Why ISO C++ Is Not Enough for Heterogeneous Computing
Once you work in computational science long enough, you know that programming language and tools come and go. Few of us have the luxury of working in a single programming language anymore. When I joined Intel in 2000, my projects were a mix of Fortran, C, and to my dismay C++. I wasn’t a fan of C++ back then. It took a long time to compile, I didn’t see much point to objects or object-oriented programming, and the constructs that made the language expressive also made it slow. C++ compilers have improved significantly over the last 20 years, so this is no longer true.
Consequently, I wasn’t thrilled about having to relearn C++ when I started using oneAPI. The direct programming approach of oneAPI is Khronos SYCL, which is based on ISO C++17. However, I was surprised at how different C++17 looked compared to C++ circa 2000. It was still cryptic but very expressive, and dare I say: productive, especially when combined with the C++ Standard Template Library (STL) and oneAPI libraries, which brings me to the topic of this discussion: SYCL and its relation to ISO C++.
C++ is an excellent programming language (despite what the Rust advocates say - search C++ vs. Rust for a taste of that debate) that has withstood the test of time. There are a lot of C++ programmers and billions of lines of C++ code out there. However, the “free lunch” that Herb Sutter wrote about ended a long time ago, and he’s now talking about the “hardware jungle.” We’re well into the era of heterogeneous parallelism, but C++ lacks key features necessary to exploit accelerator devices. The “free lunch” refers to the shift from frequency to core scaling. The “hardware jungle” refers to the proliferation of specialized processors.
First, and most important, C++ has no concept of an accelerator device, so obviously there are no language constructs to discover what devices are available, to offload work to those devices, or to handle exceptions that occur in code running on a device. Exception handling is particularly complicated if code is running asynchronously on the host and various devices. SYCL provides C++ platform, context, and device classes to discover what devices are available and to query the hardware and backend characteristics of those devices. The queue and event classes allow the programmer to submit work to devices and monitor the completion of asynchronous tasks. If an error occurs in code running on a device, asynchronous error handlers can be triggered by the queue::wait_and_throw(), queue::throw_asynchronous(), or event::wait_and_throw() methods, or automatically upon queue or context destruction.
Second, and only slightly less important, C++ has no concept of disjoint memories. Accelerator devices typically have their own memory that is separate from the main memory of the host system. Heterogeneous parallelism requires a way to transfer data from the host memory to the device memory. C++ provides no such mechanism, but SYCL does in the form of buffers/accessors and pointer-based allocation into Unified Shared Memory (USM). Host-device data transfer is done using C++ classes and/or familiar dynamic memory allocation syntax.
C++ with SYCL
SYCL adds functionality to C++ to support accelerator devices. It just adds a new set of C++ template libraries (Figure 1). This is illustrated in the following side-by-side example, which implements the common SAXPY (Single-precision A times X Plus Y) calculation in C++ (left) and SYCL (right):
#include <vector>
int main()
{
size_t N{...};
float A{2.0};
std::vector<float> X(N);
std::vector<float> Y(N);
std::vector<float> Z(N);
for (int i = 0; i < N; i++)
{
}
for (int i = 0; i < N; i++)
{
Z[i] += A * X[i] + Y[i];
}
}
|
#include <CL/sycl.hpp>
int main()
{
size_t N{...};
float A{2.0};
sycl::queue Q;
auto X = sycl::malloc_shared<float>(N, Q);
auto Y = sycl::malloc_shared<float>(N, Q);
auto Z = sycl::malloc_shared<float>(N, Q);
for (int i = 0; i < N; i++)
{
}
Q.parallel_for(sycl::range<1>{N}, [=](sycl::id<1> i)
{
Z[i] += A * X[i] + Y[i];
});
Q.wait();
}
|
The codes are clearly similar. The C++ code is just modified to offload the SAXPY calculation to an accelerator:
- Line 1: Include the SYCL header.
- Line 8: Create a SYCL queue for the default accelerator. If no accelerator is available, any work submitted to the queue will simply run on the host.
- Lines 9-11: Allocate the work arrays in USM. The SYCL runtime will handle data transfer between the host and the accelerator specified in the queue object.
- Line 19: Submit the SAXPY calculation as a C++ lambda function to be executed in parallel on the accelerator specified in the queue argument.
- Line 23: Unlike some proprietary approaches to heterogeneous parallel programming, SYCL is an asynchronous, event-based language. Submitting work to a SYCL queue does not block the host (or other accelerators) from continuing to do useful work. The wait() method prevents the host from exiting before the accelerator completes the SAXPY calculation.
Productive Approach
I suggested earlier that oneAPI is a productive approach to acceleration. I offer the next example as evidence. The STL greatly improves the productivity of C++ programmers. The oneAPI Data Parallel C++ Library (oneDPL) is the oneAPI accelerated implementation of the C++ STL. The following side-by-side example performs a maxloc reduction using the C++ STL (left) and oneDPL (right):
#include <iostream>
#include <vector>
#include <algorithm>
int main()
{
std::vector<int> data{2, 2, 4, 1, 1};
auto maxloc = max_element(
data.cbegin(),
data.cend());
std::cout << "Maximum at element "
<< distance(data.cbegin(),
maxloc)
<< std::endl;
}
|
#include <iostream>
#include <oneapi/dpl/algorithm>
#include <oneapi/dpl/execution>
#include <oneapi/dpl/iterator>
int main()
{
std::vector<int> data{2, 2, 4, 1, 1};
auto maxloc = oneapi::dpl::max_element(
oneapi::dpl::execution::dpcpp_default,
data.cbegin(),
data.cend());
std::cout << "Maximum at element "
<< oneapi::dpl::distance(data.cbegin(),
maxloc)
<< std::endl;
}
|
Once again, the codes are similar:
- Lines 2-4: Include the necessary oneDPL headers.
- Line 9 and 15: Call the oneDPL implementations of the STL max_element() and distance() functions.
- Line 10: Provide an execution policy, in this case the policy for the default accelerator. If no accelerator is available, any work submitted to the queue will simply run on the host.
There’s no explicit host-device data transfer in the oneDPL code. It’s handled implicitly by the runtime, which reinforces my contention that oneAPI offers a productive, portable approach to heterogeneous acceleration. It is worth noting that the SYCL programs will work on any system with a SYCL compiler and runtime (Figure 2).
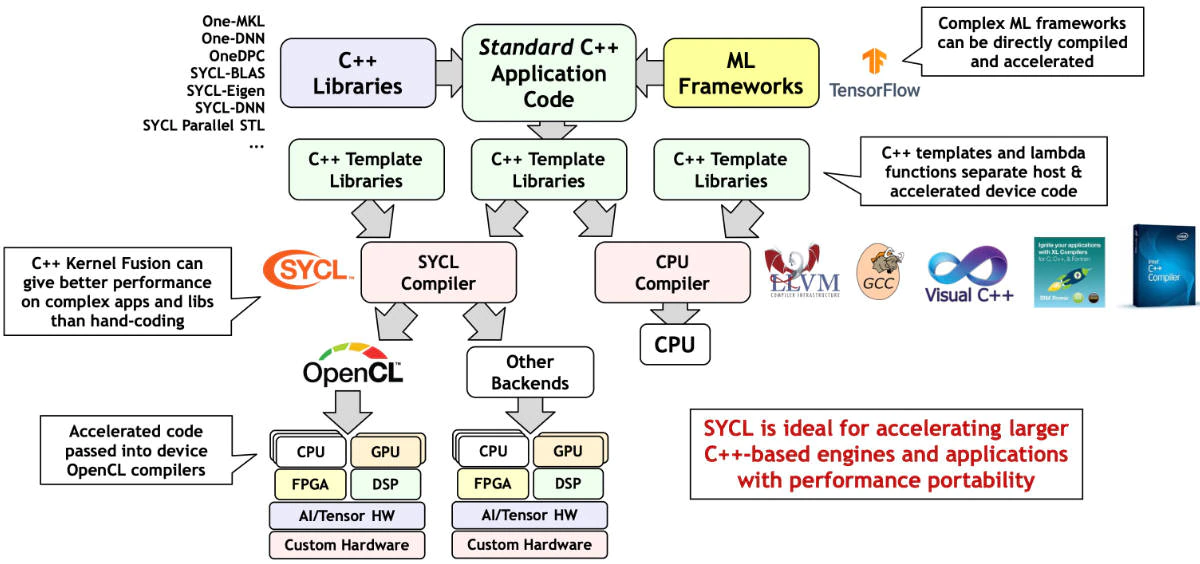
Figure 1: SYCL is just C++ with additional template libraries to support heterogeneous accelerators. (Source:
Khronos.org/sycl).
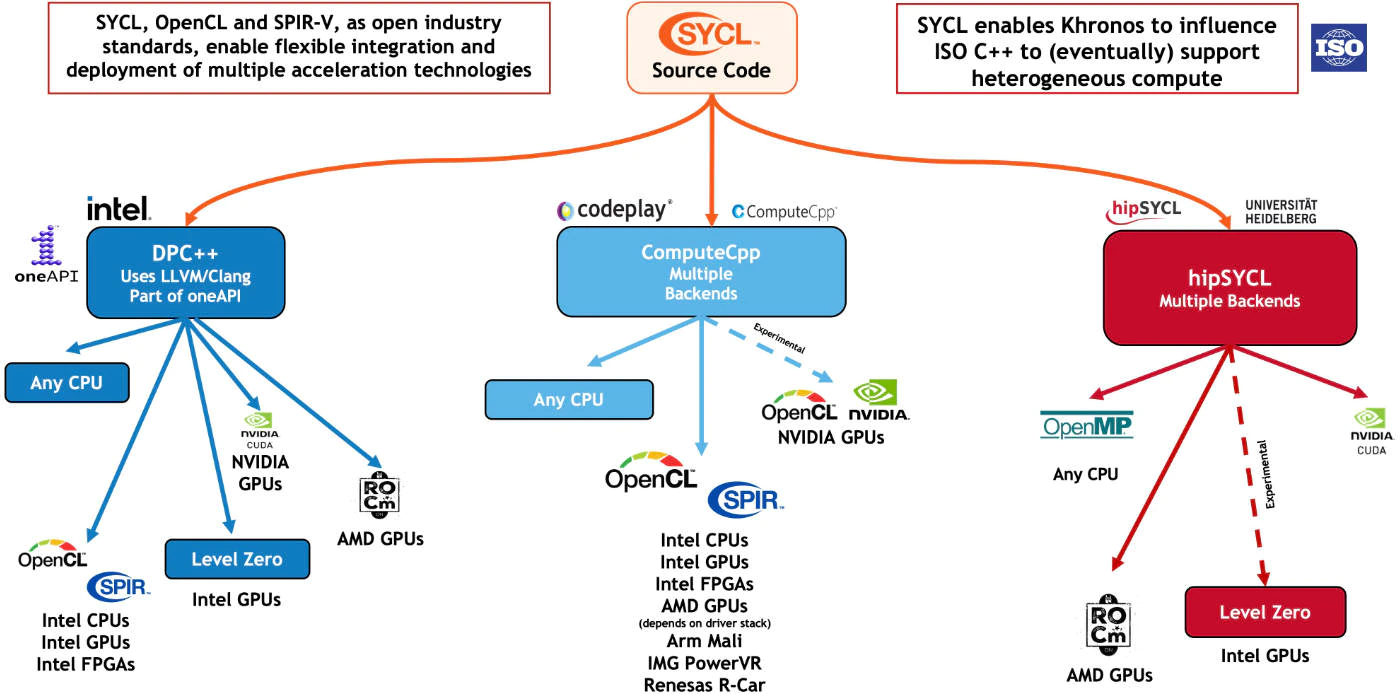
C++ is a language with entrenched programmer expectations and stability requirements, so changes to the standard are made carefully, albeit slowly. Heterogeneous parallelism is just one of many new features that future versions of C++ will have to support. The P2300R5 std::execution proposal could help address current limitations of C++ with respect to heterogeneity by defining a “...framework for managing asynchronous execution on generic execution contexts” and a “...model for asynchrony, based around ... schedulers, senders, and receivers...” This proposal has been sent to the Library Working Group for C++26. In the meantime, notice the comment in the upper right corner of Figure 2. SYCL gives us a flexible and non-proprietary way to express heterogeneous parallelism while the ISO C++ standard evolves.
Learn More
In order to learn more about C++ with SYCL programming, the following sources are good places to start:

