Large language models (LLMs) have been attracting a lot of attention lately because of their extraordinary performance on dialog agents such as ChatGPT*, GPT-4*, and Bard*. However, LLMs are limited by the significant cost and time required to train or fine-tune them. This is due to their large model sizes and data sets.
In this article, we will demonstrate how to easily train and fine-tune a custom chatbot on readily available hardware. We use 4th Generation Intel® Xeon® Scalable processors to create our chatbot using a systematic methodology to generate a domain-specific dataset and an optimized fine-tuning code base.
Our Approach
Stanford Alpaca is an instruction-following language model that is fine-tuned from Meta’s LLaMA model. Inspired by this project, we developed an enhanced methodology to create a custom, domain-specific chatbot. While there are several language models that one could use (including some with better performance), we selected Alpaca because it is an open model.
The workflow of the chatbot consists of four main steps: guided seed generation, free (non-guided) seed generation, sample generation, and fine-tuning (Figure 1).
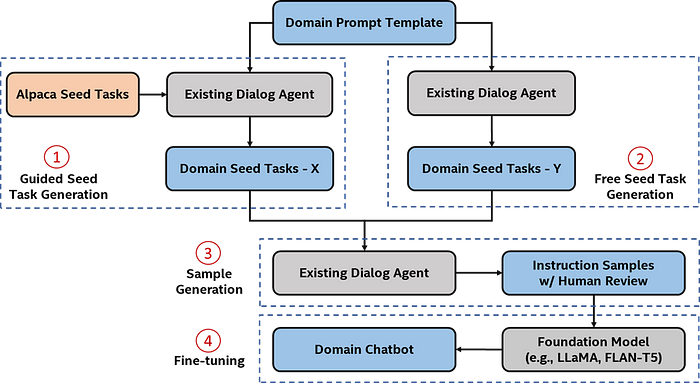
Figure 1. Overview of chatbot fine-tuning
Before walking you through these steps, we’d like to introduce a prompt template that is useful in seed task generation. The sample prompt from Alpaca for general tasks is shown in Figure 2.

Figure 2. Prompt template for seed task generation
We modified the template by adding a new requirement; i.e.: “The generated task instructions should be related to <domain_name> issues.” This helps generate seed tasks related to the specified domain. To generate more diverse seed tasks, we use both guided and free (non-guided) seed task generation.
Guided seed task generation leverages the existing seed tasks from Alpaca. For each seed task, we combine the content from the domain prompt template and feed it into the existing dialog agent. We expect to generate the corresponding number of tasks (e.g., 20 defined in the prompt template in Figure 2). Such text generation is one of the typical use-cases for causal language models.
Non-guided seed task generation feeds the domain prompt template to the dialog agent directly without specifying additional seed tasks. We refer to non-guided seed task generation as “free.” We generate new domain seed tasks using this approach (Figure 3).
Figure 3. Domain seed task
With these seed tasks, we again leverage the existing dialog agent to generate the instruction samples. As the domain prompt template is used, the output follows the requirements with the format “instruction,” “input,” and “output.” We repeat the process and generate 2,000 instruction samples for fine-tuning (Figure 4).
Figure 4. Domain instruction sample
You may have noticed the similarity between a domain seed task and an instruction sample. You can think of them as being a ChatGPT prompt and the resulting output respectively with one influencing the other.
Training Your Custom Chatbot
We use the Low-Rank Adaptation (LoRA) approach to fine-tune the LLM efficiently, rather than fine-tuning the entire LLM with billions of parameters. LoRA freezes the pretrained model weights and injects trainable rank decomposition matrices into each layer of the transformer architecture, greatly reducing the number of trainable parameters for downstream tasks.
Besides the parameter-efficient fine-tuning, we can leverage hardware and software acceleration to speed up the fine-tuning process. An example of hardware acceleration is Intel® Advanced Matrix Extensions (Intel® AMX-BF16) instructions, available on 4th Generation Intel Xeon Scalable processors, that are specifically designed to accelerate AI performance. The software optimizations included in PyTorch*, Intel® Extension for PyTorch* and Hugging Face* transformers also help accelerate performance compared to unoptimized versions of these frameworks and libraries.
We can also enable instruction sample concatenation to further improve the fine-tuning process. The basic idea is that several tokenized sentences are concatenated into a longer and concentrated sentence as the training sample instead of having several training samples with different lengths. This helps maximize the underlying hardware efficiency.
All the above optimizations are on a single compute node. You can also perform multinode fine-tuning with distributed data parallelism during the fine-tuning process to harness more computing power.
Now, let’s start training a domain chatbot:
Results
We tested the fine-tuning on two popular LLMs (LLaMA-7B and FLAN-T5 XL) using 52,000 general instruction samples from Alpaca and our generated 2,000 domain instruction samples. Using the previously described software optimization techniques, we observe up to 25x speedup on 4th Generation Intel Xeon Scalable processors (Figure 6).
Figure 6. Chatbot fine-tuning speedup
We measured the knowledge acquired by the model during pretraining using the new Massive Multitask Language Understanding (MMLU) benchmark, which evaluates models exclusively in zero-shot and few-shot settings. You can see from Table 1 that our chatbot shows better results on average and for most of the domain subtasks. Our MMLU results are comparable with GPT-3* (175B), yet 25x more efficient in parameter size. We encourage you to also try this build using other open language models while taking advantage of Intel® hardware acceleration and software optimizations.
Table 1. MMLU benchmarks
In addition to the MMLU benchmark, we also did qualitative conversation evaluation, e.g.:
- Input prompt: Where to find the product information about Intel microchip?
- Response from Alpaca: You can find product information about Intel microchips on their website, Intel.com. There you will find information about their processors, graphics cards, motherboards, and other products. You can also find product specifications, tutorials, and other resources.
- Response from our chatbot: You can find the product information about Intel microchips on their website, https://www.intel.com/content/www/us/en/support/processors/top-questions.html.
Summary
We released the source code and domain-specific dataset in Intel Extension for Transformers. We encourage you to create your own chatbot on Intel® CPUs and explore other Intel® AI tools and optimizations as part of your AI workflows.
Our next step is to enable quantization and compression techniques to accelerate chatbot inference on Intel platforms. Please add a star to Intel Extension for Transformers if you would like to receive notifications about our latest optimizations, and feel free to contact us if you have any questions.

