Many machine learning applications must ensure the confidentiality and integrity of the underlying code and data. Until recently, security has primarily focused on encrypting data that is at rest (i.e., in storage) or in transit (i.e., being transmitted across a network), but not on data that is in use (i.e., in main memory). Intel® Software Guard Extensions (Intel® SGX) provide a set of instructions that allow you to securely process and preserve the application code and data. Intel SGX does this by creating a trusted execution environment within the CPU. This allows user-level code from containers to allocate private regions of memory, called enclaves, to execute the application code.
With the Microsoft Azure* confidential computing platform, you can deploy both Windows* and Linux virtual machines (VMs), leveraging the security and confidentiality provided by Intel SGX. This tutorial will show you how to set up Intel SGX nodes on an Azure Kubernetes* Services (AKS) cluster. We will then install Kubeflow*, the machine learning toolkit for Kubernetes that you can use to build and deploy scalable machine learning pipelines. Finally, we will demonstrate how to accelerate model training and inference using the Intel® Optimization for XGBoost*, Intel® oneAPI Data Analytics Library (oneDAL), and Intel® Extension for Scikit-learn*.
This optimization module is a part of the Intel® Cloud Optimization Modules for Microsoft Azure, a set of cloud-native, open-source reference architectures that are designed to facilitate building and deploying Intel-optimized AI solutions on leading cloud providers, including Amazon Web Services* (AWS), Microsoft Azure, and Google Cloud Platform* (GCP). Each module, or reference architecture, includes all necessary instructions and source code.
The cloud solution architecture for this optimization module uses an AKS cluster, with the central components being Intel SGX VMs. An Azure Container Registry is attached to the AKS cluster so that the Kubeflow pipeline can build the containerized Python* components. These Azure resources are managed in an Azure Resource Group. The Kubeflow software layer is then installed on the AKS cluster. When the Kubeflow pipeline is run, each pipeline pod will be assigned to an Intel SGX node. The cloud solution architecture is shown in Figure 1.
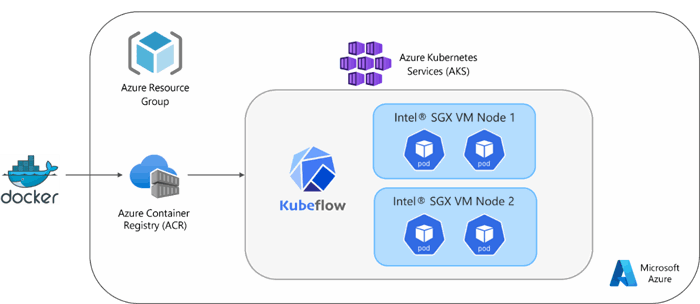
Figure 1. Kubeflow* pipeline architecture diagram (image from author)
Preliminaries
Before starting this tutorial, ensure that you have downloaded and installed the prerequisites. Then, in a new terminal window, run the command below to log in to your Microsoft Azure account interactively with the Azure command-line interface.
az login
Next, create a resource group that will hold the Azure resources for our solution. We will call our resource group intel-aks-kubeflow and set the location to eastus.
# Set the names of the Resource Group and Location
export RG=intel-aks-kubeflow
export LOC=eastus
# Create the Azure Resource Group
az group create -n $RG -l $LOC
To set up the AKS cluster with confidential computing nodes, we will first create a system node pool and enable the confidential computing add-on. The confidential computing add-on will configure a DaemonSet for the cluster that will ensure each eligible VM node runs a copy of the Azure device plugin pod for Intel SGX. The command below will provision a node pool using a standard VM from the Dv5 series, which is a 3rd Generation Intel® Xeon® processor. This is the node that will host the AKS system pods, like CoreDNS and metrics-server. The following command will also enable managed identity for the cluster and provision a standard Azure Load Balancer.
# Set the name of the AKS cluster
export AKS=aks-intel-sgx-kubeflow
# Create the AKS system node pool
az aks create --name $AKS \
--resource-group $RG \
--node-count 1 \
--node-vm-size Standard_D4_v5 \
--enable-addons confcom \
--enable-managed-identity \
--generate-ssh-keys -l $LOC \
--load-balancer-sku standard
Note that if you have already set up an Azure Container Registry, you can attach it to the cluster by adding the parameter --attach-acr <registry-name>.
Once the system node pool has been deployed, we will add the Intel SGX node pool to the cluster. The following command will provision two, four-core Intel SGX nodes from the Azure DCSv3 series. We have added a node label to this node pool with the key intelvm and the value sgx. This key/value pair will be referenced in the Kubernetes nodeSelector to assign the Kubeflow pipeline pods to an Intel SGX node.
az aks nodepool add --name intelsgx \
--resource-group $RG \
--cluster-name $AKS \
--node-vm-size Standard_DC4s_v3 \
--node-count 2 \
--labels intelvm=sgx
Once the confidential node pool has been set up, obtain the cluster access credentials and merge them into your local .kube/config file using the following command:
az aks get-credentials -n $AKS -g $RG
We can verify that the cluster credentials were set correctly by executing the command below. This should return the name of your AKS cluster.
kubectl config current-context
To ensure that the Intel SGX VM nodes were created successfully, run:
kubectl get nodes
You should see two agent nodes running beginning with the name aks-intelsgx. To ensure that the DaemonSet was created successfully, run:
kubectl get pods -A
In the kube-system namespace, you should see two pods running that begin with the name sgxplugin. If you see the above pods and node pool running, this means that your AKS cluster is now ready to run confidential applications, and we can begin installing Kubeflow.
Install Kubeflow
To install Kubeflow on an AKS cluster, first clone the Kubeflow Manifests GitHub repository.
git clone https://github.com/kubeflow/manifests.git
Change the directory to the newly cloned manifests directory.
cd manifests
As an optional step, you can change the default password to access the Kubeflow dashboard using the command below:
python3 -c 'from passlib.hash import bcrypt; import getpass; print(bcrypt.using(rounds=12, ident="2y").hash(getpass.getpass()))'
Navigate to the config-map.yaml in the dex directory and paste the newly generated password in the hash value of the configuration file at around line 22.
nano common/dex/base/config-map.yaml
staticPasswords:
- email: user@example.com
hash:
Next, change the Istio* ingress gateway from a ClusterIP to a LoadBalancer. This will configure an external IP address that we can use to access the dashboard from our browser. Navigate to common/istio-1-16/istio-install/base/patches/service.yaml and change the specification type to LoadBalancer at around line 7.
apiVersion: v1
kind: Service
metadata:
name: istio-ingressgateway
namespace: istio-system
spec:
type: LoadBalancer
For AKS clusters, we also need to disable the AKS admission enforcer from the Istio webhook. Navigate to the Istio install.yaml and add the following annotation at around line 2694.
nano common/istio-1-16/istio-install/base/install.yaml
apiVersion: admissionregistration.k8s.io/v1
kind: MutatingWebhookConfiguration
metadata:
name: istio-sidecar-injector
annotations:
admissions.enforcer/disabled: 'true'
labels:
Next, we will update the Istio Gateway to configure the Transport Layer Security (TLS) protocol. This will allow us to access the dashboard over HTTPS. Navigate to the kf-istio-resources.yaml and at the end of the file, at around line 14, paste the following contents:
nano common/istio-1-16/kubeflow-istio-resources/base/kf-istio-resources.yaml
tls:
httpsRedirect: true
- port:
number: 443
name: https
protocol: HTTPS
hosts:
- "*"
tls:
mode: SIMPLE
privateKey: /etc/istio/ingressgateway-certs/tls.key
serverCertificate: /etc/istio/ingressgateway-certs/tls.crt
Now we are ready to install Kubeflow. We will use kustomize to install the components with a single command. You can also install the components individually.
while ! kustomize build example | awk '!/well-defined/' | kubectl apply -f -; do echo "Retrying to apply resources"; sleep 10; done
It may take several minutes for all components to be installed, and some may fail on the first try. This is inherent to how Kubernetes and kubectl work (e.g., CR must be created after CRD becomes ready). The solution is to simply rerun the command until it succeeds. Once the components have been installed, verify that all the pods are running by using:
kubectl get pods -A
Optional: If you created a new password for Kubeflow, restart the dex pod to ensure it is using the updated password.
kubectl rollout restart deployment dex -n auth
Finally, create a self-signed certificate for the TLS protocol using the external IP address from the Istio load balancer. To get the external IP address, use the following command:
kubectl get svc -n istio-system
Create the Istio certificate and copy the contents below:
nano certificate.yaml
apiVersion: cert-manager.io/v1
kind: Certificate
metadata:
name: istio-ingressgateway-certs
namespace: istio-system
spec:
secretName: istio-ingressgateway-certs
ipAddresses:
- <Istio IP address>
isCA: true
issuerRef:
name: kubeflow-self-signing-issuer
kind: ClusterIssuer
group: cert-manager.io
Then, apply the certificate:
kubectl apply -f certificate.yaml
Verify that the certificate was created successfully:
kubectl get certificate -n istio-system
Now, we are ready to launch the Kubeflow dashboard. To log in to the dashboard, type the Istio IP address into your browser. When you first access the dashboard, you may get a warning. This is because we are using a self-signed certificate. You can replace this with an SSL CA certificate if you have one, or click on Advanced and Proceed to the website. The DEX login screen should appear. Enter your username and password. The default username for Kubeflow is user@example.com and the default password is 12341234.
After logging into the Kubeflow dashboard, we are now ready to deploy the Kubeflow pipeline. The Kubeflow pipeline in this module was derived from the Loan Default Risk Prediction AI Reference Kit, built by Intel in collaboration with Accenture. The code has been enhanced through refactoring to achieve better modularity and suitability for Kubeflow Pipelines. The pipeline builds an XGBoost model to predict a borrower’s loan default risk and uses Intel Optimization for XGBoost and oneDAL to accelerate model training and inference. A graph of the full pipeline is shown in Figure 2.

Figure 2. XGBoost* Kubeflow* pipeline graph (image by author)
The Kubeflow pipeline consists of the following seven components:
- Load data: Load the dataset (credit_risk_dataset.csv) from the URL specified in the pipeline run parameters and perform synthetic data augmentation. Download the Kaggle Credit Risk dataset.
- Create training and test sets: Split the data into training and test sets of an approximately 75:25 split for model evaluation.
- Preprocess features: Transform the categorical features of the training and test sets by using one-hot encoding, in addition to imputing missing values and power-transforming numerical features.
- Train XGBoost model: This component trains the model, taking advantage of the accelerations provided by the Intel Optimization for XGBoost.
- Convert XGBoost model to daal4py: Convert the XGBoost model to an inference-optimized daal4py classifier.
- daal4py inference: Compute predictions using the inference-optimized daal4py classifier and evaluate model performance. It returns an output summary of the precision, recall, and F1 score for each class, as well as the area under the curve (AUC) and accuracy score of the model.
- Plot receiver operating characteristic (ROC) curve: Perform model validation on the test data and generate a plot of the ROC curve.
The code for the pipeline can be found in the src folder of the GitHub repo called intel-xgboost-daal4py-pipeline-azure.py. Before running the Python script, ensure that you have installed version 2.0 or above of the Kubeflow Pipelines SDK. To update your SDK version, you can use:
pip install -U kfp
To ensure that each pipeline pod is assigned to an Intel SGX node, a Kubernetes nodeSelector has been added to the pipeline. The node selector will look for a node with a matching label key/value pair when scheduling the pods. Using the node label we added to the Intel SGX node pool, the code below will assign the data preprocessing pipeline task, preprocess_features_op, to an Intel SGX node.
from kfp import kubernetes
kubernetes.add_node_selector(task = preprocess_features_op,
label_key = 'intelvm', label_value = 'sgx')
Pipeline Components
The first component in the pipeline, load_data, downloads the credit risk dataset from the URL provided in the pipeline run parameters and synthetically augments the data to the size specified. The new dataset is saved as an output artifact in the Kubeflow MinIO volume. This dataset is then read into the next step of the component, create_train_test_set, which partitions the data into an approximately 75:25 split for model evaluation. The training and testing sets, X_train, y_train, X_test, and y_test, are then saved as output dataset artifacts.
In the preprocess_features component, a data preprocessing pipeline is created to prepare the data for the XGBoost model. This component loads the X_train and X_test files from the MinIO storage and transforms the categorical features using one-hot encoding, imputes missing values, and power-transforms the numerical features.
The next component trains the XGBoost model. Using XGBoost on Intel CPUs takes advantage of software accelerations powered by oneAPI without requiring any code changes. In the initial testing of incremental training updates of size one million, Intel Optimization for XGBoost v1.4.2 offers up to 1.54x speedup over stock XGBoost v0.81. (You can view all performance results of the Loan Default Risk Prediction Reference Kit on GitHub.) The following code snippet is implemented in the train_xgboost_model component:
# Create the XGBoost DMatrix, which is optimized for memory efficiency and training speed
dtrain = xgb.DMatrix(X_train.values, y_train.values)
# Define model parameters
params = {"objective": "binary:logistic",
"eval_metric": "logloss",
"nthread": 4, # num_cpu
"tree_method": "hist",
"learning_rate": 0.02,
"max_depth": 10,
"min_child_weight": 6,
"n_jobs": 4, # num_cpu
"verbosity": 1}
# Train initial XGBoost model
clf = xgb.train(params = params, dtrain = dtrain, num_boost_round = 500)
To further optimize the model prediction speed, we convert the trained XGBoost model into an inference-optimized daal4py classifier in the convert_xgboost_to_daal4py component. daal4py is the Python API of oneDAL. In testing batch inference of size one million, oneDAL provided a speedup of up to 4.44x. You can convert the XGBoost model to daal4py with one line of code:
daal_model = d4p.get_gbt_model_from_xgboost(clf)
Then, use the daal4py model to evaluate the model’s performance on the test set in the daal4py_inference component.
daal_prediction = d4p.gbt_classification_prediction(
nClasses = 2,
resultsToEvaluate = "computeClassLabels|computeClassProbabilities"
).compute(X_test, daal_model)
We compute both the binary class labels and probabilities by calling the gbt_classification_prediction method in the code above. You can also calculate the log probabilities with this function. This component will return the classification report in CSV format, as well as two Kubeflow metrics artifacts: the area under the curve and the accuracy of the model. These can be viewed in the Visualization tab of the metrics artifact.
In the last component of the pipeline, plot_roc_curve, we load the prediction data with the probabilities and the true class labels to calculate the ROC curve using the CPU-accelerated version from the Intel Extension for Scikit-Learn. When the pipeline is finished running, the results are stored as a Kubeflow ClassificationMetric Artifact, which can be viewed in the Visualization tab of the roc_curve_daal4py artifact (Figure 3).
Figure 3. ROC curve of the classifier
Next Steps
You can access the full source code on GitHub. Register for office hours if you need help with your implementation. You can learn more at Intel Cloud Optimization Modules and chat with us on the Intel® DevHub Discord server to keep interacting with fellow developers.

