If you need to TRANslate a FORmula into code, FORTRAN, is a great option, and has been for the past 66 years. We could argue that it’s the original domain-specific language for mathematics, but we’ll save that discussion for another time. The purpose of this article is not to extol the many virtues of Fortran, but rather to assess its strengths and weaknesses for heterogeneous parallelism.
Standard-based programming languages give us a common dialect to express algorithms. However, their support for specialized hardware tends to lag, as we saw in The Case for SYCL: Why ISO C++ Is Not Enough for Heterogeneous Computing. Let’s see how well ISO Fortran supports heterogeneous computing, perhaps adding something to the debate prompted by Los Alamos National Laboratory’s recent report: An Evaluation of the Risks Associated with Relying on Fortran for Mission Critical Codes for the Next 15 Years.
The DO CONCURRENT construct was introduced in ISO Fortran 2008 and has been enhanced in more recent ISO standards. It informs, or asserts to, the compiler that the iterations of the DO CONCURRENT loop are independent and can be executed in parallel. The Intel® Fortran Compiler supports DO CONCURRENT. A DO CONCURRENT loop can be executed sequentially, in parallel, and can even use the OpenMP* backend to offload DO CONCURRENT loops to accelerators.
We’ll use a simple image segmentation algorithm to demonstrate this capability. The algorithm detects the edges of objects in an image (Figure 1). This high-pass filter is the first step in many computer vision processes because the edges contain most of the information in an image. The illustration in Figure 1 shows a binary image containing three objects, represented by groups of ones. The edge mask is a Boolean matrix where true means the corresponding “pixel” is on the edge of an object.
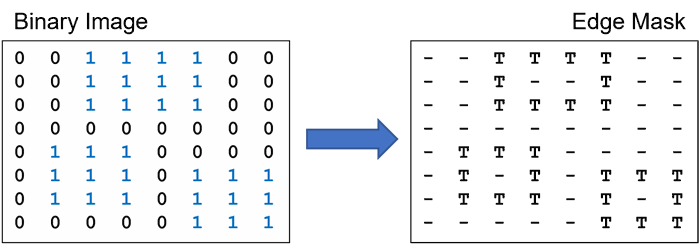
Figure 1. Edge detection in a simple binary image
Fortran provides a convenient array notation and intrinsic procedures to easily code edge detection (Figure 2). We can implement this algorithm by applying a 9-point binary filter to each pixel. The filter is only applied to pixels that are part of an object because of the predicate on the DO CONCURRENT loop. The operation on each pixel is independent, so the algorithm is highly data parallel and easily implemented with a Fortran DO CONCURRENT loop and a few lines of code.
integer, allocatable :: 1mage(:,:)
logical, allocatable :: edge_mask(:,:)
allocate (image(n, n), source = 0, stat = allocstat, errmsg = allocmsg)
allocate (edge_mask(n, n), source = .false., stat = allocstat, errmsg = allocmsg)
do concurrent (j = 1:n, i = 1:n, image(i, j) /= 0)
if (i == 1 .or. i == n .or. &
j == 1 .or. j == n) then
edge_mask(i, J) = .true.
else
if (any(image(i-1:i+1, j-1:j+1) == 0)) edge_mask(i, j) = .true.
endif
enddo
Figure 2. Edge detection implemented using a Fortran DO CONCURRENT loop (highlighted in blue). The offload kernel is highlighted in green. The complete code is available at
img_seg_do_concurrent.F90.
The DO CONCURRENT construct is just another form of the DO construct. Even if this is your first time seeing DO CONCURRENT, it should be clear to most Fortran programmers that this example loops over the i and j indices like a familiar doubly nested DO loop. What is perhaps new with the DO CONCURRENT construct is the optional predicate. This is a scalar mask expression of type LOGICAL. If a predicate appears, only those iterations where the mask expression is TRUE are executed. The DO CONCURRENT code above is functionally equivalent to the following DO and IF implementation:
do i = 1, n
if (image(i, j) /= 0) then
endif
enddo
enddo
The major difference is that DO CONCURRENT asserts to the compiler that there are no dependencies, so the iterations can be executed in any order.
The Intel Fortran Compiler can parallelize and/or offload statements in a DO CONCURRENT loop using the OpenMP backend. This is evident in the commands to compile the example code:

The first executable (img_seg_do_conc_cpu) will run the DO CONCURRENT loop in parallel on all the available host processors. The second executable (img_seg_do_conc_gpu) will offload the computation to an accelerator device. Host-device data transfer is handled implicitly by the OpenMP runtime. Like ISO C++, ISO Fortran 2018 has no concept of disjoint memories, so there are no language constructs to control data transfer. This is convenient for the programmer because it simplifies coding. The runtime copies the necessary data to the device, then copies everything back to the host when the DO CONCURRENT loop finishes executing. Here’s the debugging output from the OpenMP runtime if we run the example program on a single 1,000 x 1,000 image with a random scattering of 10 objects:
We’ve highlighted the image and edge mask arrays. Each array is 1,000 x 1,000 x 4 bytes = 4,000,000 bytes, and you can see that they are both transferred from hst→tgt and tgt→hst, so 16,000,000 total bytes are transferred between host (hst) and target (tgt) device. (The unhighlighted 88-byte data movements are the Fortran array descriptors, or dope vectors, of the arrays being mapped to the target device. We can ignore this data movement because array descriptors are generally small.)
Though implicit host-device data transfer is convenient, it isn’t always efficient. Notice that the image variable isn’t modified in the body of the DO CONCURRENT loop (Figure 2). It’s only read on the device, so it doesn’t need to be transferred back to the host. Moving data between disjoint memories takes time and energy, so minimizing host-device data transfer is a first-order concern in heterogeneous parallel computing. Unfortunately, ISO Fortran 2018 and forthcoming 2023 don’t provide language constructs to control data movement.
The OpenMP target offload API provides constructs to explicitly control host-device data transfer (Figure 3). The OpenMP implementation of the edge detection algorithm transfers the image to the device [map(to:image)], but only transfers the edge mask back to the host [map(from:edge_mask)]:
Once again, the image and edge mask arrays are highlighted. You can see that the image (4,000,000 bytes) is transferred from hst→tgt and the edge mask (4,000,000 bytes) is transferred from tgt→hst, so only 8,000,000 total bytes are transferred. The DO CONCURRENT code (Figure 2) does twice the data movement as the OpenMP target offload code (Figure 3).
do j = 1, n
do i = 1, n
edge_mask(i, j) = .false.
if (image (i, j) /= 0) then
if (i == 1 .or. i == n .or. &
j == 1 .or. j == n) then
edge_mask(i, j) = .true.
else
if (any(image(i-1:i+1, j-1:j+1) == 0)) edge_mask(i, j) = .true.
endif
endif
enddo
enddo
Figure 3. Edge detection implemented using OpenMP* target offload (highlighted in blue). The complete code is available at
img_seg_omp_target.F90.
The simple edge detector in this example doesn’t do enough work to merit accelerator offload. We implemented image segmentation using a simple 3x3-point filter on binary images. A more complex filter, real images, and/or volumetric images will be more compute- and/or data-intensive, which will affect the performance and offload characteristics. We will benchmark a more realistic edge detector (e.g., a Sobel filter) and real images in our next article. However, we know from experience that unnecessary host-device data transfer limits performance. An example of this was shown previously in Solving Linear Systems Using oneMKL and OpenMP Target Offloading.
This is a “good news, bad news” situation. The good news is that ISO Fortran code (Figure 2) can run on an accelerator. Letting the runtime implicitly handle host-device data transfer will be fine for many algorithms. The bad news is that edge detection on read-only images isn’t one of them. There’s no way to explicitly control data transfer, so unnecessary data transfer is unavoidable. This could limit heterogeneous parallel performance. Fortunately, the OpenMP target offload API provides explicit control when needed.
You can experiment with Fortran DO CONCURRENT and OpenMP accelerator offload on the free Intel® Developer Cloud, which has the latest Intel® hardware and software.

