Compared to traditional memory pools using linked lists, array-based allocators are less frequently discussed in books and public domain. Nevertheless, they are simple and can deliver substantial performance gains when some loss of space is acceptable.
Layout
Introduction
The general purpose memory management facilities such as operators new and delete in C++ are designed to serve a wide variety of clients with different needs. They provide simple in use tools that are a good choice for many types of practical applications. But, unfortunately, they underperform in some specific use cases. This fact should not be surprising since the general algorithms must be as fast as possible, work with objects of different sizes and minimize memory fragmentation. The last two requirements are not only technically challenging but also can have adverse effect on the overall performance of applications.
To address these issues in software products, programmers apply various methods of custom memory management. These techniques are particularly effective when a user algorithm frequently creates and destroys small size objects. The obvious candidates to benefit from these methods are systems with limited resources. The C++ standard library helps developers by providing support for custom allocators in containers. With the right choice, some operations on standard containers can be made faster by a factor between 3 and 10. To appreciate this fact, consider the competition between Intel and AMD. The advantage of 10-20% in the computation speed is decisive for buyers interested in the best performing processors and systems.
The attractive feature of custom memory management is that some schemes are quite simple. Their complexity level is that of brain teasers and they can be implemented with a small amount of code. While the approaches to custom memory management and allocators are discussed in books for C++ programmers, the simple schemes are often re-discovered by novices. Because of these benefits, custom memory management became one of the tools used by professionals in the performance optimization.
The choice of a custom memory management scheme can be challenging in practice. Some tradeoffs are inevitable. The design decisions have effect on the efficiency of operations required in user algorithms. For example, some allocators can offer very fast allocate operations, but slow or none to deallocate resources for single objects. In this respect, a fixed size memory pool is frequently a reasonable choice. It offers very fast (constant time) allocate and free operations and can be used with some restrictions for object of different types.
Traditionally, a fixed size memory pool is based on a linked list. In this article, we present a simple alternative variant of this memory pool and standard C++ allocator, which uses two arrays. This variant is discussed in public domain less frequently than traditional memory pool. Nevertheless, the array-based variant offers good speed of allocate and free operations and simple implementation code. It has interesting properties and despite some limitations, it can be useful in applications.
Free List
To explain the key ideas, we start the discussion with the traditional memory pool of fixed size blocks, which is normally based on a singly linked list. The name "free list" comes from its representation: a linked list of free memory blocks. The optimal variant might be a bit challenging for the first reading, since its structure is more complex than that of a basic linked list. The complication follows from the fact that its implementation uses two types of linked nodes for chunks and for blocks. One chunk is subdivided into equal size blocks, which are arranged into a chain of a linked list. These memory blocks or regions are initially free and later store objects of a user algorithm. The coarse structure can be viewed as a list of large size chunks, and the fine structure as list of small size blocks. Such complex structure offers the advantage of fine-tuning to obtain the best time and space efficiency.
For the memory pool described in this article below, we reduce this complexity by assuming that one chunk is large enough to contain all of the blocks required in a user algorithm. Then, the simplified pool represents an ordinary singly linked list such as shown in Figure 1.
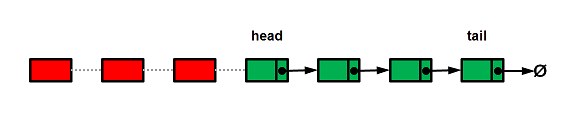
Figure 1: A simplified memory pool using a singly linked list. The nodes with free memory blocks are shown in green. User objects are stored in memory regions provided by red nodes disconnected from the list.
The organization of memory blocks into a linked list plays an important role in achieving the high efficiency of the pool, since it enables us to avoid costly operations such as search for a free block. When a user requests memory for a new object, the pool disconnects the first node from the list and delivers memory block of the node to the user. When the user returns an object no longer needed, its memory block is added as a new node and becomes first in the list. The fact that explains the high performance of the memory pool is that it uses one end of the linked list for two operations that take constant time.
This is interesting, because there are other data structures that support the required operations. Thus, in theory, a singly linked list can be replaced. But before we search for an alternative, it makes sense to have a look at these two operations again. And it is not too difficult to notice that these operations are basic pop and push operations of a stack. This sounds like a discovery, simple but not immediately obvious:
The linked list in the memory pool represents a stack.
The rest is easy.
Array Pool
It is well known that stack operations are supported by several data structures. For this reason, in the C++ standard library class template stack is a container adaptor. It can be instantiated with three standard containers: list, vector and deque. None of them is suitable for our variant of memory pool, since standard containers are clients of custom allocators that we are going to develop. To avoid over engineering of our solution, we should use basic C++ tools. Nevertheless, the design of class template stack suggests how to replace a singly linked list in the traditional memory pool. We simply have to find the most efficient data structure for the stack representation. Our choice of an array is "natural", since in terms of support for push and pop operations, a linked data structure cannot compete in speed with an array.
The additional bonus of this choice is that a stack array enables us to store pointers to blocks separately from an array of blocks. This feature is different from a pool using a linked list where pointers to next nodes are inside fixed size blocks (see green nodes in Figure 1). The resulting array-based variant of the traditional memory pool consists of two arrays as shown in Figure 2.

Figure 2: Illustration of an array-based memory pool in a general state. The lower array is the storage of the pool. Its free blocks are shown in green. Blocks that store user objects are in red. The upper array represents a stack of pointers to free blocks in the storage array.
Note the important difference between these two arrays. The stack array always consists of two contiguous memory regions, whereas the storage array is fragmented in the general case, since user objects can be stored at arbitrary (not necessarily random) positions. In other words, positions of free and allocated blocks in the storage do not mirror matching positions in the stack. The only restriction is that each user value resides in the storage array.
If required, a contiguous arrangement of free and allocated blocks in the storage array (see Figure 3) can be obtained by using operations on one end. For example, append values to an end of a user container and remove values from the end. However, this approach is too strict for many practical applications. The allocate and free operations on arbitrary objects in a user algorithm will destroy the perfect contiguous arrangement of the storage shown in Figure 3. After some execution time, pool storage will be in a general state similar to that in Figure 2. At the same time, the stack array remains gapless after any pool operation.
Figure 3: Contiguous storage of free and used blocks produced by a sequential input of a given dataset.
The same dataset can be scattered throughout system memory or localized in a small region. The useful measure of the compactness of a dataset is known as locality of reference. The key factor of excellent performance of memory pools is their high space efficiency. It enables a user algorithm to place the maximum possible number of objects in the fastest but the smallest system memory such as processor cache. In this respect, the array-based memory pool borrows the best features from its predecessor and offers important enhancements.
First, each memory pool discussed here guarantees better spatial locality of reference than general memory management facilities. This superiority follows from the fact that all user data are confined in one chunk, although they are arbitrarily distributed in the given memory region. Second, similar to the traditional fixed size memory pool, the array-based variant does not need to save the size of each memory block.
When it comes to differences, the most significant one is that the storage of an array-based memory pool does not contain implementation specific connectivity data. The equivalents of links to nodes are pointers to blocks. They are not required during the execution of a user algorithm and thus reside in a separate stack array. In addition, the array storage does not place any restriction on the block size, whereas in traditional pool, it cannot be smaller than the link size. As a result, a dataset in the storage can be made more compact to process a greater number of objects in fast memory than a pool using a linked list. For small size objects, this advantage is significant, especially, when the life time of objects in a user algorithm is much longer than their creation and destruction time.
The minimum limit for the blocks size in the traditional pool is a challenge for the development of the most efficient programming solutions. An interesting approach to overcome this limitation has been suggested by A. Alexandrescu [1] in Chapter 4 "Small-Object Allocation". Similar to a basic variant, all fixed size blocks of one chunk are arranged into a singly linked list. The difference is that links in this list are represented by indices of type byte instead of pointers. This trick enables clients to reduce the size of a block down to one byte only, which is significant improvement of space efficiency compared to pointer-based memory pool on a 64-bit system. However, the price of this improvement is that one chunk can store at most 255 objects. For a greater number of objects, this custom allocator needs a container of chunks (std::vector in the book). The complexity of code increases and the worst case performance degrades due to additional operations on chunks.
The array-based memory pool presented in this article provides a simple efficient general purpose and portable tool. It offers for user algorithms both very fast allocate and free operations and also cache optimized storage for datasets. It works with arbitrary number of values and arbitrary size of blocks and does not suffer from limitations of the traditional memory pool.
Implementation
Custom memory management is a huge area with numerous variants and variations. To avoid less significant details and focus on the main features, we provided a simple demo. The code is designed to be a starting point for the development of specialized and advanced variants of array-based memory pools and allocators. In order to help clients work with objects of different types, we select a pool, which allocates and frees single blocks of a fixed size of uninitialized memory. A minimal variant of such an array-based pool can look something like this:
template< unsigned int num_blocks, unsigned int block_size>
class ArrayPool
{
byte arr_bytes[num_blocks*block_size] ;
byte* arr_stack[num_blocks] ;
int i_top ;
public:
ArrayPool( ) : i_top(-1)
{
byte* p_block = arr_bytes ;
for ( int i = 0 ; i < num_blocks ; ++i, p_block+=block_size )
arr_stack[i] = p_block ;
i_top = num_blocks-1 ;
}
void* Allocate( )
{ return reinterpret_cast<void*>( arr_stack[i_top--] ) ; }
void Free( void* p_back )
{ arr_stack[++i_top] = reinterpret_cast<byte*>(p_back) ; }
bool IsEmpty( ) const { return i_top < 0 ; }
bool IsFull ( ) const { return i_top == (n_blocks-1) ; }
} ;
The key data members of the pool are two arrays: arr_bytes and arr_stack, which represent contiguous regions of storage for user objects and a stack to manage the storage. i_top is an index of a current top element in the stack.
The constructor of the pool fills the stack array with pointers to all blocks in the storage. In the initial state of the pool, all blocks of the storage are free, the stack is full. If we ignore reinterpret_cast in the code above, then Allocate() and Free() are just pop and push operations on a stack of pointers to blocks in the pool storage. The destructor releases all resources acquired during initialization. Thus, similar to the traditional memory pool, there is no need to deallocate objects one by one when client finished processing data of built-in types.
And this is all in terms of the main implementation details. Arrays are easy to work with. They make code for this variant of pool simpler than for variants using linked lists. The array-based pool in the attached file is only a bit more technical.
In terms of applications of this pool in C++ code, there are two options: provide class specific memory management operators or allocators for standard containers. We choose stateless allocator, which was introduced in the original version of STL [2]. Using the array-based pool for support of STL compliant allocator enables us to measure performance of a wide variety of algorithms, containers and their underlying data structures.
class ArrayAllocatorSTL represents a stateless C++ allocator. In this class, an object of ArrayPool is used as a static data member. All instances of one allocator type operate on the same memory or resource. This allocator can be used with node-based STL containers: forward_list, list, set, multiset, map and multimap. The base class AllocrBaseSTL has been introduced for better code structure. It provides type definitions for C++ standard compliant allocator and member functions, which are less relevant to the explanation of the array-based pool and allocator.
The demo code works in Visual Studio 2019 and Android Studio. However, there is no guarantee that it will compile in some old or future versions of STL, since C++ standard specifications for allocators are not stable. In the case of compilation errors, check your compiler for compliance to a specific standard version and update code in class AllocrBaseSTL and ArrayAllocatorSTL.
Performance Gains
The attached code provides performance tests for a few basic operations on standard containers. The running times of the tests vary from system to system. This is not unexpected. What is more challenging for the analysis is that the measured values may vary in a wide range on the same system. In this case, the most significant is the effect of system cache algorithms. Its signs are that the run times depend on the order of execution of algorithms and on the size of a dataset. Another complicating factor is that a system may not support high resolution timer. For these reasons, obtaining consistent and reproducible values of running times in the performance tests is not always an easy task. In general, Windows systems with powerful Intel and AMD processors produce results with smaller deviations than Android systems.
The performance gain (or improvement) measured for this article represents the ratio of two running times of an algorithm with STL default and array-based allocators. As discussed above, space efficiency of a dataset is the key factor of achieving high performance. This is why, improvements are more significant for small objects: the smaller object size, the greater performance gain. Another aspect of the space efficiency is the choice of the best data structure for a user algorithm. This is a typical optimization task in solutions based on interchangeable STL containers. In terms of dynamically allocated data structures, the best performance gain is observed for singly linked list (forward_list), which has the smallest size of implementation specific data - one link per node only. The second best is a doubly linked list (list), which has two internal links to nodes. This data structure is more space efficient than a red-black tree (set). Such results reflect the effect of internal data on the performance of user algorithms.
The array-based allocator has been tested on a number of Android mobile devices and Windows computers. Here, we focus on a couple of interesting results for Windows systems. Android devices will be discussed elsewhere.
For this article, we have selected two Windows computers. The first is HP work station with Intel 7 Core 3770 processor. The second is HP mobile works station with I7 1165G processor. To test performance gains of the allocation speed delivered by the array-based allocator, we used operations on one end of singly and doubly linked lists:
| N | 1,000 | 10,000 | 100,000 | 1,000,000 |
std::forward_list<size_t>::push_front() |
| I7 3770 | 18 | 15 | 16 | 14 |
| I7 1165G | 51 | 31 | 28 | 24 |
std::list<size_t>::push_back() |
| I7 3770 | 7.2 | 7.3 | 7.0 | 6.3 |
| I7 1165G | 32 | 16 | 12 | 14 |
The first observation is general. On both systems, performance gains for a singly linked list are greater than for a doubly linked list. This result validates the point mentioned earlier: the higher time efficiency is closely related to the higher space efficiency.
If we now continue the analysis of specific values, we can reveal yet another interesting fact. It is not clear how reliable is the gain of 51, but it is evident that the new system consistently and significantly outperforms the older one. Why this result is surprising? The common belief is that custom memory management is first of all beneficial for systems with limited resources. The next obvious question: why the new system provides such significantly better performance gains than older? In order to answer this question, let us compare parameters of L1, L2 and L3 cache, note that both processors have four cores:
| | L1 | L2 | L3 |
| I7 3770 | 256 KB | 1 MB | 8 MB |
| I7 1165G | 320 KB | 5 MB | 12 MB |
The significant advantage of the new system is larger size of L2 cache: 5 MB against 1 MB. Another difference is that in I7 1165G L1 size per core is 80 KB, whereas in I7 3770 - 64 KB. Compared to L2 this is not a big increase, nevertheless in our tests it might be responsible for the sharp growth of performance gain when the number of elements goes down to zero.
The performance improvement on the new system is fantastic and tells us that we should replace old computers immediately. But this is not the end of the story. There is one weird finding. If we test on both systems, the same algorithms with the default allocator and compare their running times in microseconds, we will notice that the new system is slower (!) than the old one, and this is definitely not a good news.
| N | 1,000 | 10,000 | 100,000 | 1,000,000 |
std::forward_list<size_t>::push_front() |
| I7 3770 | 43.2 | 370 | 3865 | 40110 |
| I7 1165G | 102 | 534 | 4817 | 43260 |
| ratio | 2.36 | 1.44 | 1.25 | 1.08 |
std::list<size_t>::push_back() |
| I7 3770 | 45.6 | 438 | 4602 | 47400 |
| I7 1165G | 123 | 598 | 5228 | 50050 |
| ratio | 2.70 | 1.37 | 1.13 | 1.06 |
From these measurements, it can be seen that processor cache and proper algorithms in the new system are optimized for arrays rather than classical linked data structures. This fact explains the superior performance gains delivered by the array-based allocator in the new system.
As mentioned in our previous discussion, the array-based memory pool and allocator offer a compact storage for user datasets. This is why, we can expect that during the lifetime of objects in the allocator, the high space efficiency will improve the time efficiency of user algorithms. One of the simplest ways to check the lifetime performance is to measure the running time of a sequential algorithm, such as summation. In these tests, the performance gains against default allocator vary in the range from 1.0 to 2.5. Although these values are not as impressive as in the previous test, they can be good enough for many practical applications.
Before we switch to limitations, let us summarize the results of performance tests. First, they confirm that not only systems with limited resources can benefit from custom memory management. The technique is also effective in computers with powerful processors. Second, the comparison of performance gains on similar systems of different generations shows that the use of array-based pools and allocators is more beneficial on the latest computers due to increase in the computational power. In terms of hardware, CPU speed is not the only factor of overall performance. Another important parameter of a system is the size of fast memory at each level of processor cache. The computers with large amount of fast memory are the most suitable for array-based pools and allocators. When some loss of space is acceptable, such systems can deliver substantial performance gains.
Limitations
The custom allocators are generally useful, since they improve speed of creation and destruction of objects. However, the overall performance also depends on the lifetime of objects and how they are used in algorithms. It is not unusual that custom memory management does not deliver expected performance gain.
Unlike a traditional memory pool using a linked list, the array-based variant described here is not flexible. It has a strict upper bound on the capacity and, thus, the maximum number of objects that it can store. Due to this restriction, programmers face the non-trivial dilemma of choosing the right size of the allocator arrays. If allocator storage is too small for all user objects, the allocator will underperform. If the storage is too large, many blocks will remain unused.
In theory, the array-based allocator improves performance by a constant factor. In practice, there is effect of locality of reference, which should be measured if it complicates results and analysis. The downside of this effect is that performance gains are system specific. The optimal performance of a user algorithm depends on CPU multi-level cache.
Extending functionality of the array-based memory pool and allocator is not too challenging. Each new feature enables us to serve more user algorithms and data structures. However, it makes implementation of allocate and free operations more complicated and less efficient. It is very unlikely that duplicating functionality of the default memory management operators will be beneficial. Memory pools and allocators are tools to develop efficient but specialized variants of algorithms and data structures. Since there is significant gap between brainteasers and computer science, the practical rule for custom memory management is "the simpler, the better".
What to do if performance improvement is not acceptable?
In short, analyze a given algorithm, find and fix its performance bottlenecks. The ultimate approach is to redesign and reimplement the required algorithm.
What to do if achieved performance is still not good enough?
Tell your manager or client that it is time to buy a quantum computer. There is always room for performance improvements.
References
- A. Alexandrescu. Modern C++ Design. Addison Wesley, 2001.
- B. Stroustrup. The C++ Programming Language. Third Edition, Addison Wesley, 2007.
History
- 30th January, 2023: Initial version
- 6th February, 2023: Added references

