Creating an AI module for CodeProject.AI Server that handles a long-running process is not rocket science. This article will walk you through the steps to create a ChatGPT-like module.
The full code can be found in our GitHub repository at CodeProject.AI-Server/src/modules/LlamaChat at main · codeproject/CodeProject.AI-Server (github.com)
Introduction
This article will show you how to get a ChatGPT-like Large Language Model (LLM) running locally on your desktop. There are a ton of reasons why you would do this: to ensure your sensitive data stays inside your network, to avoid inscrutable hosting fees, to have access to a LLM when you have no internet. Our reason is: because they are cool and we want to play with them.
We're going to use CodeProject.AI Server to handle all the annoying setup, deployment and lifecycle management so we can focus on the code. And there truly isn't that much code due to the magic being bundled up in the distressingly large models that are available. The one point of interest (apart from the fairly major point of LLMs themselves) is the handling of long running inference calls within CodeProject.AI Server.
Traditionally, modules for CodeProject.AI Server operate on the assumption that any inferencing (running data against an AI model) is quick enough that the results are returned well within the timeout of a typically HTTP API call to the server. For LLMs this isn't the case. A prompt is sent, the model chews on it a bit, then the continuation or chat response is returned piece by piece. It can take a while, and so for that we will introduce long running processes in CodeProject.AI Server.
Getting Started
We're going to assume you have read CodeProject.AI Module creation: A full walkthrough in Python. We'll be creating a module in exactly the same manner, with the small addition that we'll show how to handle long running processes.
We also assume that you have set up your development environment following the guidance of Installing CodeProject.AI Development Environment.
The library we'll use is Llama-cpp, wrapped in python (llama-cpp-python), and the model will be Mistral 7B Instruct v0.2 - GGUF, a 7.3 billion parameter model with a 32K context window and impressive capabilities on desktop-grade hardware. This model is designed for Llama, the LLM released by Meta AI in 2023. Llama-cpp-python is a Python wrapper for a C++ interface to the Llama models. It all runs quite smoothly, which is a testament to the Mistral 7b model and the work by Georgi Gerganov on llama-cpp.
If you're looking for other Llama compatible models to experiment with then I would suggest trying Hugging Face, and in particular models quantized by TheBloke (Tom Jobbins). As new and improved models are being released almost every day, you can use LLM Leaderboards to choose an LLM appropriate for your use-case and hardware.
Writing any CodeProject.AI Server Module is an easy process. Our SDKs do most of the heavy lifting allowing you to just worry about implementing the functionality for your use-case. The steps that will be taken in our module creation adventure are:
- Create a Project in the CodeProject.AI Server Solution.
- Create a modulesettings.json file to define metadata about the module required to run and communicate with it.
- Write the Python code for the Module.
- Write a Python file that wraps the llma-cpp-python package to expose the functionality required, usually as a Class.
- Write a Python file that implements an adaptor which connects the CodeProject.AI Server to the above wrapper. This is where the magic happens.
- Create the files required for Module Installation
- Create the installation scripts
- Create the PIP requirements.txt files.
- Create the UI for the CodeProject.AI Dashboard.
Creating the packaging script so the module can be deployed to the CodeProject.AI Module Repository is detailed in Adding your own Python module to CodeProject.AI and will not be discussed in this article.
Testing of the module is also not discussed in this article but suggestions for this can be found at Adding your own Python module to CodeProject.AI.
Create the Project
CodeProject.AI Server already contains this module in the current codebase, but we'll walk through the creation of this module as if it wasn't there. For this, we first need to create a folder "Llama" inside /src/modules in the CodeProject.AI Server solution.

Create the modulesettings.json files
Again, make sure you've reviewed A full walkthrough in Python and The ModuleSettings files. Our modulesettings file is very basic, with the interesting bits being:
- Our adapter, which will be used to launch the module, is llama_chat_adapter.py
- We'll run under python3.8
- We'll set some environment variables to specify the location of the folders containing models, and the model name
- We'll define a route "text/chat" that takes a command "prompt" that accepts a string "prompt" and returns a string "reply"
{
"Modules": {
"LlamaChat": {
"Name": "LlamaChat",
"Version": "1.0.0",
"PublishingInfo" : {
...
},
"LaunchSettings": {
"FilePath": "llama_chat_adapter.py",
"Runtime": "python3.8",
},
"EnvironmentVariables": {
"CPAI_MODULE_LLAMA_MODEL_DIR": "./models",
"CPAI_MODULE_LLAMA_MODEL_FILENAME": "mistral-7b-instruct-v0.2.Q4_K_M.gguf"
"CPAI_MODULE_LLAMA_MODEL_REPO": "@TheBloke/Mistral-7B-Instruct-v0.2-GGUF",
"CPAI_MODULE_LLAMA_MODEL_FILEGLOB": "*.Q4_K_M.gguf",
},
"GpuOptions" : {
...
},
"InstallOptions" : {
...
},
"RouteMaps": [
{
"Name": "LlamaChat",
"Route": "text/chat",
"Method": "POST",
"Command": "prompt",
"MeshEnabled": false,
"Description": "Uses the Llama LLM to answer simple wiki-based questions.",
"Inputs": [
{
"Name": "prompt",
"Type": "Text",
"Description": "The prompt to send to the LLM"
}
],
"Outputs": [
{
"Name": "success",
"Type": "Boolean",
"Description": "True if successful."
},
{
"Name": "reply",
"Type": "Text",
"Description": "The reply from the model."
},
...
]
}
]
}
}
}
Writing the Module Code
The whole point of creating a module for CodeProject.AI Server is to take existing code, wrap it, and allow it to be exposed by the API server to all and sundry. This is done with two files, one to wrap the package or example code, and an adapter to connect the CodeProject.AI Server this wrapper.
Wrapping the llama-cpp-python package
The code we're going to wrap will be in llama_chat.py. This simple Python module has two methods: the __init__ constructor, which creates a Llama object, and do_chat which take a prompt and returns text. The returned text from do_chat is either a CreateChatCompletionResponse object, or if streaming, an Iterator[CreateChatCompletionStreamResponse] object. The **kwargs parameter allows arbitrary additional parameters to be passed to the LLM create_chat_completion function. See the llama-cpp-python documentation for details on what parameters are available and what they do.
import os
from typing import Iterator, Union
from llama_cpp import ChatCompletionRequestSystemMessage, \
ChatCompletionRequestUserMessage, \
CreateCompletionResponse, \
CreateCompletionStreamResponse, \
CreateChatCompletionResponse, \
CreateChatCompletionStreamResponse, \
Llama
class LlamaChat:
def __init__(self, repo_id: str, fileglob:str, filename:str, model_dir:str, n_ctx: int = 0,
verbose: bool = True) -> None:
try:
self.model_path = os.path.join(model_dir, filename)
self.llm = Llama(model_path=self.model_path,
n_ctx=n_ctx,
n_gpu_layers=-1,
verbose=verbose)
except:
try:
self.model_path = os.path.join(model_dir, fileglob)
self.llm = Llama.from_pretrained(repo_id=repo_id,
filename=fileglob,
n_ctx=n_ctx,
n_gpu_layers=-1,
verbose=verbose,
cache_dir=model_dir,
chat_format="llama-2")
except:
self.llm = None
self.model_path = None
def do_chat(self, prompt: str, system_prompt: str=None, **kwargs) -> \
Union[CreateChatCompletionResponse, Iterator[CreateChatCompletionStreamResponse]]
if not system_prompt:
system_prompt = "You're a helpful assistant who answers questions the user asks of you concisely and accurately."
completion = self.llm.create_chat_completion(
messages=[
ChatCompletionRequestSystemMessage(role="system", content=system_prompt),
ChatCompletionRequestUserMessage(role="user", content=prompt),
],
**kwargs) if self.llm else None
return completion
As you can see, it doesn't take a lot of code to implement this file.
Create the Adapter
The adapter is a class derived from the ModuleRunner class. The ModuleRunner does all the heavy lifting for:
- Retrieving commands from the server
- Calling the appropriate overloaded functions on the derived class
- Returning responses to the server
- Logging
- Sending periodic module status updates to the server.
Our adapter is in the module llama_chat_adapter.py and contains the overriden methods as discussed in A full walkthrough in Python. The file can be viewed in its entirety in the source in the GitHub repository.
An important note: The response from a call to llm.create_chat_completion (ie calling the LLM) can be a single response, or a streamed response. Both take time, but we'll choose to return the response as a stream allowing us to build up the reply incrementally. We will be doing this via the long process mechanism in CodeProject.AI Server. This means we will make the request to the LLM using the code in llama_chat.py and iterate over the returned value accumulating the LLM's generated reply. To display the accumulating reply after the initial request to the CodeProject.AI Server, the client can poll for the command status.
We will discuss each part of the file, explaining what each does. The complete file can be viewed in the GitHub repository.
Preamble
The preamble sets up a package search path to the SDK, has the imports required by the file, and defines the LlamaChat_adapter class.
sys.path.append("../../SDK/Python")
from common import JSON
from request_data import RequestData
from module_runner import ModuleRunner
from module_options import ModuleOptions
from module_logging import LogMethod, LogVerbosity
from llama_chat import LlamaChat
class LlamaChat_adapter(ModuleRunner):
initialise()
The initialise() function is overloaded from the base ModuleRunner class and initializes the adapter when it starts. In this module it:
- Reads environment variable that define the LLM model to be used to process the prompt.
- Creates an instance of the
LlamaChat class using the specified model.
def initialise(self) -> None:
self.models_dir = ModuleOptions.getEnvVariable("CPAI_MODULE_LLAMA_MODEL_DIR", "./models")
self.model_repo = ModuleOptions.getEnvVariable("CPAI_MODULE_LLAMA_MODEL_REPO", "TheBloke/Llama-2-7B-Chat-GGUF")
self.models_fileglob = ModuleOptions.getEnvVariable("CPAI_MODULE_LLAMA_MODEL_FILEGLOB", "*.Q4_K_M.gguf")
self.model_filename = ModuleOptions.getEnvVariable("CPAI_MODULE_LLAMA_MODEL_FILENAME", "mistral-7b-instruct-v0.2.Q4_K_M.gguf")
verbose = self.log_verbosity != LogVerbosity.Quiet
self.llama_chat = LlamaChat(repo_id=self.model_repo,
fileglob=self.models_fileglob,
filename=self.model_filename,
model_dir=self.models_dir,
n_ctx=0,
verbose=verbose)
if self.llama_chat.model_path:
self.log(LogMethod.Info|LogMethod.Server, {
"message": f"Using model from '{self.llama_chat.model_path}'",
"loglevel": "information"
})
else:
self.log(LogMethod.Error|LogMethod.Server, {
"message": f"Unable to load Llama model",
"loglevel": "error"
})
self.reply_text = ""
self.cancelled = False
process()
The process() function is called when a command is received that is not one of the common module commands. It will do one of two things:
- Process the request and return a response. This is the mode for short duration processing such as Object Detection.
- Return a Callable that will be executed in the background to process the requested command and create a response. This is the mode we will be running in.
For this module we just return the LlamaChat_adapter.long_process function to signal that this is a long running process. This name is conventional.
def process(self, data: RequestData) -> JSON:
return self.long_process
Interesting note: When you return a Callable from process, the client that made the request to the CodeProject.AI Server won't actually get a Callable as a response. That would be weird and unhelpful. The ModuleRunner will note that a Callable is being returned and will pass back the command ID and module ID of the current request to the client, which the client can then use for making status calls related to this request.
long_process()
This is where the work actually gets done using the functionality of the llama_chat.py file. The long_process method makes a call to the Llama_chat.py code and passes stream=True to do_chat. This results in an Iterator of responses being returned, with each response being processed in a loop and added to our final result. At each iteration we check to see if we've been asked to cancel the operation. The cancel signal is in the self.cancelled class variable which is toggled in the cancel_command_task method (described below).
The client can poll for the accumulating results by sending get_command_status commands for this module to the server and display the reply property of the response. (described below).
def long_process(self, data: RequestData) -> JSON:
self.reply_text = ""
stop_reason = None
prompt: str = data.get_value("prompt")
max_tokens: int = data.get_int("max_tokens", 0)
temperature: float = data.get_float("temperature", 0.4)
try:
start_time = time.perf_counter()
completion = self.llama_chat.do_chat(prompt=prompt, max_tokens=max_tokens,
temperature=temperature, stream=True)
if completion:
try:
for output in completion:
if self.cancelled:
self.cancelled = False
stop_reason = "cancelled"
break
delta = output["choices"][0]["delta"]
if "content" in delta:
self.reply_text += delta["content"]
except StopIteration:
pass
inferenceMs : int = int((time.perf_counter() - start_time) * 1000)
if stop_reason is None:
stop_reason = "completed"
response = {
"success": True,
"reply": self.reply_text,
"stop_reason": stop_reason,
"processMs" : inferenceMs,
"inferenceMs" : inferenceMs
}
except Exception as ex:
self.report_error(ex, __file__)
response = { "success": False, "error": "Unable to generate text" }
return response
command_status()
We have a long_process method that is called when returned from process, but what we need is a way to view the results of this long process. Remember that we're accumulating the results of the chat completions being sent back into the self.reply_text variable, so in our command_status() function we will return what we've collected so far.
Calling command_status() is something the client app that sent the original chat command should do after sending the command. The call is made via the /v1/LlamaChat/get_command_status endpoint, which will result in the server sending a message to the module which will in turn result in command_status() being called and the result returned back to the client.
def command_status(self) -> JSON:
return {
"success": True,
"reply": self.reply_text
}
The client should (or could) then display 'reply', with each subsequent call (hopefully) resulting in a little more of the response from the LLM appearing.
cancel_command_task()
The cancel_command_task() is called when the server has received a cancel_command command from the server. This will happen whenever the server receives a v1/LlamaChat/cancel_command request. This function sets a flag which tells the long process to terminate. It also sets self.force_shutdown to False to tell the ModuleRunner base class that this module will gracefully terminate the long process and does not need to force terminate the background task.
def cancel_command_task(self):
self.cancelled = True
self.force_shutdown = False
main
Lastly, we need to start the asyncio loop for the LlamaChat_adapter if this file is executed from a Python command line.
if __name__ == "__main__":
LlamaChat_adapter().start_loop()
And that is all the Python code that is required to implement the module. There are a few standard files needed for the installation process and will be discussed in the next sections.
Writing the installation and setup
The process of installing and setting up a module requires a few files. These are used to build up the execution environment and to run the module. These files are described in this section.
Create the installation scripts
You need two install scripts for the module, install.bat for Windows and install.sh for Linux and MacOS. For this module, all these files do is download the LLM model file as part of the installation process to ensure that the module can function without a connection to the Internet. You can review the contents of these files in the source code in the GitHub repository.
Detailed information on creating these files can be found at CodeProject.AI Module creation: A full walkthrough in Python and Writing install scripts for CodeProject.AI Server.
Create the requirements.txt files
The requirements.txt files are used by the module setup process to install the Python packages required for the module. There can be variation of this file if different OS, architecture, and hardware require different package or package versions. See Python requirements.txt files and the source code for details of the variants. For this module the main requirements.txt file is:
#! Python3.7
huggingface_hub # Installing the huggingface hub
diskcache>=5.6.1 # Installing disckcache for Disk and file backed persistent cache
numpy>=1.20.0 # Installing NumPy, a package for scientific computing
# --extra-index-url https://jllllll.github.io/llama-cpp-python-cuBLAS-wheels/basic/cpu
# --extra-index-url https://jllllll.github.io/llama-cpp-python-cuBLAS-wheels/AVX/cpu
# --extra-index-url https://jllllll.github.io/llama-cpp-python-cuBLAS-wheels/AVX512/cpu
--extra-index-url=https://jllllll.github.io/llama-cpp-python-cuBLAS-wheels/AVX2/cpu
--prefer-binary
llama-cpp-python # Installing simple Python bindings for the llama.cpp library
# last line empty
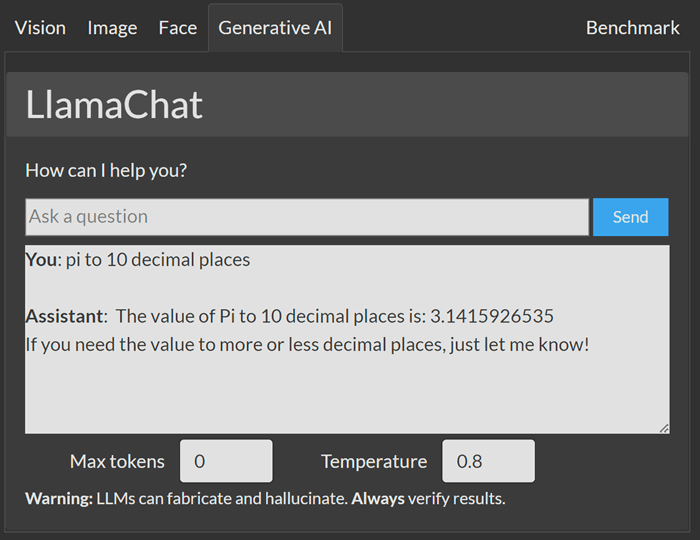
Create the CodeProject.AI Test page (and the Explorer UI)
The UI that is displayed in the CodeProject.AI Explorer is defined in an explore.html file. Below is a stripped-down version of what's in the repo to allow you to see the important parts.
When _MID_queryBtn is clicked, _MID_onLlamaChat is called which takes the prompt supplied by the user and posts it to the /v1/text/chat endpoint. The data returned by that call includes a, "thanks, we've started a long process now" message as well as the ID of the command and module that sent the request.
We then immediately start a loop which will poll, every 250ms, the module status. We do this by calling /v1/llama_chat/get_command_status, passing in the command ID and module ID we received from the call to process. With each response we display results.reply.
The upshot of this is you enter a prompt, click send, and within seconds the response starts accumulating in the results box. Pure magic.
<!DOCTYPE html>
<html lang="en" xmlns="http://www.w3.org/1999/xhtml">
<head>
...
</head>
<body class="dark-mode">
<form method="post" action="" enctype="multipart/form-data" id="myform">
<div class="form-group">
<label class="form-label text-end">How can I help you?</label>
<div class="input-group mt-1">
<textarea id="_MID_promptText"></textarea>
<input id="_MID_queryBtn" type="button" value="Send"
onclick="_MID_onLlamaChat(_MID_promptText.value, _MID_maxTokens.value, _MID_temperature.value)">
<input type="button" value="Stop" id="_MID_stopBtn"onclick="_MID_onLlamaStop()" />
</div>
</div>
<div class="mt-2">
<div id="_MID_answerText"></div>
</div>
<div class="mt-3">
<div id="results" name="results" </div>
</div>
</form>
<script type="text/javascript">
let chat = '';
let commandId = '';
async function _MID_onLlamaChat(prompt, maxTokens, temperature) {
if (!prompt) {
alert("No text was provided for Llama chat");
return;
}
let params = [
['prompt', prompt],
['max_tokens', maxTokens],
['temperature', temperature]
];
setResultsHtml("Sending prompt...");
let data = await submitRequest('text', 'chat', null, params)
if (data) {
_MID_answerText.innerHTML = "<div class='text-muted'>Answer will appear here...</div>";
commandId = data.commandId;
moduleId = data.moduleId;
params = [['commandId', commandId], ['moduleId', moduleId]];
let done = false;
while (!done) {
await delay(250);
let results = await submitRequest('LlamaChat', 'get_command_status', null, params);
if (results) {
if (results.success) {
done = results.commandStatus == "completed";
let html = "<b>You</b>: " + prompt + "<br><br><b>Assistant</b>: "
+ results.reply.replace(/[\u00A0-\u9999<>\&]/g, function(i) {
return '&#'+i.charCodeAt(0)+';';
});
}
_MID_answerText.innerHTML = html
}
}
else {
done = true;
}
}
}
}
}
async function _MID_onLlamaStop() {
let params = [['commandId', commandId], ['moduleId', 'LlamaChat']];
let result = await submitRequest('LlamaChat', 'cancel_command', null, params);
}
</script>
</div>
</body>
</html>
Conclusion
We have demonstrated that it is easy to create a module that performs complex and long running processes by wrapping existing example or library code and creating an adapter.
Your challenge is to now create or modify a module to support your specific needs. If you do, we encourage you to share it. CodeProject.AI Server is dedicated to helping build an AI community, and we'd be honoured if you'd be a part of it.
History
April 4, 2024: Initial release.

