as a singular message that can be identified as separate from the next write operation.PIPE_READMODE_MESSAGE which specifies that data is read from the pipe as a message instead of a stream of bytes.
At first, it may seem weird that you can specify a read mode that is different from the write mode. Why would you read a message as a stream of bytes? When you do this, it is no longer possible to distinguish between consecutive messages. The answer depends on the exact use case. If you treat every message as an individual message, this is makes the logic simpler because you don't have to implement protocol logic to identify the beginning and end of a message. If you read a byte stream, you can read a lot of messages with a single read operation, leading to potential time saves if you are dealing with lots of very small messages with a high frequency.
PIPE_TYPE_MESSAGE is still beneficial in that case because the pipe server still has the guarantee that it will never have to deal with incomplete messages. Every write is still treated as a singular whole, and when the server reads a stream of messages, it therefore has the guarantee that however many messages are in the buffer, the last message will be a complete one.
nMaxInstances specifies how many instances of the pipe can exist. An instance in this case is the server end of a client - server connection. As many clients can connect as there are possible instances.
nInBufferSize and nOutBufferSize are simply the default size of the connection buffer. There is a long section in the documentation about how to size them. Note that this is not a hard limit on message length. The should be large enough for typical messages, but small enough that you don't affect the non-paged pool negatively.
nDefaultTimeOut can be left to 0. It is the timeout that is used when a client tries to connect to a named pipe. If the client tries to connect without specifying a timeout and no free instances are available, this timeout is used before failing the connection attempt.
The final parameter is lpSecurityAttributes. Use NULL to accept the default ACL for named pipes. This suffices for most uses.
Accepting the Client Connection
After creating the named pipe, the next step is to actively wait for a client to connect. This is done with the API.
BOOL ConnectNamedPipe(
HANDLE hNamedPipe,
LPOVERLAPPED lpOverlapped
);
hNamedPipe is the handle that was previously created. If we do not supply an OVERLAPPED structure, this function will simply block until a client connects or the handle is closed. Cancelling for the purpose of shutting down the server would be hard to do reliably (I will explain the details further below). Using an OVERLAPPED structure enables us to wait for connection using a separate wait function to solve this problem.
The OVERLAPPED structure is a way for the win32 API to deal with asynchronous requests. It contains data fields which are used to keep track of the results of an asynchronous IO operation, and a HANDLE field which contains the handle of a win32 event which is triggered upon completion of the IO operation.
Using Windows Events
Speaking about events: events are an important part of my design, both in the server as in the IO handling which is discussed later on. Windows events are simply objects that can be used to trigger an ongoing wait operation. If you create an event using CreateEvent, you can use the returned HANDLE value, for example, with WaitForSingleObject to wait for the event to be triggered.
There is a fair bit of flexibility in working with events. There are two types: manual reset events or automatic reset events. If a manual reset event is set, then every current and future wait operation, in every thread will be satisfied (proceed) until the even is reset. If an automatic reset event is fired, then 1 and only 1 current or future wait operation will be satisfied. So even if there are 4 threads waiting on the same automatic reset event, only 1 of them is triggered.
CreateEvent has a couple of parameters concerning security, the name and whether the initial state is set or not. Since most of the time you'll be using the same default settings with only the manual / automatic selection needed, I made 2 lightweight wrappers with an appropriate constructor.
class CEvent : public CHandle
{
public:
CEvent(
LPSECURITY_ATTRIBUTES lpEventAttributes,
BOOL bManualReset,
BOOL bInitialState,
LPCWSTR lpName);
CEvent(
DWORD dwDesiredAccess,
BOOL bInheritHandle,
LPCWSTR lpName);
};
class CManualResetEvent : public CEvent
{
public:
CManualResetEvent(
BOOL bInitialState = FALSE,
LPCWSTR lpName = NULL,
LPSECURITY_ATTRIBUTES lpEventAttributes = NULL) :
CEvent(lpEventAttributes, TRUE, bInitialState, lpName) {}
};
class CAutoResetEvent : public CEvent
{
public:
CAutoResetEvent(
BOOL bInitialState = FALSE,
LPCWSTR lpName = NULL,
LPSECURITY_ATTRIBUTES lpEventAttributes = NULL) :
CEvent(lpEventAttributes, FALSE, bInitialState, lpName) {}
};
At the lowest level, the event is a handle like any other Windows handle and must be managed as such. CEvent has 1 constructors: one for opening an existing event, and one for creating a new event.
Both CManualResetEvent and CAutoResetEvent only have 1 constructor. They only support construction via the constructor that creates a new event. The reason is simple: the event type is determined when the event is created. When someone opens an existing event, they have no choice in the matter. That's why I chose not to have a constructor for CManualResetEvent and CAutoResetEvent that opens an existing event. There is no inherent way to ensure that the actual event type matches the expected type. So I opted to only allow existing events to be opened through the generic CEvent.
If I didn't have those classes, I would need to supply either TRUE or FALSE every time an event is created, and that is too prone to errors.
Setting the Handle State
I already mentioned that pipe IO is similar to file IO. Certainly, from the client side there is no difference. Even the connection to the pipe is made using CreateFile. However just like the server, the client side can control whether it wants to receive the IO as messages or a byte stream. Only this is not something that can be configured via CreateFile. Instead, the client needs to use the following API to do this after creating the handle:
BOOL SetNamedPipeHandleState(
HANDLE hNamedPipe,
LPDWORD lpMode,
LPDWORD lpMaxCollectionCount,
LPDWORD lpCollectDataTimeout
);
The main parameter of interest here is lpMode. This can be set to PIPE_READMODE_MESSAGE or PIPE_READMODE_BYTE . Typically, this only needs to be done on the client side because the server side can specify this directly when creating the pipe but a server can use SetNamedPipeHandleState too if it needs to.
Implementing the CNamedPipeServer
With all the basics out of the way, we can now implement the server.
Constructing the Object
The first step is to implement the constructor. This will initialize the member variables which were explained in the API section so I am not going to cover them here again. The main things to note are the IO handler which is initialized during server initialization, and the connection handler thread which is started here.
We don't need cleanup code to deal with the thread if there is an exception during construction phase. It is the very last thing that is done which can create an exception. Regardless of where the exception happens, it is guaranteed that threads is not running.
CNamedPipeServer::CNamedPipeServer(
wstring const& lpName,
PipeWorkerMessageHandler messageHandler,
void* messageContext,
DWORD nOutBufferSize,
DWORD nInBufferSize,
DWORD nMaxInstances,
DWORD nNumThreads) :
m_Name(lpName),
m_MaxInstances(nMaxInstances),
m_InBufferSize(nInBufferSize),
m_OutBufferSize(nOutBufferSize),
m_ConnectEvent(),
m_StartEvent(),
m_ShutdownEvent(),
m_WorkerPool(nNumThreads, messageHandler, messageContext,
nInBufferSize, nOutBufferSize)
{
memset(&m_ConnectOverlap, 0, sizeof(m_ConnectOverlap));
m_ConnectOverlap.hEvent = m_ConnectEvent;
CHandle pipeHandle = CreateNamedPipeHandle();
if (pipeHandle == INVALID_HANDLE_VALUE) {
throw ExWin32Error(L"CreateNamedPipeW " + lpName);
}
m_ConnectionHandlerThread =
CreateThread(NULL, 0, ConnectionHandlerFunc, this, 0, NULL);
if (!m_ConnectionHandlerThread) {
throw ExWin32Error(L"CreateThread ConnectionHandlerFunc");
}
}
When the application provides the details for starting the pipe, there is a possibility that those parameters are invalid. Rather than discover this in the connection handler thread and having to deal with that in an asynchronous manner when the server object is already constructed, we attempt to create it here already. If it's going to cause problems, it's much better to detect it here and abort. The handle will automatically close after it's created. Creating the handle is done with the helper function:
HANDLE CNamedPipeServer::CreateNamedPipeHandle()
{
return CreateNamedPipeW(m_Name.c_str(),
PIPE_ACCESS_DUPLEX | FILE_FLAG_OVERLAPPED,
PIPE_TYPE_MESSAGE | PIPE_READMODE_MESSAGE,
m_MaxInstances,
m_OutBufferSize,
m_InBufferSize,
0,
NULL);
}
The only other things to note is that the start and connect events are auto reset, meaning that every time the event is handled, a new wait operation can start without having to manually reset it. For the shutdown, we use a manual reset event, on account that once shutdown is initiated, every wait operation should fall through if it concerns the shutdown event.
The Connection Handler State Machine: Initialized
This is where the magic happens. I've cut it into several pieces for readability. Remember that this is running in a separate thread, separate from the rest of the application.
The first part of it is the code for the initialized state in our statemachine.
DWORD CNamedPipeServer::ConnectionHandlerFunc(void* ptr)
{
CNamedPipeServer* server = (CNamedPipeServer*) ptr;
HANDLE initialWaitObjects[] = { server->m_StartEvent, server->m_ShutdownEvent };
DWORD StartEventIndex = 0;
DWORD ShutdownEventIndex = 1;
DWORD retVal = WaitForMultipleObjects(2, initialWaitObjects, FALSE, INFINITE);
if (retVal == StartEventIndex) {
; }
else {
server->m_WorkerPool.Shutdown();
return 0;
}
We use WaitForMultipleObjects to wait for either a shutdown event or a start event. This is to give the application itself to take care of its own initialization before opening up for client connections. The return value is the index of the handle that fulfilled the wait operation. There is no need to special termination code at this point, since connection handling is not yet active. If we enter shutting down then we also initiate the shutdown of the worker pool.
From here, the state is either shutting down (which ends in the destructor) or accepting client connections. The next part in our code is accepting client connections.
The Connection Handler State Machine: Accepting Client Connections
HANDLE waitObjects[] = { server->m_ConnectOverlap.hEvent, server->m_ShutdownEvent };
DWORD ConnectEventIndex = 0;
DWORD retVal = 0;
while (!server->IsShuttingDown())
{
CHandle pipeHandle = server->CreateNamedPipeHandle();
if (pipeHandle == INVALID_HANDLE_VALUE) {
DWORD error = GetLastError();
if (ERROR_PIPE_BUSY == error) {
Sleep(1000);
continue;
}
else {
server->Shutdown();
retVal = error;
}
}
if(!ConnectNamedPipe(pipeHandle, &server->m_ConnectOverlap)) {
DWORD error = GetLastError();
if (error == ERROR_IO_PENDING)
; else if (error == ERROR_PIPE_CONNECTED) {
SetEvent(server->m_ConnectOverlap.hEvent);
}
else {
server->Shutdown();
retVal = error;
}
}
DWORD retVal = WaitForMultipleObjects(2, waitObjects, FALSE, INFINITE);
We start the state by creating a new server side endpoint for the pipe. We've already pre-validated the parameters so in general there is only one reason why the pipe could not be created, and that is because it has maxed out on instances. If the server is started with say a maximum of 10 concurrent instances, and there are 10 connected clients, then it stands to reason we cannot create an 11th endpoint.
So if GetLastError returns ERROR_PIPE_BUSY, we simply sleep for a second and try again. In general, sleeping is something I try to avoid. This is one of those design choices where you have to weigh additional complexity of a slightly better solution to the simplicity of a sleep. An alternative solution would be to work with a semaphore, and use a wait operation to associate the semaphore with an open connection. That is certainly an option for a future improvement. For now, the fact that this would be a marginal concern AFTER we max out on connected clients, makes me go with the sleep.
With the server end point created, we use ConnectNamedPipe to wait for a client connection. We use an overlapped wait so that we can use WaitForMultipleObjects to wait until we either receive a connection event or a shutdown event. Now it is very unlikely but still possible that in the millisecond between creating the pipe and the attempt to connect a client connection, a client just happens to connect. When that happens, the asynchronous operation is never started and instead, the error ERROR_PIPE_CONNECTED is returned.
Since the asynchronous operation is never started, the wait operation would not be triggered. There are two ways we can deal with that. The first is to bypass the wait operation. But that would leave two cases where we have to start the IO (when ERROR_PIPE_CONNECTED is returned, or after ERROR_IO_PENDING is returned and the wait is satisfied). Instead, I chose to manually trigger the connect event. The big benefit is that it harmonizes the control flow and the rest of the process is the same for both cases.
I want to take a moment to take a step back and explain another reason why ConnectNamedPipe is used overlapped. Consider the alternative: that API blocks until a client connects. What happens if we send the shutdown event? Nothing happens. Instead, if we want to be able to initiate shutdown, we'd have to close the pipe handle from another thread. That would abort ConnectNamedPipe. However in multi threaded scenarios, you cannot take any particular timing for granted. Using a handle in two places can cause problems. Hypothetically, Thread 1 could close the handle and get pre-empted right at the point where internally, it closes the handle but before it sets its internal value to NULL. At that point, Thread 2 could satisfy the wait because a client just happens to connect, and try to offload the handle (which would fail but that's irrelevant here), and the original CHandle value would be deleted via RAII. Remember that Thread 1 was interrupted just before cleaning up its internal state. So Thread 2 would close that handle too.
If a debugger is attached, that would cause an exception. If no debugger is attached, it would not be really harmful. But still I hope it is clear that using objects and data in multiple threads is generally a bad idea if you don't really have to. Now obviously, there are ways to deal with that. You can use locking primitives, InterlockedExchange functions or similar things. But as you see it quickly becomes a mess of which the correctness is getting more complicated to prove. On the other hand, functions like WaitForMultipleObjects are specifically designed to wait for triggers that can come from different sources and threads, and are therefore the ideal choice for... responding to events that originate in different threads. The last two paragraphs are not specifically related to just pipes but apply in general to any multi threading scenario: keep things simple, and use primitives that are specifically designed for the scenario.
The Connection Handler State Machine: Starting Client IO
Now for the starting client IO state:
while (!server->IsShuttingDown())
{
if (retVal == ConnectEventIndex) {
try
{
server->m_WorkerPool.AddClientConnection(pipeHandle);
}
catch (exception& ex)
{
}
}
else if (retVal == ShutdownEventIndex) {
}
else {
server->Shutdown();
retVal = GetLastError();
}
}
server->m_WorkerPool.Shutdown();
m_WorkerPool.WaitUntilFinished(INFINITE);
return retVal;
}
This part is relatively simple. If the connect event was received, the handle is added to the worker pool. From that point on, it is no longer of any concern. The details will be covered in Part 2 but suffice it to say there are only two options: The handle is duplicated and stored for use in the worker pool, or there is an exception which means no IO is started. Either way, we're done with it.
As is clear from the original state diagram, this part of the code is not receptive to events. starting client IO is unconditional. Even if a shutdown request has already been sent at that point, that does not affect what is going on here. At this point, the IO handling is started and no longer our concern. It is the IO worker pool itself which will take care of shutting itself down and terminating all connections. If the wait operation had an unforeseen error however, we do initiate the shutdown. This is not a violation of the state diagram because the state only changes when that shutdown event is received.
If the state machine ends up in shutting down, then the connection loop will stop and the worker pool shutdown is initiated. It is important that we do this after the while loop has stopped. This way, we can guarantee that the internal state of the worker pool is not changing when the shutdown is initiated. This makes the internal design of the pool a lot simpler.
We know the IO handler is executing a message handler (callback function) at the behest of the application. Remember the earlier explanation about threading pitfalls. This is another one. It is possible to initiate the shutdown and have the connection thread finish completely while the IO handler is still executing that message handler even though the IO shutdown is initiated. If the application thinks that the server is shut down and does something that would invalidate the address space or internal state of the message handler, our application could crash. So in order to avoid that, we make sure that the named pipe server connection thread does not end before the IO pool has shut down too. This guarantees that the shutdown state of the server statemachine is representative of the entire named pipe component.
Interacting with the State of the State Machine
Triggering the shutdown, detecting if we are shutting down, ... is done using these simple helpers which are self-explanatory:
bool CNamedPipeServer::IsShuttingDown()
{
return (0 == WaitForSingleObject(m_ShutdownEvent, 0));
}
void CNamedPipeServer::Shutdown()
{
m_ShutdownEvent.SetEvent();
}
void CNamedPipeServer::StartServing()
{
m_StartEvent.SetEvent();
}
When the application itself determines that it is time to shut down, it will trigger the event. However, because this takes place in parallel, it needs to have a wait to know when it is safe to destroy the object. It can use this function by waiting for as long as it takes, or in short intervals. The latter is something you'd typically do in a Windows Service application because when the service application is stopping, it needs to periodically report progress.
bool CNamedPipeServer::WaitUntilFinished(DWORD dwMilliSeconds)
{
DWORD error = WaitForSingleObject(m_ConnectionHandlerThread, dwMilliSeconds);
if (error == WAIT_OBJECT_0)
return true;
else if (error == WAIT_TIMEOUT)
return false;
throw ExWin32Error("CNamedPipeServer::WaitUntilFinished");
}
A thread handle is a waitable object to it's easy to determine if the thread is shut down or not.
Destructing the Object
No special cleanup needs to be done to destroy the object. All handles, arrays, etc. use RAII so their destructors will do all necessary actions. The only things that we need to add is the guarantee that when the object is destroyed, there are no more threads touching the object data because that would end badly.
In general, this should not be necessary. The application should initiate shutdown, and it should wait until shutdown has completed. But that are two 'should's too many so to make sure, we have the following safeguard in place:
CNamedPipeServer::~CNamedPipeServer()
{
Shutdown();
WaitUntilFinished(INFINITE);
}
Conclusion
That's it! We now have a fully functional pipe server that is asynchronous, uses multithreading, and doesn't use locks. It also manages to keep all the named pipe infrastructure code away from the application.
The IO handling itself will be explained in Part 2. That's also the reason why I have no test application or source downloads attached to this article. There's nothing to test / download yet, in the context of the information that was provided thus far..
An article of this nature requires a balance between going in depth enough at the API level to explain everything to someone who wants to know the details, and keeping it short enough that most people will still want to read it. Similarly, I wanted to highlight some of the multithreading issues and race conditions that could be risky in any design that allows asynchronous interaction. Even if the odds are extremely low, it is my opinion that when you are implementing multithreaded code, it is either correct or it isn't. 'mostly correct' does not exist. Yet I also didn't want to turn this into a treatise on everything related to multithreading.
I hope I struck the right balance. Let me know in the comments section.
History
- 9th December, 2002: First version

