Rapid technology innovation is driving a new era of heterogeneous computing. Hardware diversity and growing computational demands require programming models that can exploit heterogeneous parallelism. These models must also be open and portable so that programs can run on hardware from different vendors. Though decades old, Fortran is still an active and important programming language in science and engineering. Likewise, OpenMP*, the open standard for compiler-directed parallelism released in 1997, has evolved to support heterogeneity. It now includes directives to offload computation to an accelerator device and to move data between disjoint memories. The concepts of host and device memory, and other more subtle memory types, like texture/surface and constant memory, are exposed to developers through OpenMP directives.
Offloading tasks to accelerators can make some computations more efficient. For example, highly data parallel computations can take advantage of the many processing elements in a GPU. This article will show how Fortran + OpenMP solves the three main heterogeneous computing challenges: offloading computation to an accelerator, managing disjoint memories, and calling existing APIs on the target device.
Offloading Computation to an Accelerator
Let’s start with an example. Figure 1 shows how the OpenMP target, teams, and distribute parallel do constrcuts execute a nested loop. The target construct creates a parallel region on the target device. The teams construct a league of teams (i.e., groups of threads). In the example, the number of teams is less than or equal to the num_blocks parameter. Each team has a number of threads less than or equal to the variable block_threads. The primary thread of each team executes the code in the teams region. The iterations in the outer loop are distributed among the primary threads of each team. When a team’s primary thread encounters the distribute parallel do construct, the other threads in its team are activated. The team executes the parallel region and then workshares the execution of the inner loop. This is shown schematically in Figure 2.
program target_teams_distribute
external saxpy
integer, parameter :: n = 2048, num_blocks = 64
real, allocatable :: A(:), B(:), C(:)
real :: d_sum = 0.0
integer :: i, block_size = n / num_blocks
integer :: block_threads = 128
allocate(A(n), B(n), C(n))
A = 1.0
B = 2.0
C = 0.0
call saxpy(A, B, C, n, block_size, num_blocks, block_threads)
do i = 1, n
d_sum = d_sum + C(i)
enddo
print '("sum = 2048 x 2 saxpy sum:"(f))', d_sum
deallocate(A, B, C)
end program target_teams_distribute
subroutine saxpy(B, C, D, n, block_size, num_teams, block_threads)
real :: B(n), C(n), D(n)
integer :: n, block_size, num_teams, block_threads, i, i0
do i0 = 1, n, block_size
do i = i0, min(i0 + block_size - 1, n)
D(i) = D(i) + B(i) * C(i)
enddo
enddo
end subroutine
Figure 1. Offloading a nested loop to an accelerator using OpenMP* directives (shown in blue)
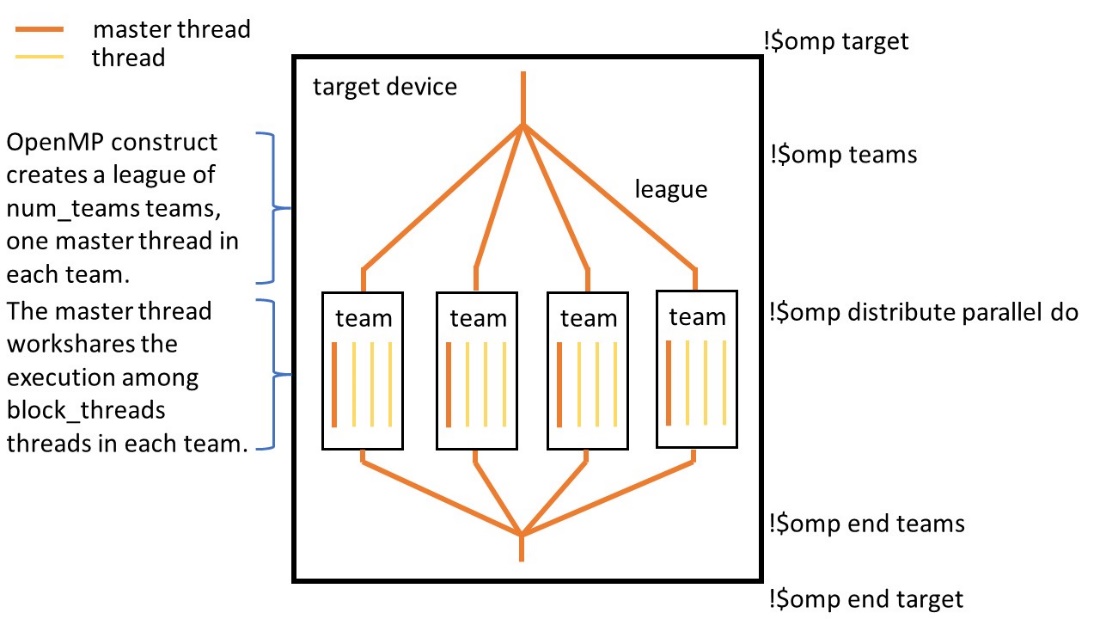
Figure 2. Conceptual diagram of the OpenMP* target, teams, and distribute parallel do regions
Host-Device Data Transfer
Now let’s turn our attention to memory management and data movement between the host and the device. OpenMP provides two approaches. The first uses the data construct to map data between disjoint memories. In Figure 1, for example, the map(to: B, C) and map(tofrom: D) clauses on the target directive copy arrays B, C, and D to the device and retrieve the final values in D from the device. The second approach calls the device memory allocator, an OpenMP runtime library routine. This article will not cover the latter approach.
In Figure 3, the target data construct creates a new device data environment (also called the target data region) and maps arrays A, B, and C to it. The target data region encloses two target regions. The first one creates a new device data environment, which inherits A, B, and C from the enclosing device data environment according to the map(to: A, B) and map(from: C) data motion clauses. The host waits for the first target region to complete, then assigns new values to A and B in the data environment. The target update construct updates A and B in the device data environment. When the second target region finishes, the result in C is copied from the device to the host memory upon exiting the device data environment. This is all shown schematically in Figure 4.
program target_data_update
integer :: i, n = 2048
real, allocatable :: A(:), B(:) ,C(:)
real :: d_sum = 0.0
allocate(A(n), B(n), C(n))
A = 1.0
B = 2.0
C = 0.0
do i = 1, n
C(i) = A(i) * B(i)
enddo
A = 2.0
B = 4.0
do i = 1, n
C(i) = C(i) + A(i) * B(i)
enddo
do i = 1, n
d_sum = d_sum + C(i)
enddo
print '("sum = 2048 x (2 + 8) sum:"(f))', d_sum
deallocate(A, B, C)
end program target_data_update
Figure 3. Creating a device data environment.

Figure 4. Host-device data transfer for the OpenMP* program shown in Figure 3. Each arrowhead indicates data movement between the host and device memories.
The command to compile the previous example programs using the Intel® Fortran Compiler and OpenMP target offload on Linux* is:
$ ifx -xhost -qopenmp -fopenmp-targets=spir64 source_file.f90
Using Existing APIs from OpenMP Target Regions
Calling external functions from OpenMP target regions is covered in Accelerating LU Factorization Using Fortran, oneMKL, and OpenMP*. In a nutshell, the dispatch directive tells the compiler to output conditional dispatch code around the associated subroutine or function call:
call external_subroutine_on_device
If the target device is available, the variant version of the structured block is called on the device.
Intel Fortran Support
The Intel® Fortran Compiler (ifx) is a new compiler based on the Intel Fortran Compiler Classic (ifort) frontend and runtime libraries, but it uses the LLVM (Low Level Virtual Machine) backend. See the Intel Fortran Compiler Classic and Intel Fortran Compiler Developer Guide and Reference for more information. It is binary (.o/.obj) and module (.mod) compatible, supports the latest Fortran standards (95, 2003, 2018) and heterogeneous computing via OpenMP (v5.0 and v5.1). Another approach to heterogeneous parallelism with Fortran is the standard do concurrent loop:
program test_auto_oft load
integer, parameter :: N = 100000
real :: a(N), b(N), c(N), sumc
a = 1.0
b = 2.0
c = 0.0
sumc = 0.0
call add_vec
do i = 1, N
sumc = sumc + c(i)
enddo
print *,' sumc = 300,000 =', sumc
contains
subroutine add_vec
do concurrent (i = 1:N)
c(i) = a(i) + b(i)
enddo
end subroutine add_vec
end program test_auto_offload
Compile this code as follows and the OpenMP runtime library will generate device kernel code:
$ ifx -xhost -qopenmp -fopenmp-targets=spir64 \
> -fopenmp-target-do-concurrent source_file.f90
The ‑fopenmp‑target‑do‑concurrent flag instructs the compiler to generate device kernel for the do concurrent loop automatically.
The OpenMP runtime can provide a profile of kernel activity by setting the following environment variable:
$ export LIBOMPTARGET_PLUGIN_PROFILE=T
Running the executable will give output
Look for the subroutine name “add vec” in the output when the program is executed, e.g.:
Kernel 0 :
__omp_offloading_3b_dd004710_test_auto_offload_IP_add
_vec__l10
The Fortran language committee is working on a proposal to add reductions to do concurrent in the 2023 standard, i.e.:
Closing Thoughts
We’ve given an overview of heterogeneous parallel programming using Fortran and OpenMP. As we’ve seen in the code examples above, OpenMP is a descriptive approach to express parallelism that is generally noninvasive. In other words, the underlying sequential program is still intact if the OpenMP directives are not enabled. The code still works on homogeneous platforms without accelerator devices. Fortran + OpenMP is a powerful, open, and standard approach to heterogeneous parallelism.

