Commencing today, we initiate a series of articles that delve into the creation of a GraphQL API using C#. Throughout this exploration, we aim to elucidate the concept of GraphQL, addressing the challenges it seeks to overcome. Subsequently, we will demonstrate the process of implementing an API utilizing the HotChocolate library.
Introduction
Creating an API might initially appear straightforward: one needs to establish endpoints with suitable verbs, enabling clients to retrieve or submit data. However, complications arise when new attributes are required, or when clients don't require all the returned data. This often leads to the creation of custom endpoints for highly specific requests, resulting in the need to manage extensive code maintenance.
To circumvent the challenges of this maintenance nightmare, a novel technology pioneered by Facebook in the early 2010s, named GraphQL, was introduced. GraphQL offers a comprehensive and intelligible representation of the data within our API, empowering clients to request precisely the information they require and nothing beyond that.
Throughout this series, we will delve into the precise nature of GraphQL and elucidate the reasons for its widespread adoption. The concept will be demonstrated through practical examples, specifically written in C# using the corresponding library, HotChocolate.
The subsequent textbooks prove useful for concluding this series.
This article was originally posted here: Building a GraphQL API with HotChocolate
What are APIs?
An API is a set of rules and tools that allows different software applications to communicate with each other. An API defines the methods and data formats that applications can use to request and exchange information. For instance, as developers, if we aim to empower our clients to obtain information regarding accounts or customers, we may furnish an endpoint utilizing the GET method to execute these operations.
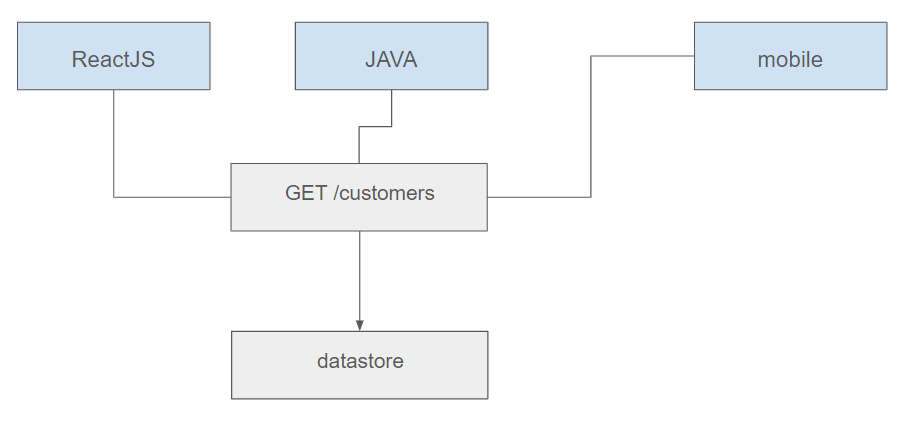
This design is widely recognized in the industry and, additionally, enables the establishment of a unified and standardized interface for all applications.
There's nothing inherently flawed with this process; it is widely used and generally accepted. It is easy to comprehend, implement, and satisfies requirements effectively. Moreover, it can be employed across various programming languages (such as C#, Java, etc.) and utilized by diverse clients (mobile, JavaScript, and so forth). Everything seems perfect in an ideal scenario.
What Occurs if One of the Clients Has Particular Requirements?
In the figure presented earlier, a mobile application is depicted, which has the capability to fetch data about customers. However, let's contemplate a situation where users of this application begin to voice concerns about delays during page loading. Upon investigation, it appears that this is attributed to the fact that the GET/customers endpoint is returning excessive data that is not necessary.

We now have two endpoints for fetching customer data.
But consider now that the Java client has a contrasting requirement: the data returned is insufficient, and it desires additional information in the payload.
We now have three endpoints for fetching customer data.
At this stage, the advantage of having a unified interface for all applications diminishes, as we are approaching a scenario where each client almost necessitates a dedicated backend. Furthermore, if similar adjustments are needed for a few other requests, the maintenance complexity becomes overwhelming. Additionally, getting all the information can require executing multiple requests. To address this challenge, GraphQL was introduced in the early 2010s.
What is GraphQL?
GraphQL is a query language for APIs and a runtime for executing those queries with existing data. It was developed by Facebook in 2012 and open-sourced in 2015. GraphQL provides a more efficient and flexible alternative to traditional REST APIs by allowing clients to request only the data they need.
-
Clients can specify the structure of the response they need, and the server responds with exactly that data. This helps in reducing over-fetching (receiving more data than needed) or under-fetching (not getting enough data).
-
Multiple resources can be retrieved in a single request, eliminating the need for multiple round trips to the server.
GraphQL is not tied to any specific database or storage system and can be used with various programming languages. It has gained popularity for its ability to streamline data fetching and provide a more tailored approach to API development.
But how is this magic accomplished?
GraphQL is nothing more than a specification, and one of its goals is to empower clients to receive precisely what they request. To achieve this, clients and servers must engage in a negotiation regarding the data to be exchanged, and it is the aim of GraphQL to facilitate and fulfill this negotiation.
This negotiation is not achievable with traditional APIs; it requires the installation of a runtime on the server side. This tangible runtime is the implementation of the GraphQL specification.
Information
HotChocolate serves as an illustration of a C# implementation of the GraphQL specification.
How is Communication Established between the Server and the Client?
A GraphQL service is created by defining types and fields on those types, then providing functions for each field on each type.
https://graphql.org/learn/
Hence, the data that can be exchanged is defined on the server side (the specific implementation will, once again, depend on the chosen runtime). As an example, for our customer, we could establish it as follows.
{
type customer {
id : string
name : string
age : float
}
}
Here, we straightforwardly state the existence of an entity of type "customer" with three attributes.
Important 1
The notation employed above to denote an entity is a personal choice and not mandated by GraphQL's specification.
Important 2
In essence, GraphQL simply involves defining a type system for data and implementing a server runtime to process queries according to this type system.
In practice, the defined type system can be significantly more intricate, encompassing nested objects, hence the name GraphQL.
{
type customer {
id : string
name : string
age : integer
commands : [command]
}
type command {
reference : string
amount : float
}
}
GraphQL allows us to define a type system that the server understands, enabling it to return only the requested data. In this regard, GraphQL can be conceptualized as a query semantic engine, imbuing queries with intelligence beyond the simple retrieval of complete JSON data via a GET or POST request.
Once our data has been defined, the next step is to query it on the client side.
Requesting Data on the Client Side
This is where we reap the benefits of all the infrastructure defined on the server side: when querying data on a GraphQL server, we can precisely select only the desired information, no more and no less. Additionally, since the intelligence is now embedded in the query and its payload, there is no longer a necessity for multiple endpoints, as seen in more traditional REST APIs, but only one will be useful (this singular endpoint is universally designated as /graphql). The only requirement is a GraphQL client, specifically a library capable of making requests to a GraphQL server. All programming languages have their own GraphQL clients available, and for this series, we will use JavaScript.
Information
GraphQL requests can be executed using either GET or POST methods, but in this series, we will exclusively utilize POST requests.
Important
This post only provides an overview of the philosophy behind GraphQL. We have omitted many complexities associated with this specification, including advanced features such as subscriptions or mutations. These concepts will be addressed in a more advanced tutorial.
But enough theory for now. We will now delve into the practical implementation of a GraphQL server in C# using the HotChocolate library. But to avoid overloading this article, readers interested in this implementation can find the continuation here.
History
- 6th February, 2024: Initial version

