AWS Simple Storage Service (S3) is one of the most popular cloud storage services. Unlike many goods whose prices increase, storage costs per unit decrease over time. However, the amount of data we store increases much faster than the speed of the decrease of the storage cost per unit, so if we don’t use S3 wisely, we may be surprised by our S3 bill. This article provides a guideline for optimizing the S3 storage cost and includes some S3 details we need to know to use S3 wisely.
Table of Contents
What Does AWS Charge on S3?
Before we know how to save from S3 cost, we need to understand how S3 charges us. The S3 Pricing page (https://aws.amazon.com/s3/pricing/) shows the details of its pricing model. As the article was written, S3 charges not only storage but also data retrieval, data transfer, security, monitoring and analysis, replication, and transformation. Although S3 advertised pay only for what you use, at the core, the cost of some features is inevitable.
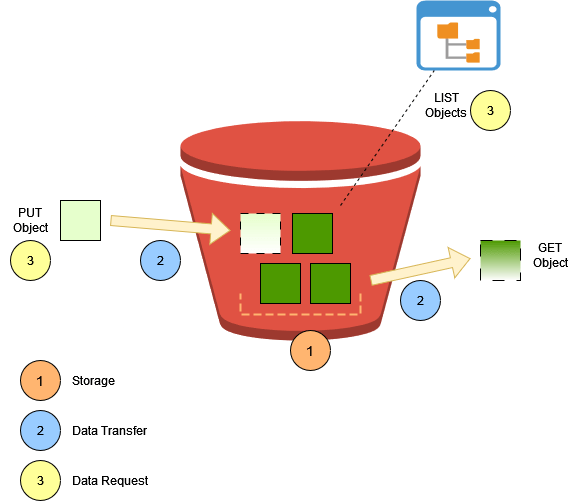
The diagram above shows the minimum operations we would perform when using S3 – ingesting, storing, and reading the data. Therefore, the total cost of S3 can be simplified as this.
Total Cost = Storage Cost + Request Cost + Transfer Cost + Other Cost
Among all the S3 features, the storage size is the critical factor in the equation, which affects how much other operations will be charged. That being said, this article does not talk about costs such as transfer, replication, and encryption because, most of the time, we use those features because we need to, and they are on-demand. Therefore, there is not much we could save from those features.
Storing Data in Suitable Storage Classes
Data stored in S3 are not always treated in the same way. Instead, each object in S3 has a storage class associated with it – different storage classes offer different data access performance and features with different prices. The complete list of available storage classes is available at Amazon S3 Storage Classes. By default, data is stored in the Standard Class – the most efficient and expensive class. Thus, keeping our data in a proper class could save us a lot of money. For example, the following table shows the cost of 100TB of data in different storage classes and how much it could save compared to the Standard Class.
| Class | Rate per Month (as February 2024) | Total | Save |
| Standard | First 50TB: $0.023/GB
Next 450TB: $0.022/GB
| 50 * 1024 GB * 0.023 + 50 * 1024 GB * 0.022 = $2,304 | NA |
| Standard-IA | $0.0125/GB | 100 * 1024 GB * 0.0125 = $1,280 | $1,024 |
| Glacier Instant Retrieval | $0.004/GB | 100 * 1024 GB * 0.004 = $409.6 | $1,894.4 |
| Glacier Flexible Retrieval | $0.0036/GB | 100 * 1024 GB * 0.0036 = $368.6 | $1,935.4 |
| Glacier Deep Archive | $0.00099/GB | 100 * 1024 GB * 0.00099 = $101.38 | $2,202.62 |
Although the example shows how much we could save by storing data in the other classes, the devil is in the details – the classes with cheaper storage costs have higher retrieval costs. Besides, if data is stored in the Deep Archive class, the data needs to be restored before access. The example below calculates the cost of retrieving 100TB of data with 1M GET requests from different classes.
| Class | GET Request Rate per 1000 Requests (as of February 2024) | GET Requests | Data Retrieval Rate per GB (as of February 2024) | Retrievals | Total |
| Standard | $0.0004 | 1,000,000 / 1,000 * 0.0004 = $0.4 | NA | $0 | $0.4 |
| Standard-IA | $0.001 | 1,000,000 / 1,000 * 0.001 = $1 | $0.01 | 100 * 1024 GB * 0.01 = $1024 | $1025 |
| Glacier Instant Retrieval | $0.01 | 1,000,000 / 1,000 * 0.01 = $10 | $0.03 | 100 * 1024 GB * 0.03 = 3072 | $3082 |
| Glacier Flexible Retrieval | $0.0004 | 1,000,000 / 1,000 * 0.0004 = $0.4 | $0.01 (Standard) | 100 * 1024 GB * 0.01 = $1024 | $1024.4 |
| Glacier Deep Archive | $0.0004 | 1,000,000 / 1,000 * 0.0004 = $0.4 | $0.02 (Standard) | 100 * 1024 GB * 0.02 = $2048 | $2048.4 |
This example demonstrates that we may spend more money if we store our data in the cheapest class but neglect the other factors.
Choose the Appropriate Storage Class
The previous section shows how much we could save if we stored our data in the suitable class and how much more money we might spend if we chose the wrong class. So, how do we pick an applicable class? The answer is it depends. Selecting the storage class is based on the access patterns – the patterns we know and those we don’t know.
Data with Known or Predictable Access Patterns
If we know how frequently we need to access the data we store, we can store them in the most cost-efficient class. For example, banks are required to keep records of customers’ accounts for five years after they close their accounts, and the chances of retrieving the data within five years are meager. Therefore, storing the data in an infrequent access or even an archive class makes sense, as long as the storage saving from the non-standard class is more than the cost of data retrieval. We can use the following equation to evaluate if we should move the data to a non-standard class, and if yes, which one.
 , were
, were
- is the total size of data to be stored.
- is the cost of storing data in the Standard Class.
- is the cost of storing data in an infrequent or archive class.
- is the total number of requests to be issued.
- is the cost of each request in an infrequent or archive class.
- is the cost of each request in the Standard Class.
- is the total size of data to be retrieved.
- is the cost of retrieving data from an infrequent or archive class.
- is a threshold that defines the saving as more than a certain number, so we feel comfortable storing the data in the non-standard class in case something comes up.
In the bank example, assuming the bank has 100TB of customer-closed accounts that must be kept for five years. Their experience tells us that the chance of accessing the data is very low, so the bank estimates the maximum data to be retrieved cannot be more than 100TB with 1M requests (in other words, all data is accessed once during the five years). Therefore, we can get the cost estimation by applying the equation above.
| Non-Standard Class | Storage Saving from Standard Class | Additional GET Request Cost from Non-Standard Class | Additional Retrieval Cost from Non-Standard Class | Total Saving from Standard Class |
| Standard-IA | $1,024 * 60 = $61,440 | 1,000,000 / 1,000 * (0.001 – 0.0004) = $0.6 | $1,024 | $61,440 – $0.6 – $1024 = $60,415.4 |
| Glacier Instant Retrieval | $1,894.4 * 60 = $113,664 | 1,000,000 / 1,000 * (0.01 – 0.0004) = $9.6 | $3,072 | $113,664 – $9.6 – $3072 = $110,582.4 |
| Glacier Flexible Retrieval | $1,935.4 * 60 = $116,124 | 1,000,000 / 1,000 * (0.0004 – 0.0004) = $0 | $1,024 | $116,124 – $0 – $1024 = $115,100 |
| Glacier Deep Archive | $2,202.62 * 60 = $132,157.2 | 1,000,000 / 1,000 * (0.0004 – 0.0004) = $0 | $2,048 | $132,157.2 – $0 – $2048 = $130,109.2 |
(The number of storage-saving and retrieval costs came from the example in the previous section)
The table shows how much money we could save by applying the equation. Of course, we still need to consider other factors of storing data in a non-standard class, such as how long it takes to retrieve data from Glacier Deep Archive. However, at the minimum, it gives us a rough idea of our potential storage cost and savings.
Moving Data Between Classes
By default, S3 stores newly created objects in the Standard Class unless we specify the storage class when storing data, such as using Boto3 put_object API, which allows putting an object to an exact storage class. However, in most cases, we move data from the Standard Class to a non-standard class, and the most efficient way to transfer data between classes is to leverage the S3 Lifecycle. With a lifecycle, we can define rules to perform specific actions on a group of objects. For instance, in the bank example mentioned in the previous section, we can configure a lifecycle policy that will move the customer records from Standard Class to Glacier Deep Archive after their accounts have closed and delete the data after five years.
Although the S3 Lifecycle is the most efficient way to move data between classes, it is not free, so the lifecycle cost needs to be included in the S3 total cost equation.
Total Cost = Storage Cost + Request Cost + Transfer Cost + Lifecycle Cost
Data with Unknown Access Patterns
When the access pattern is unknown or unpredictable, AWS S3 has a solution – an intelligent Tier.
Intelligent-Tiering
Intelligent-Tiering automatically moves data to the most cost-effective tier based on access pattern by monitoring how the data is accessed. The tiers within the Intelligent-Tiering class are different than the other storage classes. See the diagram below.
Unlike other storage classes, there is no data retrieval fee, and the request costs are the same in all tiers. However, monitoring and automation objects have costs that need to be considered.
Total Cost = Storage Cost + Monitoring Fee
In this equation, the storage cost is the summation of the storage costs of each tier, and the monitoring fee is based on the number of objects.
The Intelligent-Tiering class is a great way to optimize our S3 storage cost. AWS S3 recommends using Intelligent-Tiering in most cases. However, there is still room to improve the costs.
First, object size matters. Object sizes smaller than 128KB will not be monitored, so they won’t be moved to different tiers and will be charged as the Frequent Access tier (See Automatic Access tiers in the How it works section). So, avoid storing objects smaller than 128KB.
Second, the number of objects matters. As the article was written, the cost of monitoring and automation in Intelligent-Tiering is $0.0025 per 1000 objects, which means with the same amount of data, if one has more big objects, but the other one has more small objects, the latter needs to pay more monitoring fee than the former. The table below demonstrates the difference between the two scenarios – one has an average object size of 1 MB, and the other has 100 MB, but both have a total size of 100 TB of data.
| Object Size | Number of Objects | Monitoring Cost |
| 1 MB | 104,857,600 | 104,857,600 / 1000 * 0.0025 = $262.14 |
| 100 MB | 1,048,576 | 1,048,576 / 1000 * 0.0025 = $2.62 |
The example clearly shows that the cost of monitoring and automation fees in the one with small objects is much more than in the one with big objects. Of course, it’s unlikely every object will be the same size, but it gives us an idea that the number of objects matters.
Third, if the data access pattern is stable, we may not gain benefits from Intelligent-Tiering but spend an unnecessary extra fee. For instance, if no data is moved between tiers because all data is actively accessed, all data is stored in the Frequent Access tier. Still, the Intelligent-Tiering class charges a monitoring fee. Therefore, we pay the extra monitoring fee without getting benefits.
Monitor and Analysis
We don’t know how well we do if we don’t measure our S3 usage and monitor its behavior. AWS provides a few options to gain insights into S3 – Storage Lens, Storage Class Analysis, and S3 Inventory.
- Storage Lens offers account-level or organization-wide insights into storage usage and activity trends, detailed metrics, and cost optimization recommendations.
- Storage Class Analysis monitors data access patterns and classifies data as frequently or infrequently accessed by age of objects. The analysis reports include metrics like object age, object count and size, request count, and data uploaded, storage, and retrieved size.
- S3 Inventory reports object-level metrics such as version ID, size, storage class, and the tier of the Intelligent-Tiering class.
With the reports generated from these monitoring and analysis features, we can evaluate our storage usage to ensure the way we use S3 is optimized. However, except for the default dashboard of the Storage Lens, the monitoring and analysis features all have their costs. Besides, Storage Class Analysis and S3 Inventory can export and store reports in S3. Those files are subject to S3 storage charges. Depending on the export frequency and number of objects monitored, the files produced by Storage Class Analysis and S3 Inventory can grow very fast and consume a lot of storage, which must be considered in the S3 cost optimization plan.
The Number of Objects Matters
Similar to the monitoring and automation fee in the Intelligent-Tiering class, all the monitoring and analytics are charged by the number of objects monitored. Besides, the smaller the number of objects, the fewer PUT, GET, and all other requests are needed. Lifecycle transition requests will be cheaper, too. Therefore, we should make the objects as compact as possible with the same amount of data. This not only improves the data access performance but also saves money from the S3 features that charge by object count.
Best Practice
This section describes some use cases that may be helpful in similar situations.
Set Intelligent-Tiering as Default
Since the Intelligent-Tiering Class is the preferred class in many use cases, it makes sense if it is the default storage class. However, newly created objects are stored in the Standard Class by default. Fortunately, there are two ways to immediately put a newly created object in the Intelligent-Tiering Class so the Intelligent-Tiering Class behaves as the default storage class.
The first method is to specify the class when storing data. If we control the producer who puts the data to S3, we can specify Intelligent-Tiering as the storage class when calling PUT API or SDK (e.g., Boto3 put_object).
Nevertheless, we don’t control the producer in most cases, so the second way is to leverage S3 Lifecycle to move a newly created object into the Intelligent-Tiering Class as soon as the object is put into S3. A lifecycle example that does this is exhibited below.
The lifecycle moves newly created objects to Intelligent-Tiering immediately (Note that the lifecycle policy above also deletes noncurrent versions after seven days).
ETL
Usually, the access pattern of an ETL is predictable and stable, and a typical ETL has three steps – extract, transform, and load, like the picture shown below.
In the extract step, the ETL extracts the data from the source; the raw data is stored (e.g., s3://my_bucket/raw/ in this example). The transform step reads the raw data and processes it (assuming it only reads the data that hasn’t been processed). During the transformation, some temporary data may be created and stored (e.g., s3://my_bucket/temp/). Once the data is processed, the ETL loads the processed data to the target location (e.g., s3://my_bucket/table/) from which a user can query.
Assuming the pipeline runs once daily, the raw data will be written once and read once in this setup. Therefore, a lifecycle policy like the one below would be a good choice for the data in s3://my_bucket/raw/.
The raw data will stay in the Standard Class for thirty days in case we need to debug any issue. After that, objects will be moved to Glacier Instant Retrieval Class and expire after 90 days. If an object becomes noncurrent, it will be deleted after 30 days.
Regarding the processing data (stored in s3://my_bucket/temp/), since it’s temporary and the ETL runs once a day, we can have a lifecycle policy that deletes the temporary data, like the following example.
Finally, once the data has been processed, it will be stored at s3://my_bucket/table/, and accessed frequently by applications and users, so the default Standard Class is the best option—no need to move the data to other classes.
Delete Data Properly
When deleting data, we need to ensure the data is deleted, especially in the following scenarios.
Versioning is Enabled
When versioning is enabled, the DELETE operation does not permanently delete an object whether the DELETE operation is issued through S3 Console, API, SDK, or CLI. Instead, S3 inserts a delete marker in the bucket, and the delete marker becomes the current object version with a new object ID.
When we try to GET the deleted object (i.e., the object’s current version is a delete marker), S3 returns a Not Found error – it behaves like the object had been deleted. However, if we enable Show versions in the S3 Console, we can see the delete marker, and all noncurrent versions still exist.
Therefore, the object still exists in the bucket, and we keep paying its storage fee. There are several ways to make sure an object is really deleted (of course, in the case we really want to delete them). When using the S3 Console, we need to enable the Shoe versions option to view and select the object to delete.
One thing worth mentioning is the confirmation message when deleting an object via the S3 Console. If deleting an object with version ID, the confirmation message is permanently delete (this is the same when deleting an object in a versioning-disabled bucket). On the contrary, if deleting an object without version ID, the confirmation message is just delete. So, from the message, we can tell whether an object is really deleted or not.
A programmatically way is to use a lifecycle policy to clean deleted objects. For instance, we can use a lifecycle policy like the one below to ensure the objects are deleted.
When an object is deleted, a delete marker is created and becomes the current version; the original object becomes noncurrent. This lifecycle policy permanently deletes objects 30 days after they are deleted (i.e., become noncurrent), and when a delete marker has no noncurrent object, the delete marker becomes an expired object delete marker, and will be deleted by the lifecycle policy as well. In other words, thirty days after an object is deleted, the object, including the versions, and its delete marker will be permanently deleted.
Note that lifecycle cannot permanently delete objects without expiring them. If it could, it contradicts the purpose of having a versioning-enabled bucket. Therefore, if we want to always permanently delete objects (i.e., no delete markers are added), we should use a versioning-disabled bucket.
Besides, when deleting an object via API, SDK, or CLI, we must specify the object’s version ID to ensure the object is permanently deleted. In this case, S3 will not create a delete marker and will permanently delete the object’s specific version.
AWS S3 has a detailed document describing how deleting works in a versioning-enabled bucket: Deleting object versions from a versioning-enabled bucket – Amazon Simple Storage Service
S3 is a common building block of big data solutions – using S3 as the storage layer, and there is a query engine (e.g., Databricks and Snowflake) on top of it so that people can query objects like a database with data stored in S3. The query engine maintains its metadata to manage the objects stored in S3 and perform better. Depending on the query engine’s design and configuration, the behavior of deleting may not be the same as our expectation. For example, using the DROP TABLE command on an external table in Databricks only deletes the metadata, not the data; the data itself still exists in S3, and we keep paying the storage fee. Therefore, when using query engines with AWS S3, we need to pay attention to how the query engines interact with S3, especially when deleting data.
Avoid Redundant Backup Data
AWS S3 offers excellent options to backup data and keep the history of the data, such as S3 Replication and Versioning, and we anticipate backing up data to increase the storage footprint. However, the increased size of backup data may blow our minds when using applications with S3. The following scenario demonstrates what could be an issue.
Assuming we use Databricks with S3, Databricks offers a feature called Time Travel, which allows us to go back to an older version of a Delta table. To make the time travel work, Databricks needs to keep a copy of each version of the table (stored in S3 in this case). Consider a Spark job running hourly and performing an overwrite method like the code below.
df = spark.read...
df = ...
df.write.format("delta").mode("overwrite").save("<S3 Location>")
If the size that the job writes is about 1GB, because of the Time Travel feature, one year later, there will be 8,760GB (365 *24) stored in S3. Usually, the reason we use overwrite mode in Spark is that we don’t care about the previous data that is overwritten. We might also think we don’t generate unnecessary backups by doing overwrites, yet we might not know the application has been doing backups all the time. Worse than that, the S3 lifecycle does not help in this case. The reason is that every copy written to S3 is treated as a new object (i.e., the current version), so the older copy will never become noncurrent. Therefore, we cannot use a lifecycle policy to delete the old copies. It’s tough to expire the current version because S3 has no idea what happens from the application side; it might accidentally delete the data we need.
A solution in this Databricks use case is to leverage the VACUUM command, designed for cleaning the old copies created by the Time Travel feature.
Unfortunately, there is no single solution to handle this situation, which depends on the application. All we can do is to be aware of how the application works with S3.
Optimize the Data
In the session, The Number of Objects Matter, we learned the number of objects affects S3 costs a lot. A general principle is to make the objects larger but fewer objects. Some applications, such as a query engine, can make objects compact. For example, Databricks provides an OPTIMIZE command to coalesce small objects into larger objects. If the applications we use have this kind of ability, we should utilize them.
Do Not Monitor Something Unnecessary
We all know the importance of monitoring data. However, monitoring is not free in S3, so we must carefully choose what to monitor. Usually, we monitor the data whose access pattern and usage are unknown so that we can lay out our S3 plan accordingly or adjust our S3 strategy by reviewing the monitoring reports. On the contrary, we won’t get much value from monitoring something we already know – something we should avoid.
Types of data we usually don’t need to monitor:
- Temporary data. Temporary data usually live for a short period; there is no reason we monitor it.
- Landing data. In a typical ETL, the landing data is usually raw and needs to be transformed. Those data are typically read only once.
- Data with stable and predictable access patterns.
- Log data. Log data are usually small, but many are not accessed often and will be deleted eventually.
- Cold data. Cold data are those mainly for backup and are rarely accessed.
Besides, we should keep an eye on the monitoring fee to ensure the monitoring fee does not exceed the savings we could potentially get from monitoring. This may happen when there are a lot of small objects to be monitored, and since the objects are small, we won’t gain much savings from moving objects to a cheaper class. Ironically, this is hard to know without measuring. The only way to avoid this is to review our monitoring setup and monitoring reports periodically.
Monitoring our data is essential, but it comes at a price; use it wisely.
Summary
The following are some tips that may help optimize our S3 cost.
- Store data in the most appropriate storage class.
- Prefer Intelligent-Tiering except in the following situations.
- The data access patterns are well-known, predictable, and stable.
- Temporary data that will be deleted (especially in a short period)
- Lifecycle data that are no longer active or needed.
- Lifecycle old versions that are no longer needed.
- Coalesce objects to be bigger but less.
- Periodically review S3 insights using storage lens, inventory, or analysis. Even if everything is in Intelligent-Tiering, unknown data access patterns may become known by examining the data insights.
- When versioning is enabled, ensure a lifecycle policy to clean deleted objects.
- Understand how applications interact with S3.
The cost of using S3 is affected by many factors, and it’s not possible to have a solution that constantly optimizes our S3 storage cost automatically. The only way to ensure our S3 cost optimized is to keep reviewing our S3 usage and adjust our approach accordingly.

