Artificial intelligence (AI) has revolutionized virtually every industry from healthcare, retail, manufacturing, etc. However, most of today’s AI solutions are expensive and limited to a small set of data scientists. This is due to multiple factors. First, modern end-to-end AI pipelines are complex. They require multiple stages like data processing, feature engineering, model development, model deployment, and maintenance. The iterative nature of these stages makes the process time consuming. Second, deep expertise is often required to develop AI solutions. This creates an entry barrier for novice and citizen data scientists. Third, people tend to develop larger and deeper models to get better accuracy. These “over-parameterized” models lead to significant computational demands, which hinders deployment in resource-constrained environments.
We developed Intel® End-to-End AI Optimization Kit to make the end-to-end AI pipeline faster, simpler, and more accessible, broadening AI access to everyone, everywhere. It is a composable toolkit for end-to-end AI optimization to deliver high performance, lightweight models efficiently on commodity hardware. The toolkit is built on a set of Intel-optimized frameworks, such as Intel® Extension for PyTorch* (IPEX), Intel® Extension for TensorFlow* (ITEX), and Intel® AI Analytics Toolkit (AI Kit). It also integrates SigOpt for hyperparameter optimization. Intel End-to-End AI Optimization Kit also provides unique components and features for data preparation, model optimization, and model construction.
It improves the scale-up and scale-out efficiency of end-to-end AI pipelines to make "overnight training" for complex deep learning (DL) models possible. It delivers lighter DL models that have higher inference throughput lower resource requirements. It also makes end-to-end AI simpler. It automates the pipeline with click-to-run workflows and SigOpt AutoML, abstracts the complex APIs for data processing and feature engineering, simplifies distributed training, and can be easily integrated with existing or third-party machine learning (ML) solutions or platforms. It brings complex, compute-intensive deep learning models to commodity hardware, delivers built-in optimized models through parameterized models generated by smart democratization advisor (SDA), and domain-specific compact neural networks constructed with neural architecture search (NAS) technology. All of this makes AI more accessible to citizen data scientists.
Architecture
Popular models (e.g., RecSys, CV, NLP, ASR, and RL) from various domains are the input to Intel End-to-End AI Optimization Kit (Figure 1). These stock models are heavy, slow to train, and complex to tune and optimize. Depending on model type, Intel End-to-End AI Optimization Kit will optimize the models with either model advisor or neural network constructor. The expected outputs are optimized models that require only one-tenth the FLOPS (Floating-point Operations Per Second) and training time of the stock model with the same or minimal loss of accuracy.
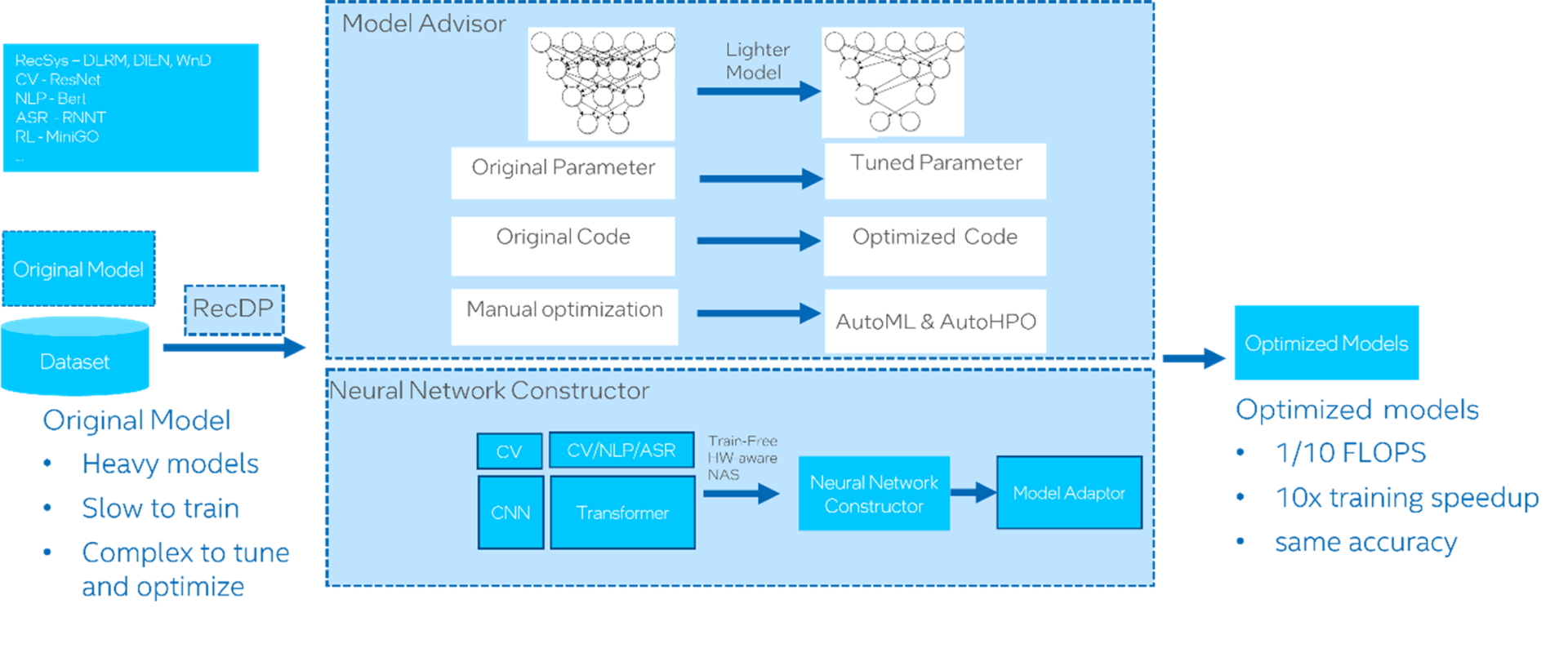
Figure 1. Architecture and workflow of Intel® End-to-End AI Optimization Kit
RecDP
RecDP is a parallel data processing and feature engineering library built on PySpark* and extensible to other data processing tools like Modin*. Its key features and functions are as follows:
- A tabular dataset processing toolkit
- Abstract APIs to hide Spark* programming complexity
- Optimized performance through adaptive query plan and strategy
- Support for common feature engineering functions like target and count encoding
- Easy integration into third-party solutions
RecDP uses "lazy execution" for better performance. It fuses operators and leverages the collection of data statistics to avoid unnecessary passes through the dataset, which is critical when handling large datasets. RecDP can also leverage the native columnar SQL engine capabilities provided by Optimized Analytics Package for Spark* platform to improve performance.
Smart Democratization Advisor (SDA)
SDA is a user-guided tool to facilitate automation. It provides built-in intelligence through parameterized models and leverages SigOpt for hyperparameter optimization (HPO) and built-in optimized models (e.g., RecSys, CV, NLP, ASR, and RL). It also converts manual model tuning and optimization to asssit AutoML and AutoHPO.
Neural Network Constructor
Neural network constructor is based on neural architecture search technology. Using a predefined supernet, it constructs neural network structures directly for a given domain. Its key features and functions are as follows:
- Multi-model support, such as models from the CV, NLP, and ASR domains
- Uses a unified, transformer-based SuperNet
- Hardware-aware NAS uses metrics like FLOPS and latency as thresholds to determine the model architecture and model size
- Train-free NAS uses a zero-cost proxy metric rather than training accuracy for candidate evaluation. It takes multiple network’s characteristics into consideration, such as trainability, expressivity, diversity, and saliency.
- Leverages model adapter to deploy the model in the user’s production environment. Model adapter is a transfer learning-based component that provides fine tuning, knowledge distillation, and domain adaption features.
Example
Here is an example of how the toolkit works on the DL Recommendation Model (DLRM), including environment setup, data processing, built-in model advisor with patched code, and a one-line command to kick off the entire optimization process.
Step 1: Environment Setup
Intel End-to-End AI Optimization Kit is built on top of AI Kit, so the software necessary to run the pipeline is already accessible:
# DockerFile
FROM docker.io/intel/oneapi-aikit
ENV http_proxy=http:
ENV https_proxy=http:
# SigOpt
RUN python -m pip install sigopt==7.5.0 --ignore-installed
# PyTorch conda
RUN conda activate pytorch
RUN python -m pip install prefetch_generator tensorboardX onnx tqdm lark-parser
# Intel Extension for PyTorch
RUN python -m pip install intel_extension_for_pytorch==1.10.0 -f https:
RUN mkdir -p /home/vmagent/app
WORKDIR /home/vmagent/app
Step 2: Parallel Data Processing with RecDP
The next step is to use RecDP for simplified data processing. In this example, two operators, Categorify() and FillNA(), are chained together and Spark lazy execution is used to reduce unnecessary passes through the data:
from pyspark.sql import *
from pyspark import *
from pyspark.sql.types import *
from pyrecdp.data_processor import *
from pyrecdp.encoder import *
from pyrecdp.utils import *
import numpy as np
path_prefix = "file://"
current_path = "/home/vmagent/app/dataset/demo/processed/"
csv_file = "/home/vmagent/app/dataset/demo/criteo_mini.txt"
# 1. Start spark and initialize data processor
t0 = timer()
spark = SparkSession.builder.master('local[*]') \
.config('spark.driver.memory','100G') \
.appName("DLRM").getOrCreate()
schema = StructType([StructField(f'_i{i}', IntegerType()) for i in range(0, 14)] )
df = spark.read.option('sep', '\t').option("mode", "DROPMALFORMED") \
.schema(schema).csv(path_prefix + csv_file)
proc = DataProcessor(spark, path_prefix, current_path=current_path, spark_mode='local')
# 2. Process data with RecDP
CAT_COLS = list(range(14, 40))
to_categorify_cols = ['_c%d' % i for i in CAT_COLS]
op_categorify = Categorify(to_categorify_cols)
op_fillna_for_categorified = FillNA(to_categorify_cols, 0)
proc.append_ops([op_categorify, op_fillna_for_categorified])
df = proc.transform(df, name='dlrm')
t1 = timer()
print(f"Total process time is {(t1 - t0)} secs")
Step 3: AutoML with Smart Democratization Advisor
SDA converts the manual optimizations to assist AutoML. It provides predefined parameters for built-in models, which significantly reduces the time for AutoML:
model_info = dict()
# Config for model
model_info["score_metrics"] = [("accuracy", "maximize"), ("training_time", "minimize")]
model_info["execute_cmd_base"] = "python launch.py"
model_info["result_file_name"] = "best_auc.txt"
# Config for SigOpt
model_info["experiment_name"] = "dlrm"
model_info["sigopt_config"] = [
{'name':'learning_rate','bounds':{'min':5,'max':50},'type':'int'},
{'name':'lamb_lr','bounds':{'min':5,'max':50},'type':'int'},
{'name':'warmup_steps','bounds':{'min':2000,'max':4500},'type':'int'},
{'name':'decay_start_steps','bounds':{'min':4501,'max':9000},'type':'int'},
{'name':'num_decay_steps','bounds':{'min':5000,'max':15000},'type':'int'},
{'name':'sparse_feature_size','grid': [128,64,16],'type':'int'},
{'name':'mlp_top_size','bounds':{'min':0,'max':7},'type':'int'},
{'name':'mlp_bot_size','bounds':{'min':0,'max':3},'type':'int'}]
model_info["observation_budget"] = 1
Besides some configurable parameters, there are cases that need code-level optimization. For all built-in modes, the kit provides optimized models with patched code. Here is an example using IPEX and BF16 as well as the optimizer to improve model convergence on multiple CPU nodes:
# Framework optimization. Use IPEX & BF16
# Embedding Optimization
- m_curr = (m[i] if self.max_emb_dim > 0 else m)
- EE = nn.EmbeddingBag(n, m_curr, mode="sum", sparse=True)
- W = np.random.uniform(
- low=-np.sqrt(1 / n), high=np.sqrt(1 / n), size=(n, m_curr)
- ).astype(np.float32)
# democratized, use two dimension, sparse and dense
+ W = np.random.uniform(
+ low=-np.sqrt(1 / n), high=np.sqrt(1 / n), size=(n, m)
+ ).astype(np.float32)
# Optimizer Optimization
- optimizer = torch.optim.SGD(dlrm.parameters(), lr=args.learning_rate) …)
Step 4: End-to-End Model Optimization
Finally, we kick off the end-to-end model optimization with just a few lines of codes:
import sys
from e2eAIOK import SDA
sda = SDA(model ="dlrm", settings=setting)
sda.launch()
Intel End-to-End AI Optimization Kit provides more click-to-run recipes for popular models, including:
- RecSys DLRM, DIEN, WnD
- Automatic speech recognition (ASR) RNNT
- Compute vision (CV) RESNET
- Natural language processing (NLP) BERT
- Reinforcement learning (RL) MiniGO
Performance
The tests were conducted on a four-node cluster (Table 1). Each node was equipped with two Intel® Xeon® Platinum 6240 processors and 384GB memory. The nodes were connected through 25GB Ethernet. One 1TB HDD SSD was used as a data drive.
| Configuration
| Details
|
| Test Date
| 12/2021
|
| Platform
| S2600WFT
|
| CPU
| Intel® Xeon® Gold 6240
|
| Number of Nodes
| 4
|
| CPU per node
| 18core/socket, 2 sockets, 2 threads/core
|
| Memory
| DDR4 dual rank 384G, 12 slots / 32GB / 2666
|
| Storage
| 1x 400GB Intel® SSD (SSDSC2BA400G3) OS Drive
1TB HDD for data storage
|
| Network
| 1x Intel® X722, 1x Intel XXV710
|
| Microcode
| 0x500002C
|
| BIOS version
| SE5C620.86B.0X.02.0094.102720191711
|
| OS/Hypervisor/SW
| Fedora* 29
5.3.11-100.fc29.x86_64
|
Table 1. System configuration
We compared the stock and optimized models’ performance on three popular RecSys models (Table 2). It delivered significant speedups for ETL, training, and inference for all three workloads (Figure 2).
| Workloads
| DLRM
| WnD
| DIEN
|
| Framework
| PyTorch*
| TensorFlow*
| TensorFlow
|
| Libraries
| oneMKL, oneCCL
| oneMKL, oneCCL
| oneMKL, oneCCL
|
| Dataset (size, shape)
| Criteo
| outbrain
| categoryFiles
|
| Precision (FP32, INT8., BF16)
| BF16
| -
| -
|
| KMP AFFINITY
| granularity=fine,compact,1,0
| granularity=fine,compact,1,0
| granularity=fine,compact,1,0
|
| NUMACTL
| Socket binding
| Socket binding
| Socket binding
|
| OMP_NUM_THREADS
| 20
| 16
| 4
|
Table 2. Test configuration
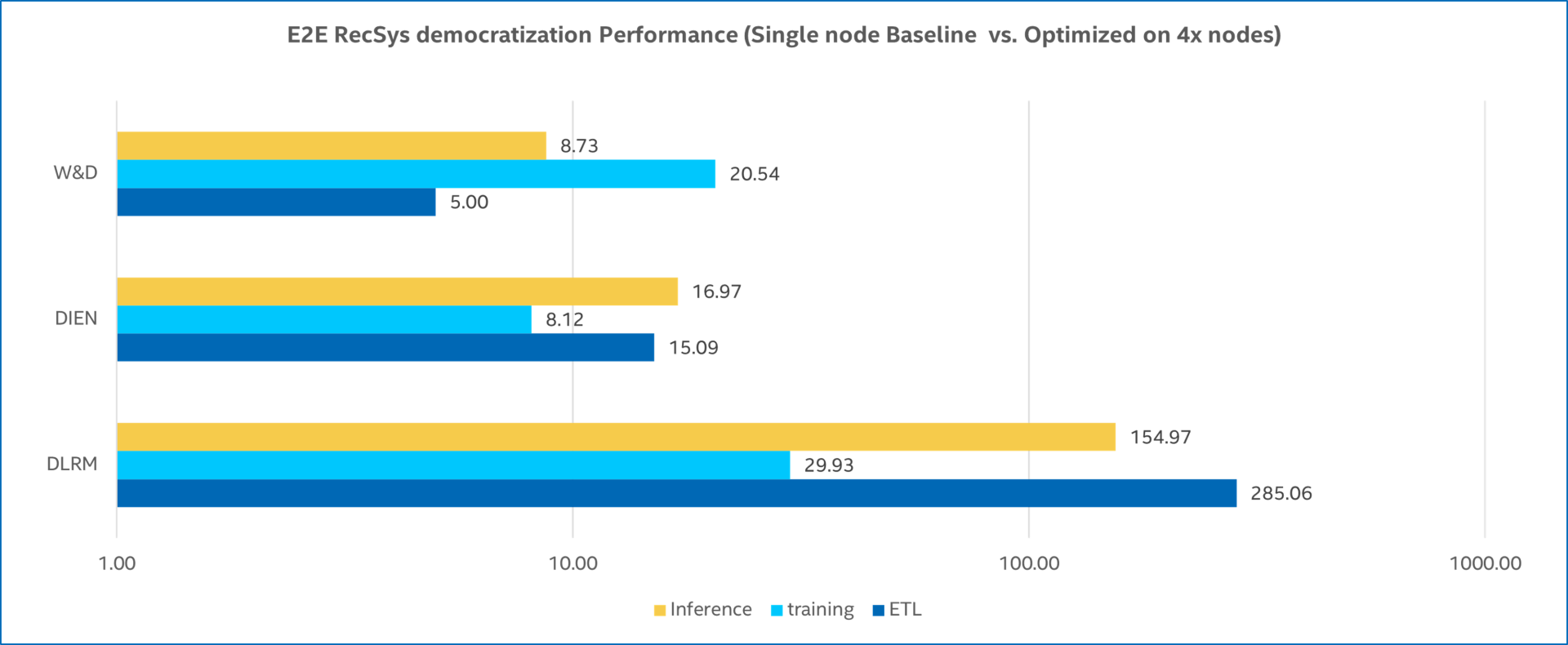
Figure 2. RecSYS speedup with Intel® End-to-End AI Optimization Kit. Baseline configuration: one node with two Intel® Xeon® Gold 6240 processors (18 cores), HT On, Turbo ON, 384 GB (12 slots/32GB/2666 MHz) memory, BIOS SE5C620.86B.0X.02.0094.102720191711 (ucode:0x500002C), Fedora 29, 5.3.11-100.fc29.x86_64, PyTorch*, TensorFlow*, Spark*. Optimized configuration: same hardware and software configuration except four nodes and Intel-optimized PyTorch and TensorFlow, Horovod*, and modified DLRM, WnD, and DIEN workloads.
Call to Action
Intel End-to-End AI Optimization Kit is a composable toolkit that delivers high performance and lightweight models for commodity hardware, which helps to democratize AI. It leverages several key optimizations:
- Parallel data processing with RecDP
- Intel-optimized training frameworks
- Lighter models with fewer layers and reduced communication overhead on distributed-memory parallel computers
- Optimizer tuning (DLRM) to converge faster with larger batch size
- Feature engineering (embedding table and encoding) optimizations
It gives good results on a wide range of popular models. If you want to use it for your own project, please visit https://github.com/intel/e2eAIOK/ to have a try.

