Many users want to convert documents for personal use, formatted for the viewing applications they are familiar with. There are several conversion tools available but for documents that are DRM protected, the number of free tools are particularly limited. Calibre is one of those free tools and is used, with a DeDRM extension, to convert Kindle books to a variety of other formats. Furthermore, in the case of Kindle books, the DeDRM tool requires that the book be downloaded using an older copy of the Amazon Kindle app that can provide the file format supported by the DeDRM extension. gbCapture can capture document text content from the document’s native viewer without the need for DRM removal.
For a simple capture, gbCapture is run in “mini” mode, as shown in this image:
For evaluating all of the gbCapture settings, selectively extracting pages, viewing details of extracted text/images and to just generally better understand how gbCapture works, the following user interface is also supported.

Introduction
I work with low vision users – particularly folks with macular degeneration. Their loss of eyesight is a great disappointment for them, in no small part because it prevents them from reading books, such as those they buy from Amazon. Native book reading apps such as the Kindle app do not allow low vision users to adjust the way the book content is displayed, at least not to the degree that low vision users require. A product of mine called EZReader allows low vision users to reformat the books so they can better see the content, as well as to read the content out loud. But, EZReader only works with text content so conversion of the Kindle book to text is required to allow display of the book in EZReader.
So, the purpose of this article is to demonstrate a straightforward technique for converting protected documents, such as DRM protected Kindle books, to text. I call the utility gbCapture and its interface is designed so that even low vision users can successfully convert their DRM-protected books to text for import into EZReader or for conversion to other formats by other conversion applications.
One of the best known, and free, solutions to converting DRM-protected books to other formats is Calibre. Like other available solutions, it requires the use of a DeDRM extension. And in the case of Kindle books, it also requires that the book be downloaded with an earlier version of the Kindle app, one that downloads the books in a format that DeDRM supports.
With gbCapture, the text is extracted by viewing the book in its native viewer (such as in any version of the Kindle app), taking a picture of each page in the document and using OCR (tesseract) to extract the text. gbCapture automates the process, capturing each page one at a time then turning the page in the native viewer until the end of the document is reached. When the last page is captured, the extracted text will be merged into a single text file.
The Article Body
gbCapture is written in the PowerBASIC language, whose ability to directly access Win32 API particularly makes it easy to supplement the PowerBASIC statements. gbCapture makes heavy use of the Win32 API.
Let’s go through the basic operation of gbCapture, then I’ll highlight several areas and provide code examples for the more critical gbCapture procedures. I’ll use the Kindle app for the discussion but gbCapture can also work on other applications (Word, WordPad, NotePad, etc.) that display documents.
To begin a book capture, open the Kindle app to display a book. The app should be placed in the center of the desktop and sized to ensure that the pages to be captured have margins around the text. gbCapture automatically detects the app which covers the center of the desktop. It also detects the Window within the app that contains the displayed text.
With gbCapture opened in “mini” mode off to the side of the Kindle app, simply press Capture on the gbCapture toolbar. gbCapture will take a picture of the currently viewed page, extract the text, turn the page and then repeat the process until it reaches the end of the book. “End of Book” is determined by two consecutive captures returning the same text.
Here’s an image the gbCapture provides to confirm to the user that the windows containing the text has been identified.
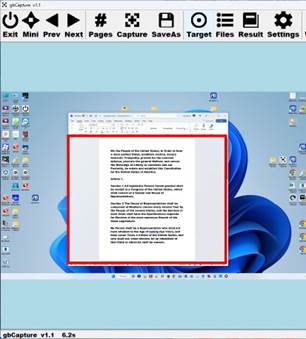
Once Capture is pressed, gbCapture begins the automated capture/extract text/turn page procedure. The gbCapture statusbar will indicate progress. Capture will stop automatically when the end of the book is reached. The user can manually stop the capture at any time.
Key Code Sections
The majority of the code is very straight forward and does not require any in-depth discussion. However, I’ve selected a few of the procedures for additional discussion. The window containing the text is found using the appropriate Win32 API.
Sub GetHandles
Local pt As Point
Desktop Get Client To pt.x, pt.y
pt.x = pt.x/2 : pt.y = pt.y/2
hCenterWindow = WindowFromPoint(pt)
hCenterApp = GetParent(hCenterWindow)
End Sub
gbCapture provides two ways in which to capture an image of the text – one by capturing only the container window and another by capturing the entire desktop following by extracting the container window. Here’s the code for capturing the container window. Not all viewing apps respond to both approaches, so gbCapture allows the user to select which to use. PowerBASIC provides a number of “Graphic” statements to make it easier to work with images. In particular, the statement “Graphic Bitmap” is a PowerBASIC statement that creates an in-memory bitmap structure, whose DC is used in the following capture code.
Sub CapturePageImage_Window
'Capture Image to ImgName
Local hPageDC, hBMP, hBMPDC As Dword, w,h As Long
GetWindowRect hCenterWindow, rcCenter
hPageDC = GetDC(hCenterWindow)
w = rcCenter.Right - rcCenter.Left
h = rcCenter.Bottom - rcCenter.Top
Graphic Bitmap New w,h To hBMP
Graphic Attach hBMP, 0
Graphic Get DC To hBMPDC
BitBlt hBMPDC, 0, 0, w, h, hPageDC, 0, 0, %SRCCopy
ReleaseDC %Null, hPageDC
Graphic Save ImgName
Graphic Bitmap End
Statusbar Set Text hDlg, %IDC_Statusbar, 1,0, " Image: " + PathName$(Namex,ImgName)
End Sub
With the page image captured, the tesseract OCR library is used to extract the text. The time to complete a page image capture and to extract the text depends on the user’s PC capability, but in general might take up to 1s per page capture. This means that a complete book of 600 page would take about 10 minutes – much slower than other available tools, but still without the need for removing the document DRM protection.
Sub ExtractTextFromImage
Local ExtractedText$
'extract and clean the text using Tesseract
Shell ($Tesseract + " --psm " + IIf$(MultiColumn,"4 ","1 ") + _
ImgName + " " + PathName$(Path,TextName) + _
PathName$(Name,TextName), 0) 'wait for it to finish
Statusbar Set Text hDlg, %IDC_Statusbar, 1,0, " Text: " + PathName$(Namex,TextName)
Open TextName For Binary As #1 : Get$ #1, Lof(1), _
ExtractedText$ : Close #1 'get extracted text
CleanText(ExtractedText$)
If LastText$ = ExtractedText Then 'end of document
If IsFile(ImgName) Then Kill ImgName
If IsFile(TextName) Then Kill TextName
StopCapture = 1
Exit Sub
Else
LastText$ = ExtractedText$ 'for comparison, to know when stop
End If
Open TextName For Output As #1 : Print #1, _
ExtractedText$; : Close #1 'save cleaned, but not formatted,
'extracted text
'append the extracted text to $Document
Open $Document For Append As #1
If AutoParagraphFormatting Then ParagraphFormatting(ExtractedText$)
Print #1, $CrLf + ExtractedText$ + IIf$(UsePageNumbers, _
$CrLf + "Page: " + Str$(ActionCount) + $CrLf, "") ;
Close #1
Statusbar Set Text hDlg, %IDC_Statusbar, 1,0, " Text: " + PathName$(Namex,TextName)
End Sub
Once the current page is captured and its text extracted, the viewing page is sent a Next Page command by giving focus to the application and sending a Page Down keystroke to the center application. Both key down and key up are sent to the center app.
Sub NextPage
SetFocus hCenterApp
SetForeGroundWindow hCenterApp
keybd_event(%VK_NEXT, 0, 0, 0)
keybd_event(%VK_NEXT, 0, %KEYEVENTF_KEYUP, 0)
End Sub
Conclusion and Points of Interest
For capturing text from a document, gbCapture offers an alternative to other existing solutions. In particular, it can extract text from protected documents without having to enable document editing or to break the document DRM protection or without using a specific version of the native file viewer. With the text in hand, users can turn to other conversion applications to create documents in other formats.
History
- 20th March, 2023: Initial version

