This tool usesTesseract to do the OCR (optical character recognition). The tool also uses Ghostscript to convert non-searchable PDFs to TIFF files that can be converted to searchable PDFs.
Introduction
This tool is using Tesseract to do the OCR (Optical Character Recognition). The tool is also using Ghostscript to convert non-searchable PDFs to TIFF files so that can be converted to searchable PDFs. The tool also provides an option to merge converted PDF files into one.
The tool is using iTextSharp library to see if the PDF is searchable or not. The following image files are supported: BMP, PNM, PNG, JFIF, JPEG, JPG, TIFF, TIF, GIF, PDF
- OCR PDF with text option will OCR PDF files regardless of whether they are already searchable or not
- Merge - option to merge converted PDF files into one searchable PDF
- Log Time - show time it takes to process each file
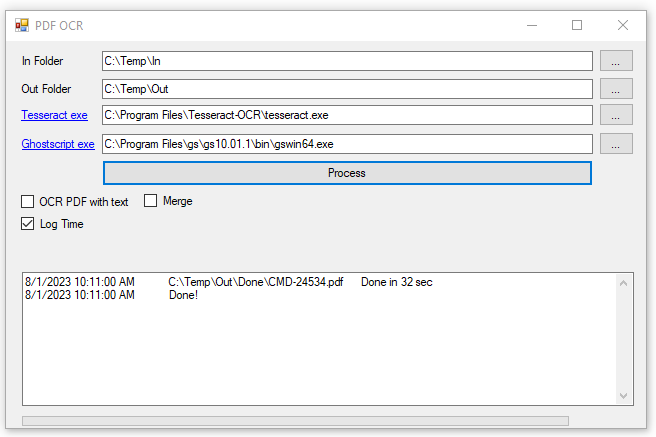
First, install Tesseract and Ghostscript. Next, select Tesseract.exe and GsWin64.exe locations in the tool. Finally, select input and output folders and click Process.
Using the Code
ProcessFile() is the key function that will OCR file and convert it based to PDF based on the file type. The key part of this function is RunDosCommandAsynch().
Private Sub ProcessFile(ByVal sFilePath As String, sFileName As String)
Dim dtStart As DateTime = DateTime.Now
Dim bTiff As Boolean = False
Dim sProcessFile As String = sFilePath
Dim sExt As String = GetExtFromFileName(sFileName)
If sExt = "pdf" Then
If chkOcrWithText.Checked = False AndAlso PdfHasText(sFilePath) Then
Log(sFilePath, "PDF already has text")
Dim sDoneFile As String = IO.Path.Combine(sFolderDone, sFileName)
CreateFolderIfDoesNotExist(sDoneFile)
IO.File.Move(sFilePath, sDoneFile)
Exit Sub
Else
bTiff = True
sProcessFile = System.IO.Path.Combine(System.IO.Path.GetTempPath(), _
Guid.NewGuid().ToString("N") & ".tiff")
PdfToTiff(sFilePath, sProcessFile)
If IO.File.Exists(sProcessFile) = False Then
Log(sFilePath, "TIFF file could not be generated")
sProcessFile = ""
End If
End If
End If
Dim sTempOutFile As String = System.IO.Path.Combine_
(System.IO.Path.GetTempPath(), Guid.NewGuid().ToString("N"))
Dim sTempOutFilePath As String = sTempOutFile & ".pdf"
Dim sError As String = ""
If sProcessFile <> "" Then
sError = RunDosCommandAsynch(sTesseractPath, """" & _
sProcessFile & """ """ & sTempOutFile & """ pdf")
End If
Dim bSuccess As Boolean = IO.File.Exists(sTempOutFilePath) _
AndAlso GetFileSize(sTempOutFilePath) > 10
If bSuccess AndAlso bTiff AndAlso PdfHasText(sTempOutFilePath) = _
False AndAlso PdfHasText(sFilePath) Then
Log(sFilePath, "Could not extract text from images. " & sError)
sTempOutFilePath = sFilePath
End If
If bSuccess Then
sFileName = GetBaseNameFromFileName(sFileName) & ".pdf"
Dim sDoneFile As String = IO.Path.Combine(sFolderDone, sFileName)
CreateFolderIfDoesNotExist(sDoneFile)
IO.File.Move(sTempOutFilePath, sDoneFile)
Dim iProcessSeconds As Integer = DateTime.Now.Subtract(dtStart).TotalSeconds
Log(sDoneFile, "Done in " & iProcessSeconds & " sec")
TryDelete(sFilePath)
Else
Dim sFailedFile As String = IO.Path.Combine(sFolderFailed, sFileName)
CreateFolderIfDoesNotExist(sFailedFile)
IO.File.Move(sFilePath, sFailedFile)
Log(sFailedFile, sError)
LogFile(sFailedFile, sError)
End If
If bTiff Then TryDelete(sProcessFile)
TryDelete(sTempOutFilePath)
End Sub
PdfToTiff uses ghost script to convert non-searchable PDF to TIFF. It is the secret to converting non-searchable PDFs to searchable PDFs.
Sub PdfToTiff(ByVal sInPdf As String, ByVal sOutTiff As String)
Dim sError As String = ""
RunDosCommand(sGhostscriptPath, "-dNOPAUSE -q -r300 -sDEVICE=tiff24nc _
-dBATCH -sOutputFile=""" & sOutTiff & """ """ & sInPdf & """ -c quit", sError)
End Sub
RunDosCommandAsynch does the action of running DOS command:
Function RunDosCommandAsynch(sExeFilePath As String, sArguments As String) As String
Dim sError As String = ""
Dim oProcess As Process = New Process()
oProcess.StartInfo.UseShellExecute = False
oProcess.StartInfo.RedirectStandardOutput = True
oProcess.StartInfo.RedirectStandardError = True
oProcess.StartInfo.FileName = sExeFilePath
oProcess.StartInfo.Arguments = sArguments
oProcess.StartInfo.WindowStyle = ProcessWindowStyle.Hidden
oProcess.StartInfo.CreateNoWindow = True
oProcess.Start()
oProcess.WaitForExit(1000 * iTimeOutSec)
If oProcess.HasExited = False Then
oProcess.Kill()
sError = "Timeout after " + iTimeOutSec + " seconds."
End If
If String.IsNullOrEmpty(sError) Then
sError = oProcess.StandardError.ReadToEnd()
End If
If oProcess.ExitCode <> 0 AndAlso String.IsNullOrEmpty(sError) Then
sError = "ExitCode: " + oProcess.ExitCode
End If
oProcess.Close()
Return sError
End Function
PdfHasText() function uses iTextSharp library to see if the PDF is searchable or not.
Function PdfHasText(ByVal sInPdf As String) As Boolean
Dim doc As New PdfReader(sInPdf)
Dim bRet As Boolean = False
For iPage = 1 To doc.NumberOfPages
Dim pg As PdfDictionary = doc.GetPageN(iPage)
Dim ir As Object = pg.Get(PdfName.CONTENTS)
Dim value As PdfObject = doc.GetPdfObject(ir.Number)
If value.IsStream() Then
Dim stream As PRStream = value
Dim streamBytes As Byte() = PdfReader.GetStreamBytes(stream)
Dim tokenizer = New PRTokeniser(New RandomAccessFileOrArray(streamBytes))
Try
While tokenizer.NextToken()
If tokenizer.TokenType = PRTokeniser.TK_STRING Then
Dim str As String = tokenizer.StringValue
If str <> "" Then
bRet = True
Exit While
End If
End If
End While
Catch ex As Exception
Finally
tokenizer.Close()
End Try
If bRet Then
Exit For
End If
End If
Next
doc.Close()
Return bRet
End Function
Merge() function uses iTextSharp library to merge PDF files.
Sub Merge(ByVal sInSubFolder As String)
Dim sSubFolderDone As String = GetTargetSubFolder(sFolderDone, sInSubFolder)
If IO.Directory.Exists(sSubFolderDone) = False Then
Exit Sub
End If
Dim oOutFiles As String() = IO.Directory.GetFiles(sSubFolderDone)
If oOutFiles.Length = 0 Then
Exit Sub
End If
Dim sMergeOutFilePath As String = GetMergeOutFilePath(sSubFolderDone)
Dim oDeleteFiles As New ArrayList()
Dim oPdfDoc As New iTextSharp.text.Document()
Dim oPdfWriter As PdfWriter = PdfWriter.GetInstance_
(oPdfDoc, New FileStream(sMergeOutFilePath, FileMode.Create))
oPdfDoc.Open()
System.Array.Sort(Of String)(oOutFiles)
For i As Integer = 0 To oOutFiles.Length - 1
Dim sFromFilePath As String = oOutFiles(i)
Dim oFileInfo As New FileInfo(sFromFilePath)
Dim sBookmarkTitle As String = GetBaseNameFromFileName(oFileInfo.Name)
AddPdf(sFromFilePath, oPdfDoc, oPdfWriter, sBookmarkTitle)
oDeleteFiles.Add(sFromFilePath)
Next
Try
oPdfDoc.Close()
oPdfWriter.Close()
Catch ex As Exception
Log(ex.Message)
End Try
If chkDeleteSourceFiles.Checked Then
For Each sFromFilePath As String In oDeleteFiles
If IO.File.Exists(sFromFilePath) Then
Try
IO.File.Delete(sFromFilePath)
Catch ex As Exception
Log(sFromFilePath, "Could not delete, " & ex.Message)
End Try
End If
Next
End If
End Sub
Sub AddPdf(ByVal sInFilePath As String, ByRef oPdfDoc As iTextSharp.text.Document, _
ByRef oPdfWriter As PdfWriter, ByVal sBookmarkTitle As String)
AddBookmark(oPdfDoc, sBookmarkTitle)
Dim oDirectContent As iTextSharp.text.pdf.PdfContentByte = _
oPdfWriter.DirectContent
Dim oPdfReader As iTextSharp.text.pdf.PdfReader = _
New iTextSharp.text.pdf.PdfReader(sInFilePath)
Dim iNumberOfPages As Integer = oPdfReader.NumberOfPages
Dim iPage As Integer = 0
Do While (iPage < iNumberOfPages)
iPage += 1
Dim iRotation As Integer = oPdfReader.GetPageRotation(iPage)
Dim oPdfImportedPage As iTextSharp.text.pdf.PdfImportedPage = _
oPdfWriter.GetImportedPage(oPdfReader, iPage)
If chkResize.Checked Then
If (oPdfImportedPage.Width <= oPdfImportedPage.Height) Then
oPdfDoc.SetPageSize(iTextSharp.text.PageSize.LETTER)
Else
oPdfDoc.SetPageSize(iTextSharp.text.PageSize.LETTER.Rotate())
End If
oPdfDoc.NewPage()
Dim iWidthFactor As Single = _
oPdfDoc.PageSize.Width / oPdfReader.GetPageSize(iPage).Width
Dim iHeightFactor As Single = _
oPdfDoc.PageSize.Height / oPdfReader.GetPageSize(iPage).Height
Dim iFactor As Single = Math.Min(iWidthFactor, iHeightFactor)
Dim iOffsetX As Single = (oPdfDoc.PageSize.Width - _
(oPdfImportedPage.Width * iFactor)) / 2
Dim iOffsetY As Single = (oPdfDoc.PageSize.Height - _
(oPdfImportedPage.Height * iFactor)) / 2
oDirectContent.AddTemplate(oPdfImportedPage, iFactor, _
0, 0, iFactor, iOffsetX, iOffsetY)
Else
oPdfDoc.SetPageSize(oPdfReader.GetPageSizeWithRotation(iPage))
oPdfDoc.NewPage()
If (iRotation = 90) Or (iRotation = 270) Then
oDirectContent.AddTemplate(oPdfImportedPage, 0, -1.0F, _
1.0F, 0, 0, oPdfReader.GetPageSizeWithRotation(iPage).Height)
Else
oDirectContent.AddTemplate(oPdfImportedPage, 1.0F, 0, 0, 1.0F, 0, 0)
End If
End If
Loop
End Sub
Bonus VBS (For Processing PDF Files in Parallel)
As a bonus, I included a PdfOcr.vbs VB Script file that will convert a folder or a file to searchable PDF if you drag-and-drop folder or file on it. The advantage of using the approach is that you can process many PDF/image files in parallel. This way, only files that do not have corresponding searchable PDF will be processed. You should be able to run this on one server or on many servers running against same folder or file share.
Make sure that Tesseract and Ghostscript are installed. Next, make sure that sGhostscriptPath (line 7) and sTesseractPath (Line 8) point to location of Tesseract.exe and GsWin64.exe files.
OcrImgFile sub does processing of the image files to searchable PDFs.
Sub OcrImgFile(sInFile)
iPos = InStrRev(sInFile,".")
sFileBase = Mid(sInFile,1,iPos - 1)
sOutPdf = sFileBase & sFileSuffix
If fso.FileExists(sOutPdf & ".pdf") Then
Msg sOutPdf & ".pdf already exists"
Exit Sub
End If
oShell.run """" & sTesseractPath & """ """ & sInFile & """ """ & sOutPdf & """ pdf", 1 , True
If fso.FileExists(sOutPdf & ".pdf") Then
iCount = iCount + 1
Else
Msg sOutPdf & ".pdf could not be created"
End If
End Sub
OcrPdfFile sub converts non-searchable PDFs to searchable PDFs.
Sub OcrPdfFile(sInPdf)
If Right(sInPdf, Len(sFileSuffix) + 4) = sFileSuffix & ".pdf" Then
Msg sInPdf & " in an output file and will not be processed"
Exit Sub
End If
iPos = InStrRev(sInPdf,".")
sFileBase = Mid(sInPdf,1,iPos - 1)
sOutPdf = sFileBase & sFileSuffix
If fso.FileExists(sOutPdf & ".pdf") Then
Msg sOutPdf & ".pdf already exists"
Exit Sub
End If
sOutTiff = sFileBase & sFileSuffix & ".tiff"
oShell.run """" & sGhostscriptPath & """ -dNOPAUSE -q -r300 -sDEVICE=tiff24nc _
-dBATCH -sOutputFile=""" & sOutTiff & """ """ & sInPdf & """ -c quit", 1 , True
If fso.FileExists(sOutTiff) Then
oShell.run """" & sTesseractPath & """ """ & sOutTiff & """ """ & _
sOutPdf & """ pdf", 1 , True
fso.DeleteFile sOutTiff
If fso.FileExists(sOutPdf & ".pdf") Then
iCount = iCount + 1
Else
Msg sOutPdf & ".pdf could not be created"
End If
Else
Msg sOutTiff & " could not be created"
End If
End Sub
History
- 2nd August, 2023: Version 1

