htcw_json is a pull parser for reading JSON using very little memory. It has a small flash footprint, cross platform capability, and can parse JSON of virtually any size. It does minimal validation, since most often JSON is machine generated anyway.
Introduction
REST is everywhere. Outside of using MQTT, for connected devices it's almost a necessity to be able to communicate with REST servers and handle returned data in JSON format.
There are a few solutions out there, but at best they have a large flash footprint, and at worst they have a large memory footprint and/or are not cross platform. The ones that create an in memory model quickly break down on constrained devices when dealing with a lot of content.
I've taken a different approach to parsing JSON. Taking a page from Microsoft .NET's XmlReader I've created a similar "pull" style parser for reading JSON. The advantage is efficiency. The disadvantage is that like XmlReader it can be more difficult to use than traditional JSON parsers depending on what you need to do.
Prerequisites
- You'll need a C++11 or better toolchain
- This depends on my io library and my bits library.
To run the demo:
- You'll need VS Code with Platform IO installed
- You'll need an ESP32
- You'll need to modify the code or otherwise set your SSID and WiFi password for the ESP32 to use worldtimeapi.org
- You'll need to Upload Filesystem Image to get data.json onto the device
Background
This parser is somewhat minimalist, but at the same time contains some happy features, like the ability to chunk values that are longer than one's defined capture buffer size as well as resolving some basic data types - namely integers, real numbers, and booleans.
You tell it how much memory you want it to use. The only requirement on memory is that field names must be able to fit into the allocated space. For example, if you allocate 1KB (the default), field names can be no longer than that. There is no similar restriction on the values, but if a value is longer than the allocated space for the capture buffer it will retrieve the data as a series of "value parts"
From there you cook a loop - typically something like while(reader.read())... and then inside that loop you check the reader's node_type() and act accordingly. You can retrieve the current value or field name using value(). You can get typed values with value_int(), value_real(), and value_bool(). This process should be somewhat familiar if you've used XmlReader before.
Using the code
I'll provide an example of using the library below. This is assuming an ESP32 because I had one handy and it is Internet connectable, but that's not a requirement. It also is written for Arduino but can be readily ported to other platforms. You can adapt this code and use it on a PC, a STM32, an NXP, a SAMD51 or whatever.
Let's look at how to dump all the data from a document, since that puts the pull parser through its paces. Note that this is not a pretty print routine, as it does not emit valid JSON, but rather a hierarchal presentation of the data that is JSON-ish:
#include <Arduino.h>
#include <WiFi.h>
#include <HTTPClient.h>
#include <SPIFFS.h>
#include <json.hpp>
using namespace io;
using namespace json;
void indent(int tabs) {
while(tabs--) Serial.print(" ");
}
void dump(json_reader_base& reader, Stream& output) {
bool first_part=true; int tabs = 0; bool skip_read = false; while(skip_read || reader.read()) {
skip_read = false;
switch(reader.node_type()) {
case json_node_type::array:
indent(tabs++);
output.println("[");
break;
case json_node_type::end_array:
indent(--tabs);
output.println("]");
break;
case json_node_type::object:
indent(tabs++);
output.println("{");
break;
case json_node_type::end_object:
indent(--tabs);
output.println("}");
break;
case json_node_type::field:
indent(tabs);
output.printf("%s: ",reader.value());
while(reader.read() && reader.is_value()) {
output.printf("%s",reader.value());
}
output.println("");
skip_read = true;
break;
case json_node_type::value:
indent(tabs);
output.printf("%s\r\n",reader.value());
break;
case json_node_type::value_part:
if(first_part) {
indent(tabs);
first_part = false; }
output.printf("%s",reader.value());
break;
case json_node_type::end_value_part:
output.printf("%s,\r\n",reader.value());
first_part = true;
break;
}
}
}
Again, if you've used XmlReader this should be somewhat familiar. Basically all it's doing is reading each element out of the document and printing them as it finds them, with formatting.
Let's continue with a more real world example. Here we'll be picking information out of a JSON document:
{
"air_date": "2007-06-28",
"episode_number": 1,
"id": 223655,
"name": "Burn Notice",
"overview": "Michael Westen is a spy who receives a \"burn notice\" while on assignment. Spies are not fired, rather they are issued a burn notice to let the agent know their services are no longer required.\n\nPenniless, Michael returns to his roots in Miami where he freelances his skills to earn money. First up, Michael helps a man clear his name after valuable pieces of art and jewelery are stolen.",
"production_code": null,
"season_number": 1,
"show_id": 2919,
"still_path": "/7lypjkgNLkYDxwcqGWmZmHH5ieq.jpg",
"vote_average": 8,
"vote_count": 1,
"crew": [
{
"id": 20833,
"credit_id": "525749d019c29531db098a72",
"name": "Jace Alexander",
"department": "Directing",
"job": "Director",
"profile_path": "/nkmQTpXAvsDjA9rt0hxtr1VnByF.jpg"
},
{
"id": 1233032,
"credit_id": "525749d019c29531db098a46",
"name": "Matt Nix",
"department": "Writing",
"job": "Writer",
"profile_path": null
}
],
"guest_stars": [
{
"id": 6719,
"name": "Ray Wise",
"credit_id": "525749cc19c29531db098912",
"character": "",
"order": 0,
"profile_path": "/z1EXC8gYfFddC010e9YK5kI5NKC.jpg"
},
{
"id": 92866,
"name": "China Chow",
"credit_id": "525749cc19c29531db098942",
"character": "",
"order": 1,
"profile_path": "/kUsfftCYQ7PoFL74wUNwwhPgxYK.jpg"
},
{
"id": 17194,
"name": "Chance Kelly",
"credit_id": "525749cc19c29531db09896c",
"character": "",
"order": 2,
"profile_path": "/hUfIviyweiBZk4JKoCIKyuo6HGH.jpg"
},
{
"id": 95796,
"name": "Dan Martin",
"credit_id": "525749cd19c29531db098996",
"character": "",
"order": 3,
"profile_path": "/u24mFuqwEE7kguXK32SS1UzIQzJ.jpg"
},
{
"id": 173269,
"name": "Dimitri Diatchenko",
"credit_id": "525749cd19c29531db0989c0",
"character": "",
"order": 4,
"profile_path": "/vPScVMpccnmNQSsvYhdwGcReblD.jpg"
},
{
"id": 22821,
"name": "David Zayas",
"credit_id": "525749cd19c29531db0989ea",
"character": "",
"order": 5,
"profile_path": "/eglTZ63x2lu9I2LiDmeyPxhgwc8.jpg"
},
{
"id": 1233031,
"name": "Nick Simmons",
"credit_id": "525749cf19c29531db098a17",
"character": "",
"order": 6,
"profile_path": "/xsc2u2QQA6Nu7SvUYUPKFlGl9fw.jpg"
}
]
}
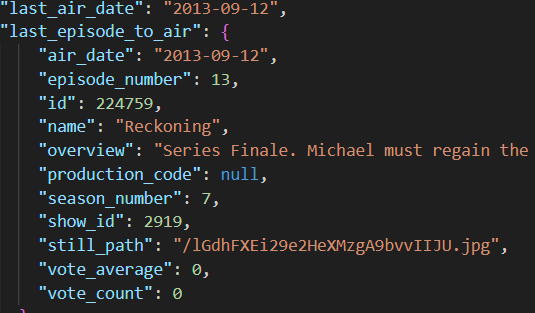
This isn't the full document which is almost 190KB, but rather one of the inner "episode objects" that describes a television series episode. We're going to navigate to each of these and just grab the season number, episode number, name, and overview fields and then print them to the output.
First, a quick and dirty search for the episodes fields which each contain an array of episode objects as shown above. There are one of these fields for each season.
void read_series(json_reader_base& reader, Stream& output) {
while(reader.read()) {
switch(reader.node_type()) {
case json_node_type::field:
if(0==strcmp("episodes",reader.value())) {
read_episodes(reader, output);
}
break;
default:
break;
}
}
}
Now let's look at cracking the episodes array apart and printing the information for each individual episode to the output.
char name[2048];
char overview[8192];
void read_episodes(json_reader_base& reader, Stream& output) {
int root_array_depth = 0;
if(reader.read() && reader.node_type()==json_node_type::array) {
root_array_depth = reader.depth();
while(true) {
if(reader.depth()==root_array_depth &&
reader.node_type()==json_node_type::end_array) {
break;
}
if(reader.read()&&
reader.node_type()==json_node_type::object) {
int episode_object_depth = reader.depth();
int season_number = -1;
int episode_number = -1;
while(reader.read() &&
reader.depth()>=episode_object_depth) {
if(reader.depth()==episode_object_depth &&
reader.node_type()==json_node_type::field) {
if(0==strcmp("episode_number",reader.value()) &&
reader.read() &&
reader.node_type()==json_node_type::value) {
episode_number = reader.value_int();
}
if(0==strcmp("season_number",reader.value()) &&
reader.read() &&
reader.node_type()==json_node_type::value) {
season_number = reader.value_int();
}
if(0==strcmp("name",reader.value())) {
name[0]=0;
while(reader.read() && reader.is_value()) {
strcat(name,reader.value());
}
}
if(0==strcmp("overview",reader.value())) {
overview[0]=0;
while(reader.read() && reader.is_value()) {
strcat(overview,reader.value());
}
}
}
}
if(season_number>-1 && episode_number>-1 && name[0]) {
output.printf("S%02dE%02d %s\r\n",
season_number,
episode_number,
name);
if(overview[0]) {
output.printf("\t%s\r\n",overview);
}
output.println("");
}
}
}
}
}
It's a little hairy, but nothing some thinking through can't solve. It reads through the array, keeping track of where it ends by hanging on to the depth(). It does something similar with each object so as not to traverse nested objects looking for things like name.
Reading from a file, such as from SPIFFS or an SD card is pretty straightforward once you understand some concepts. The first is that we wrap Arduino objects in our own streams. The reason for this is due to the cross platform nature of the library combined with the decoupling from The STL. The JSON library only works with our streams, which themselves are adaptable to different platforms as below. The other thing to bear in mind is the files are binary and not technically text. The reason for this is UTF-8 is not ASCII, and in C text typically means ASCII. We don't want it cooking our Unicode surrogates or any other funny business, so binary mode is what's for dinner.
File file = SPIFFS.open("/data.json","rb");
if(!file) {
return;
}
file_stream file_stm(file);
json_reader file_reader(file_stm);
dump(file_reader, Serial);
file_stm.close();
We basically just open the file - in this case from SPIFFS but it could be from an SD - as binary, wrap it, and then pass it to a json_reader instance. If you want to specify a different capture size, like 512 bytes for example, you'd use json_reader_ex<512> instead of json_reader.
After that we just call the dump() routine presented earlier.
If you need to read from some other Arduino source you can use arduino_stream to wrap things like WiFiClient and HardwareSerial instances. Obviously these are only available when using the Arduino framework.
Here's an example of connecting to the worldtimeapi.org REST service from an ESP32 and dumping the data:
constexpr static const char* wtime_url="http://worldtimeapi.org/api/ip";
WiFi.mode(WIFI_STA);
WiFi.disconnect();
WiFi.begin();
while(WiFi.status()!=WL_CONNECTED) {
delay(10);
}
HTTPClient client;
client.begin(wtime_url);
if(0>=client.GET()) {
while(1);
}
WiFiClient& www_client = client.getStream();
arduino_stream www_stm(&www_client);
json_reader www_reader(www_stm);
dump(www_reader, Serial);
WiFi.disconnect();
The included demo app is for an ESP32 and Platform IO and will demonstrate everything presented above.
History
- 30th March, 2024 - Initial submission
- 31st March, 2024 - Improved example, and small API improvements

