Beginners tutorial on PE format, with illustrations. Planned to be an easy-to-follow overview tutorial with a lot of illustrations, without going into all the details. We tried to focus on the big picture.
1. Illustrated Tutorial
This is planned to be an illustrated tutorial on PE file format. Many tutorials I saw are overwhelmed with details, going over all the different possibilities and branches for PE file format [9], with the end result that they become hard to follow. Our plan is to provide an overview tutorial focused on the big picture with a number of illustrations, and the reader will later find more details elsewhere if he is interested in the topic.
1.1. Tools Used – Hex Editor ImHex
I am using Hex Editor ImHex (freeware) which enables me to color sections of files ([1]).
1.2. Tools Used – PE Viewer “PE-bear”
PE-bear (freeware) is a very useful tool to analyze PE files visually. Based on the documentation, it does not cover all variants and flavors of PE files, but for simpler ones, it is a great viewer/parser/analyzer. I think it is always easier to study topics using visual tools. ([2])
2. Executable File Formats
Before we start our exploration of PE format, let us mention that PE format belongs to a family of “executable file formats” which are nicely listed at [3], around 40 of them, for different Operating Systems. Let us mention several of the most popular ones:
- MZ – For DOS and Windows, extension .exe
- COFF - For UNIX/Linux-like systems, no extension
- ELF - For UNIX/Linux-like systems, no extension or extension .elf
- Mach-O – For macOS and iOS, no extension
- PE - For Windows, extensions .exe, .dll, .sys, etc.
- PE32+ - For 64-bit Windows, extension .exe
Please see [4] for more details on PE and PE32+ formats.
3. History of PE File Format
PE stands for ‘Portable Executable” and the format is invented in the 1980s. The dominant format then was MZ MS-DOS format, which has a special marker at the beginning of file to identify itself, letters “MZ” which by the way are initials of Mark Zbikowski, one of the MS-DOS developers. PE format was about to target Window platform, and they preserved backward compatibility with MZ format (.exe files) and enabled PE format (.exe files) if accidentally run on MS-DOS to report “This program cannot be run in DOS mode”, which was an important issue for Microsoft at the time. Therefore, you will see still that PE format contains MS-DOS style header, meaning it starts with the magic letters “MZ” and also a DOS-Stub that prints that message. That part is unnecessary today but has become part of the standard.
PE format originates from Unix COFF format.
Today, PE format is extended to host .NET code.
4. Technical Details
4.1. Problems PE was Designed to Solve
- Designed to support different programs on different hardware
- Idea was to separate the program from the processor
- Address the move to 64-bit processors
4.2. Loading PE File into Memory
- The physical layout of how bytes of PE file are arranged on the disk is not how they are loaded into memory
- PE file contains several sections, and to avoid wasting space, they are aligned one after the other on the disk
- PE file contains several sections, containing data and programs, and each section is loaded into a separate segment of memory
- Reason for that, among others, that each section needs to be aligned to a page boundary
- Then, each section can be assigned different memory protection, typically program sections would get execute/read-only protection, and data sections would get no-execute/read-write protection.
- For that reason, most addresses/offsets in the file are specified using Relative Virtual Address (RVA). This specifies the offset from the start of each section
Here is a picture that illustrates how different section look aligned in “raw alignment” on the disk, and how they are being loaded into memory (‘virtual alignment”) into different virtual addresses resulting in new address schema.
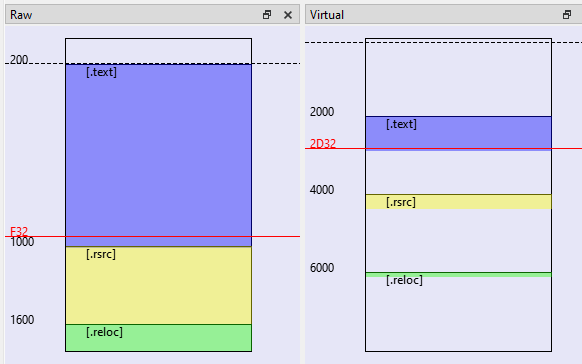
4.3. Converting from “Raw Address” to “Virtual Address” and back
- Tasks that will frequently appear are conversions from “Raw Address” (how bytes are aligned in the file) to “Virtual Address” (how bytes are aligned in the memory) and back, using Relative Virtual Address (RVA).
- For example, in the above picture, you can see that .text section starts at 0x200 (raw) and has end at 0xF32 (raw). That means, file end has offset of 0xF32(raw)-0x200(raw)=0xD32 from beginning of the section. When that section .text is mapped to memory address 0x2000(virtual), then end of section has address 0x2000+0xD32=0x2D32(RVA). We say that address of the end of section is 0x2D32(RVA).
5. Example Program
We will for our demo use a simple C#11/.NET-7, “Hello World” program, where we created resource file for the string “Hello World!”. As you will see, .NET assemblies are packaged into PE file format. We complied it as C#11/.NET7.
6. PE Format Definition
The precise definition of PE format can be found in [5]. For the purpose of this tutorial, and to follow the outline of PE-bear tool, we will define it here as:
A typical PE file consists of the following parts:
- DOS Header (aka “MZ Header”)
- DOS Stub
- NT Header, (aka “PE File Header”)
which itself consists of:
- PE signature
- File Header (aka “COFF Header”, “Image File Header”)
- Optional Header (aka “Image Optional Header”)
which itself consists of:
- General part
- Data Dictionary
- Sections Headers (aka “Section Table”)
- Multiple sections (aka “Sections”)
- Section 1
- Section 2
- …
- Section n
Here is a look at the headers in Hex editor, focus on headers:

Here is a look at the whole file, just to get an idea of how headers are a small part (in quantity) of the file.
Here is how the PE-bear tool outlines it in its interface:
7. DOS Header (aka “MZ Header”)
Here is DOS Header in the Hex editor:
Here is an analysis of DOS Header by tool PE-bear:
Interpretation:
- Note that the header starts with “Magic number” 0x5A4D” which stands for “MZ” (which by the way are initials of Mark Zbikowski, one of the MS-DOS developers) which acts as a file format identifier
- Note at offset 0x3C, there is address of new exe header, which is 0x80, pointing to “NT headers”
8. DOS Stub
Here is DOS Stub in the Hex editor:
Interpretation:
- This is a small piece of code that is DOS compatible that just prints an error message saying “This program cannot be run in DOS mode”, in case the program is run under DOS.
9. NT Headers, (aka “PE File Header”)
Here are NT Headers in Hex editor:
9.1. NT Headers - Signature
Interpretation:
- That is just 4 bytes starting with “PE” indicating that this is PE format.
9.2. NT Headers - File Header (aka “COFF Header”, “Image File Header”)
Here is an analysis of the File Header by tool PE-bear:
Interpretation:
- Note at offset 0x88 it says this file will contain 3 sections. For a fixed section-header size, OS can calculate the size of Section -Headers and how many entries in Section-Headers to look for.
- Note at offset 0x94, it says the size of the Optional Header.
9.3. NT Headers - Optional Header (aka “Image Optional Header”)
Here is an analysis of the Optional Header by tool PE-bear:
Interpretation:
- This header contains some additional information beyond the basic one contained in the basic File Header
- Look at file offset 0x98, so called Magic. It actually says which file type is it. 0x10B stands for PE32 format.
- It is interesting to look at file offset 0xA8, for Entry Point. It says address 0x2D32(RVA), which we need to convert to raw address, that it is 0x2D32-0x2000+0x200=0xF32(raw file). That is in the area of section .text. The address of the entry point is the address where the PE loader will begin execution. For the program image, this is the starting address.
9.3.1. NT Headers - Optional Header – Data Dictionary
Interpretation:
10. Section Headers (aka “Section Table”)
Here are the Section Headers in the Hex editor:
Here is an analysis of the Section Header by tool PE-bear:
11. Multiple Sections (aka “Sections”)
11.1. Section Names
Sections can have any 8 character name starting with “.”. But usual conventions are:
- .text – contains executable code and data
- .idata, .rdata – contains Import API
- .data, .bss– contains data
- .pdata – contains exception info
- .reloc – contains relocation info
- .rsrc – contains resources
- .debug – contains debug information
11.2. Section .text
Here is Section .text in Hex editor:
Interpretation:
- In our case, since this is .NET assembly, this section contains:
- Metadata
- Managed resources
- IL code
11.3. Section .rsrc
Here are Section .rsrc in Hex editor:
Here is an analysis of Section .rsrc by tool PE-bear:
Interpretation:
- You can see both from Hex Editor and PE-bear analysis (seems like unfinished app here?) that this section contains info about the version and the Application manifest.
- These are UNMANAGED resources. Managed .NET resources are inside the section .text .
11.4. Section .reloc
Here is Section .reloc in Hex editor:
Here is an analysis of Section .reloc by tool PE-bear:
12. Conclusion
We will finish here in order to make this tutorial of manageable size. We gave a basic description of the PE format, sufficient for a good technical overview and the interested reader can find more details elsewhere. We didn’t dive into too many details in this article.
More details about PE File Format can be found at [6], [7], [8]. A very interesting slide illustrating different options of PE format can be found at [9].
13. References
14. History
- 10th March, 2023: Initial version

