Intel engineers work with the PyTorch* open-source community to improve deep learning (DL) training and inference performance. Intel® Extension for PyTorch is an open-source extension that optimizes DL performance on Intel® processors. Many of the optimizations will eventually be included in future PyTorch mainline releases, but the extension allows PyTorch users to get up-to-date features and optimizations more quickly. In addition to CPUs, Intel Extension for PyTorch will also include support for Intel® GPUs in the near future.
Intel Extension for PyTorch optimizes both imperative mode and graph mode (Figure 1). The optimizations cover PyTorch operators, graph, and runtime. Optimized operators and kernels are registered through the PyTorch dispatching mechanism. During execution, Intel Extension for PyTorch overrides a subset of ATen operators with their optimized counterparts and offers an extra set of custom operators and optimizers for popular use-cases. In graph mode, additional graph optimization passes are applied to maximize the performance. Runtime optimizations are encapsulated in the runtime extension module, which provides a couple of PyTorch frontend APIs for users to get finer-grained control of the thread runtime.
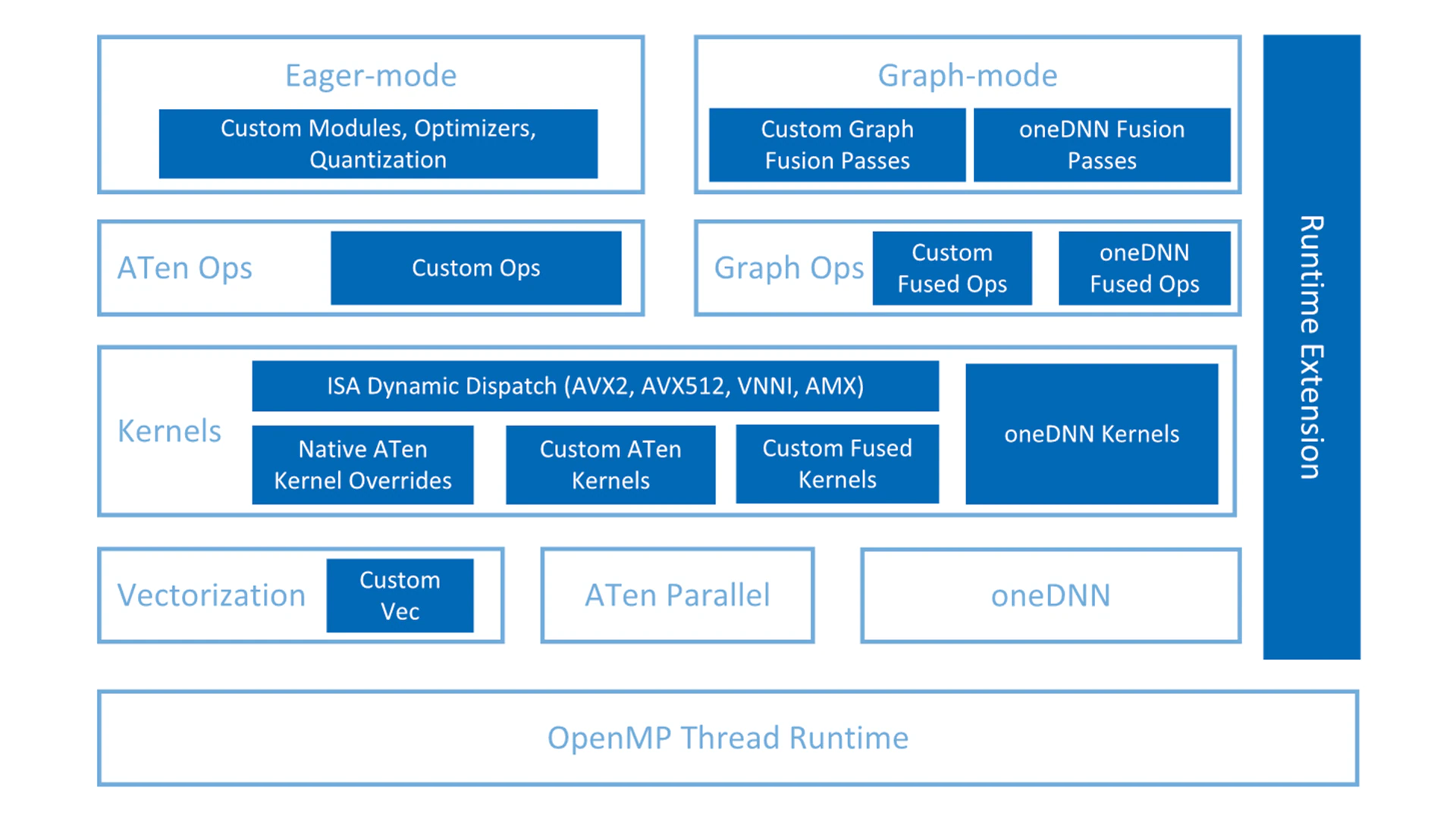
Figure 1. Intel® Extension for PyTorch*.
A Peek at the Optimizations
Memory layout is a fundamental optimization for vision-related operators. Using the right memory format for input tensors can significantly improve the performance of PyTorch models. “Channels last memory format” is generally beneficial for multiple hardware backends:
This holds true for Intel processors. With Intel Extension for PyTorch, we recommend using the “channels last” memory format, i.e.:
model = model.to(memory_format=torch.channels_last)
input = input.to(memory_format=torch.channels_last)
The oneAPI Deep Neural Network Library (oneDNN) introduces blocked memory layout for weights to achieve better vectorization and cache reuse. To avoid runtime conversion, we convert weights to predefined optimal block format prior to the execution of oneDNN operators. This technique is called weight prepacking, and it’s enabled for both inference and training when users call the ipex.optimize frontend API provided by the extension.
Intel Extension for PyTorch provides several customized operators to accelerate popular topologies, including fused interaction and merged embedding bag, which are used for recommendation models like DLRM, ROIAlign and FrozenBatchNorm for object detection workloads.
Optimizers play an important role in training performance, so we provide highly tuned fused and split optimizers in Intel Extension for PyTorch. We provide the fused kernels for Lamb, Adagrad, and SGD through the ipex.optimize frontend so users won’t need to change their model code. The kernels fuse the chain of memory-bound operators on model parameters and their gradients in the weight update step so that the data can reside in cache without being loaded from memory again. We are working to provide more fused optimizers in the upcoming extension releases.
BF16 mixed precision training offers a significant performance boost through accelerated computation, reduced memory bandwidth pressure, and reduced memory consumption. However, weight updates would become too small for accumulation in late stages of training. A common practice is to keep a master copy of weights in FP32, which doubles the memory requirement. The added memory usage burdens workloads that require many weights like recommendation models, so we apply a “split” optimization for BF16 training. We split FP32 parameters into top and bottom halves. The top half is the first 16 bits, which can be viewed exactly as a BF16 number. The bottom half is the last 16 bits, which are kept preserve accuracy. When performing forward and backward propagations, the top half benefits from native BF16 support on Intel CPUs. While performing parameter updates, we concatenate the top and bottom halves to recover the parameters back to FP32, thus avoiding accuracy loss.
Deep learning practitioners have demonstrated the effectiveness of lower numerical precision. Using 16-bit multipliers with 32-bit accumulators improves training and inference performance without compromising accuracy. Even using 8-bit multipliers with 32-bit accumulators is effective for some inference workloads. Lower precision improves performance in two ways: The additional multiply-accumulate throughput boosts compute-bound operations, and the smaller footprint boosts memory bandwidth-bound operations by reducing memory transactions in the memory hierarchy.
Intel introduced native BF16 support in 3rd Gen Intel® Xeon® Scalable processors with BF16→ FP32 fused multiply-add (FMA) and FP32→BF16 conversion Intel® Advanced Vector Extensions-512 (Intel® AVX-512) instructions that double the theoretical compute throughput over FP32 FMAs. BF16 will be further accelerated by the Intel® Advanced Matrix Extensions (Intel® AMX) instruction set in the next generation of Intel Xeon Scalable processors.
Quantization refers to information compression in deep networks by reducing the numerical precision of its weights and/or activations. By converting the parameter information from FP32 to INT8, the model gets smaller and leads to significant savings in memory and compute requirements. Intel introduced the AVX-512 VNNI instruction set extension in 2nd Gen Intel Xeon Scalable processors. It gives faster computation of INT8 data and results in higher throughput. PyTorch offers a few different approaches to quantize models. (See Practical Quantization in PyTorch.)
Graph optimizations like operator fusion maximizes the performance of the underlying kernel implementations by optimizing the overall computation and memory bandwidth. Intel Extension for PyTorch applies operator fusion passes based on the TorchScript IR, powered by the fusion ability in oneDNN and the specialized fused kernels in the extension. The whole optimization is fully transparent to users. Constant-folding is a compile-time graph optimization that replaces operators that have constant inputs with precomputed constant nodes. Convolution+BatchNorm folding for inference gives nonnegligible performance benefits for many models. Users get this benefit from the ipex.optimize frontend API. It’s worth noting that we are working with the PyTorch community to get the fusion capability better composed with PyTorch NNC (Neural Network Compiler) to get the best of both.
Examples
Intel Extension for PyTorch can be loaded as a module for Python programs or linked as a library for C++ programs. Users can get all benefits with minimal code changes. A few examples are included below, but more can be found in our tutorials.
BF16 Training
...
import torch
...
model = Model()
model = model.to(memory_format=torch.channels_last)
criterion = ...
optimizer = ...
model.train()
import intel_extension_for_pytorch as ipex
model, optimizer = ipex.optimize(model, optimizer=optimizer, dtype=torch.bfloat16)
...
with torch.cpu.amp.autocast():
data = data.to(memory_format=torch.channels_last)
optimizer.zero_grad()
output = model(data)
loss = ...
loss.backward()
...
BF16 Inference
...
import torch
...
model = Model()
model = model.to(memory_format=torch.channels_last)
model.eval()
import intel_extension_for_pytorch as ipex
model = ipex.optimize(model, dtype=torch.bfloat16)
...
with torch.cpu.amp.autocast(),torch.no_grad():
data = data.to(memory_format=torch.channels_last)
model = torch.jit.trace(model, data)
model = torch.jit.freeze(model)
with torch.no_grad():
output = model(data)
...
INT8 Inference – Calibration
import os
import torch
model = Model()
model.eval()
data = torch.rand(<shape>)
import torch.fx.experimental.optimization as optimization
model = optimization.fuse(model, inplace=True)
import intel_extension_for_pytorch as ipex
conf = ipex.quantization.QuantConf(qscheme=torch.per_tensor_affine)
for d in calibration_data_loader():
with ipex.quantization.calibrate(conf):
model(d)
conf.save('int8_conf.json', default_recipe=True)
with torch.no_grad():
model = ipex.quantization.convert(model, conf, torch.rand(<shape>))
model.save('quantization_model.pt')
INT8 Inference – Deployment
import torch
import intel_extension_for_pytorch as ipex
model = torch.jit.load('quantization_model.pt')
model.eval()
data = torch.rand(<shape>)
with torch.no_grad():
model(data)
Performance
The potential performance improvements using Intel Extension for PyTorch are shown in Figure 2 and Figure 3. Benchmarking was done on 2.3 GHz Intel Xeon Platinum 8380 processors. (See the measurement details for more information about the hardware and software configuration.) Offline refers to running single-instance inference with large batch using all cores of a socket (Figure 2). Realtime refers to running multi-instance, single batch inference with four cores per instance.
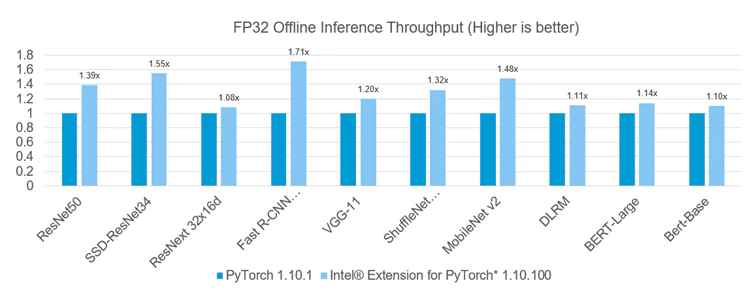
Figure 2. Performance improvement for offline inference using Intel® Extension for PyTorch*.

Figure 3. Performance improvement for inference using Intel® Extension for PyTorch*.
Future Work
The intention of Intel Extension for PyTorch is to quickly bring PyTorch users additional performance on Intel processors. We will upstream most of the optimizations to the mainline PyTorch while continuously experimenting with new features and optimizations for the latest Intel hardware. We encourage users to try the open-source project and provide feedback in the GitHub repository.
See Related Content
Technical Articles
On-Demand Webinars & Workshops
Get the Software
Intel® AI Analytics Toolkit
Accelerate end-to-end machine learning and data science pipelines with optimized deep learning frameworks and high-performing Python* libraries.
Get It Now
See All Tools

