In this article, I describe one way to implement objects that dynamically manage their own memory by deriving from template classes that represent the behavioral contract of a block of memory, using an allocator class as template arguments.
Introduction
If you do any amount of platform programming that involves the Windows API, you will be spending a lot of time doing pointer arithmetic and working with dynamically allocated blocks of memory.
In my previous articles, I have already published a couple of techniques to facilitate this, such as a class to deal with structures that have variable size or IO buffers that can grow on request. These techniques made use of a class that represented a block of heap memory.
However, this also limited their use to heap memory. There are times when you want to allocate that memory not on the heap, but on memory that is shared between process spaces, or even between different computers using memory that is mapped to a PCI board. And of course, there are scenarios where you want allocators with different behavior. In all of those cases, you would rather not implement them all over, just because you want to change the underlying physical implementation.
In this article, I will explore techniques to use custom allocators with a generic memory class in order to decide at compile time where the class will manage its dynamic memory, using C++ template programming.
I want to stress that with the immense power and flexibility of C++, there are many completely different ways to implement something like this, to cover every possible imaginable scenario. In this article, I explore one approach that makes sense for the platform programming that I deal with.
Design Goal / Semantics
The goal in this article is to outline an implementation of a class that represents a range of memory, with the following design constraints:
- The pointer value and memory size are available to derived classes, but not the internal state of the memory object.
- The memory is implemented on an abstract base class that can serve as an implementation agnostic interface to access the memory.
- The allocator for the memory is a template argument so that it is part of the object type. Trying to mix derived classes with different allocators will result in compiler error not in runtime error.
- The abstract base class too is a template argument. This allows for memory objects with different behavioral guarantees to generate compiler errors when used incorrectly instead of at runtime.
Making an Allocator Object
If we're going to manage memory, we need a memory allocator to do that for us. And because we want to be able to switch those allocators at compile time, they need to conform to an interface contract. C++ doesn't have the dotNET concept of interfaces, but we can have an abstract base class which amounts to the same thing.
Strictly speaking, it is not necessary to have an abstract base class for the allocator, because the compiler will simply show an error if the correct method signatures are not present. Even so, it's convenient to have one, to make it clearer what the requirements for a memory allocator are:
class IAllocator
{
public:
virtual void Allocate(void* &ptr, size_t &size, size_t reqSize) = 0;
virtual void DeAllocate(void* &ptr, size_t &size) = 0;
virtual void Resize(void* &ptr, size_t& size, size_t reqSize) = 0;
};
The three basic functions of my memory allocator are to allocate a piece of memory, to deallocate it, and to resize it. Note that because a pointer and its size are always dealt with together, I pass them both in by reference. The actual values are maintained somewhere else, in a derived class. The only responsibility of the allocator is to manage the memory and make sure that the ptr and size values are correct after the method call.
One possible implementation is an allocator that manages memory on the standard process heap.
class CHeapAllocator : public IAllocator
{
public:
virtual void Allocate(void* &ptr, size_t& size, size_t reqSize);
virtual void DeAllocate(void* & ptr, size_t& size);
virtual void Resize(void* &ptr, size_t& size, size_t reqSize);
};
The CHeapAllocator class is nothing but an implementation of the abstract class. The methods all have implementations but I leave them virtual to allow the opportunity for a future heap allocator class to override them as needed.
void CHeapAllocator::Allocate(void* &ptr, size_t& size, size_t reqSize)
{
DeAllocate(ptr, size);
if (reqSize== 0)
return;
ptr = HeapAlloc(GetProcessHeap(), HEAP_ZERO_MEMORY, reqSize);
if (!ptr) {
throw std::bad_alloc();
}
size = reqSize;
}
void CHeapAllocator::DeAllocate(void* &ptr, size_t& size)
{
if (ptr)
HeapFree(GetProcessHeap(), 0, ptr);
ptr = NULL;
size = 0;
}
void CHeapAllocator::Resize(void* &ptr, size_t& size, size_t reqSize)
{
if (reqSize== 0) {
DeAllocate(ptr, size);
return;
}
if (!ptr) {
Allocate(ptr, size, reqSize);
}
else {
void* newPtr =
HeapReAlloc(GetProcessHeap(), HEAP_ZERO_MEMORY, ptr, reqSize);
if (!newPtr) {
throw std::bad_alloc();
}
ptr = newPtr;
size = reqSize;
}
}
There is not a whole lot to say about the implementation. It's a standard way to use the built-in heap functions. Resizing the memory is done via the HeapReAlloc function which has the nice feature of preserving the memory contents that were already present. The pointer is not overwritten if reallocation fails because the original pointer is not freed and if we set ptr to NULL, the originally allocated memory would leak.
Even if a certain memory technology does not allow resizing, it may be able to implement Resizing because the allocator gets ownership of the pointer and the size. So it may be able to implement Resizing via allocating new memory and replacing the pointer. This is also how HeapReAlloc itself works: if there is enough room adjacent to the existing memory block, the heap manager updates internal bookkeeping. If not, it allocates new memory and copies the contents.
The Memory Interface
At its core, a block of memory is represented by a pointer, and a size parameter. The means by which its lifecycle is managed is irrelevant to the use of that memory in many cases. It is a good idea to foresee scenarios where a piece of code does not have to be aware of anything else, for the sake of code independence. For that purpose, every block of memory that we manage like this is derived from a generic memory interface.
class IMemory
{
public:
virtual size_t Size() const = 0;
virtual void* Ptr() const = 0;
virtual bool IsValid() const = 0;
virtual operator void* () const = 0;
};
In some of the use cases I described in the introduction, we need memory that can be resized via a public method call. One option would be to provide a virtual Resize method which would throw an exception if it was not overridden with an implementation. I purposely chose not to do this because if the application tries to resize a memory object which does not support resizing, it will only show up at runtime. Instead, I create another base class which inherits from IMemory and which adds a Resize method.
class IResizeableMemory : public IMemory
{
public:
virtual void Resize(size_t newSize) = 0;
};
Any dynamic memory class will inherit from one or the other. As a result, trying to use non-resizeable memory where resizable memory is expected will result in compiler errors.
Likewise, we can argue that IMemory only guarantees that it represents a piece of memory, but it doesn't guarantee that the memory range itself is fixed after it is created. If it is necessary that guarantees need to be made regarding the immutability of the memory area, we can define the interface like this:
class IImmutableMemory : public IMemory
{
};
It doesn't have any additional methods but it can be used as a template argument for specialization to change the implementation.
The Memory Base Class
In the previous section, I described the memory interfaces. These are implemented in a memory base class.
The Type Definition
The type definition of the base class is as follows:
template <typename AllocatorType, typename BaseType>
class CMemoryBase : public BaseType
{
private:
void* m_ptr = NULL;
size_t m_size = 0;
AllocatorType m_Allocator;
};
The class takes two template type arguments. The AllocatorType is used to create an allocator object to do all the memory handling. This memory handling is done via the protected Allocate, DeAllocate and Resize methods. Note that this class does have a Resize method. It is a protected one, not a public one so it is only accessible within the class. An object can resize itself unless it is immutable. It just doesn't allow other code to do that.
Because CMemoryBase derives from a supplied base, we can define the interface contract at compile time. If we have a piece of code that expects an IMemory derived class and we supply an IImmutableMemory for example, that will work because IImmutableMemory derives from IMemory. Conversely, if we supply an IResizeableMemory where IImmutableMemory is expected, that will fail.
This has the big advantage that the compiler can enforce expected behavior.
Memory Management
About the memory management itself, not a whole lot can be said. The CMemoryBase class has three methods that use the allocator.
protected:
void Allocate(size_t size) {
m_Allocator.Allocate(m_ptr, m_size, size);
}
void DeAllocate() {
m_Allocator.DeAllocate(m_ptr, m_size);
}
void Resize(size_t newSize) {
m_Allocator.Resize(m_ptr, m_size, newSize);
}
These methods are protected for now. Their accessibility will be modified by the classes deriving from CMemoryBase in order to enforce the contract implied by the base.
Constructors and Assignment
The constructor and destructor are trivial as well.
public:
CMemoryBase() : BaseType() {}
CMemoryBase(size_t size) {
Allocate(size);
}
virtual ~CMemoryBase() {
DeAllocate();
}
Memory is allocated in the constructor and destructor. The destructor is made virtual to guarantee that any memory that was allocated is guaranteed to be released, preventing memory leaks.
Our class supports move assignment and move construction. For our purposes, this means the trivial swapping of m_ptr and m_size. As tempting as it is to leave the defaults in place, we need to define our own implementations because in C++, move semantics do not guarantee that the values are swapped. They can be copied too. The would be disastrous because there could be two objects with the same value for m_ptr and that would lead to double deletion.
CMemoryBase(CMemoryBase&& other) noexcept {
std::swap(m_ptr, other.m_ptr);
std::swap(m_size, other.m_size);
}
CMemoryBase& operator = (CMemoryBase&& other) noexcept {
if (this == &other)
return *this;
std::swap(m_ptr, other.m_ptr);
std::swap(m_size, other.m_size);
return *this;
}
Likewise, we do specify a custom copy constructor and custom copy assignment because simply copying of m_ptr and m_size would have the same disastrous results. For our purposes, we define 'copying' a CMemoryBase instance to mean creating a copy of the memory range and its contents.
CMemoryBase(CMemoryBase& other) {
this->Allocate(other.m_size);
memcpy(m_ptr, other.m_ptr, m_size);
}
CMemoryBase& operator = (CMemoryBase& other) {
if (this == &other)
return *this;
Allocate(other.m_size);
memcpy(m_ptr, other.m_ptr, m_size);
return *this;
}
As a small aside: there is still discussion about whether the check for self-assignment in a move assignment is necessary. The answer is: probably, logically not. But that is the wrong question to ask. The real question is: if someone, somehow creates a situation where that does happen, it will be a very difficult thing to diagnose. Do you want to be the person who ends up spelunking through the call stack on a Friday evening to figure out a statistical fluke? The answer is: most definitely not.
Implementing the Base Type
The BaseType is used to decide at compile time which is going to be the base class: IMemory or IResizeableMemory. The only guarantee here is that at least IMemory is going to be used as a base. The implementation of that interface is trivial.
public:
size_t Size() {
return m_size;
};
void* Ptr() {
return m_ptr;
}
bool IsValid() {
return m_ptr != NULL;
}
operator void* () {
return m_ptr;
There is no public Resize method at this point.
The Memory Implementation Class
The general memory class looks like this:
template <typename AllocatorType, typename BaseType = IMemory>
class CMemory : public CMemoryBase< AllocatorType, BaseType>
{
public:
typedef CMemoryBase< AllocatorType, BaseType> base;
CMemory() : base() {}
CMemory(size_t size) : base(size) {}
};
It is a derivation from the base class, with nothing added to it. You may wonder: Why not just skip the base class and implement everything in CMemory? That is a valid question. The answer is that we're going to provide a partial specialization for the various base classes that derive from IMemory.
Partial specialization requires you to provide a full implementation of the template for a subset of template parameters. This means that if we implement everything inside CMemory, then we would have to provide another full implementation in the specialization. By putting all the logic in CMemoryBase, we only have one actual implementation, and we use CMemory to specialize in various ways.
To create a resizable memory implementation, we can simply do this:
template <typename AllocatorType>
class CMemory<AllocatorType, IResizeableMemory> :
public CMemoryBase< AllocatorType, IResizeableMemory>
{
public:
typedef CMemoryBase< AllocatorType, IResizeableMemory> base;
CMemory() : base() {}
CMemory(size_t size) :base(size) {}
using base::Resize;
};
It has no other features than the default implementation, except it pulls the protected Resize method into public accessibility. The same trick is used to make sure that an implementation of IImutableMemory is actually immutable. It removes the allocator methods from protected view and makes them private so that they cannot be used.
template <typename AllocatorType>
class CMemory<AllocatorType, IImmutableMemory> :
public CMemoryBase< AllocatorType, IImmutableMemory>
{
public:
typedef CMemoryBase< AllocatorType, IImmutableMemory> base;
private:
using base::Resize;
using base::Allocate;
using base::DeAllocate;
public:
CMemory() : base() {}
CMemory(size_t size) : base(size) {}
CMemory& operator = (CMemory& other) = delete;
CMemory& operator = (CMemory&& other) = delete;
};
We also take the extra step of deleting the copy and move assignment operators. This makes perfect sense for what we are trying to do. We need to guarantee that the memory object (not the content of course) represented by the CMemory object is immutable. If we allowed assignment, the state of the objects would change and this is forbidden by the IImmutableMemory interface.
Default Implementations
Because in most cases, the normal process heap is what is desired, I have provided those as defaults:
typedef CMemory<CHeapAllocator, IResizeableMemory> CResizableHeapMemory;
typedef CMemory<CHeapAllocator, IMemory> CHeapMemory;
typedef CMemory<CHeapAllocator, IImmutableMemory> CImmutableHeapMemory;
Using the Code
Using the memory class is very easy. I provide the examples using heap memory. There are two parts to the example.
Memory Management
First, we demonstrate the memory management and copy / move construction and assignment.
CHeapMemory makeMem(int val) {
CHeapMemory mem(sizeof(int));
memcpy(mem, &val, sizeof(val));
return mem;
}
int main()
{
CHeapMemory mem1(sizeof(int));
int val = 42;
memcpy(mem1, &val, sizeof(val));
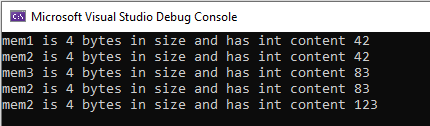
std::cout << "mem1 is " << mem1.Size() << " bytes in size and has int content "
<< *(static_cast<int*>(mem1.Ptr())) << endl;
CHeapMemory mem2 = mem1; std::cout << "mem2 is " << mem2.Size() << " bytes in size and has int content "
<< *(static_cast<int*>(mem2.Ptr())) << endl;
CHeapMemory mem3 = makeMem(83); std::cout << "mem3 is " << mem3.Size() << " bytes in size and has int content "
<< *(static_cast<int*>(mem3.Ptr())) << endl;
mem2 = mem3; std::cout << "mem2 is " << mem2.Size() << " bytes in size and has int content "
<< *(static_cast<int*>(mem2.Ptr())) << endl;
mem2 = makeMem(123); std::cout << "mem2 is " << mem2.Size() << " bytes in size and has int content "
<< *(static_cast<int*>(mem2.Ptr())) << endl;
return 0;
}
As you can see in the copy operation involving mem1, the object is implicitly converted to void* because that conversion exists. When we use static_cast<int*>(mem1.Ptr()), we need to use the Ptr method because static_cast accepts any type, which means the primary type is used and that cannot directly be converted to int*.
The examples involving mem2 and mem3 exist to demonstrate the behavior of the move and copy constructor and assignment.
Type Safety
As mentioned in the introduction, one of the design goals is to have compile time guarantees that the expected behavior matches the supplied arguments, and we do that by playing with the base class when the template is compiled.
That is easy enough to demonstrate, simply by trying to do the wrong thing:
void useMem(IMemory& mem) {
}
void useIMem(IImmutableMemory& mem) {
}
void useRMem(IResizeableMemory& mem) {
}
int main() {
CImmutableHeapMemory immem;
CResizableHeapMemory remem;
CHeapMemory hmem;
useMem(hmem); useMem(remem); useMem(immem);
useRMem(remem);
useIMem(immem);
return 0;
}
One final note though. There is a saying that goes "When using C it is easy to shoot yourself in the foot. C++ makes it harder, but when you do, it will blow your leg clean off". That saying applies here as well. You could do something like this and it will compile and run.
useIMem(*static_cast<IImmutableMemory*>(static_cast<void*>(&remem)));
It should go without saying that if you start doing things like this, all guarantees go out the window, except the guarantee of inevitable disaster. The C++ compiler will not protect you against intentionally doing things like this.
Points of Interest
Writing this article was a bigger challenge than I anticipated. When I started writing this article, I had a very basic non-template resizable memory object that I used in my code a lot. The idea for this article came when I had a situation where the memory object should not be resizable.
The most trivial way to solve this would have been simply hiding the resize method by making it private. However, I thought it would be neat to have a base as a behavioral contract. Then I thought it would also a good idea to foresee the possibility of using different allocators, and things (and hours) spiraled out of control. I learned a lot about templates that I didn't know before. I tried a couple of different approaches before ending up with this one. When things started clicking together elegantly, I knew I was on the right path.
I still have ideas to make this class more useful with extra functionality or to play with different allocators. For example, using this code, it will be trivial to test application robustness by using an allocator that will fail randomly with a certain probability. Those are things I may explore in future articles. As it stands, this article covers a comprehensive implementation of the requirements mentioned in the introduction so this is a good place to stop.
Thank you for reading this far. Comments and votes are appreciated. The code is licensed under the MIT license so have fun with it.
History
- 22nd January, 2023: First version

