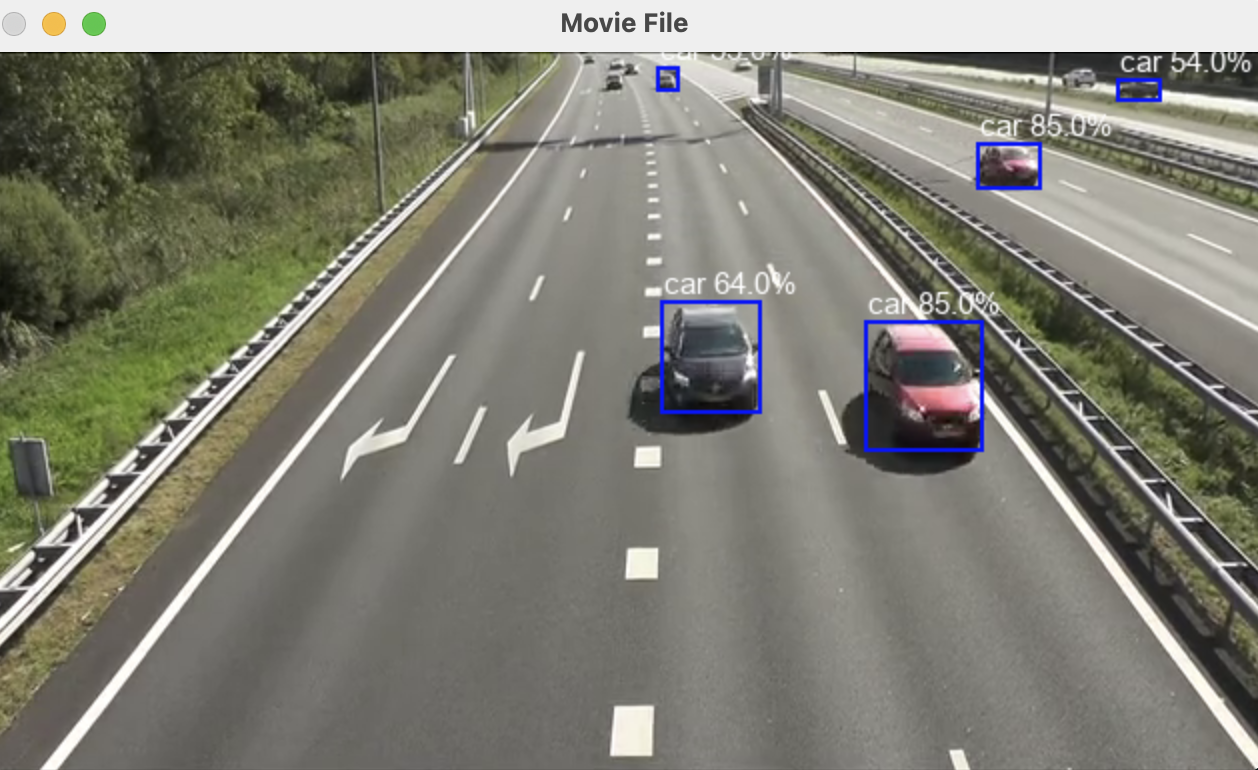
Introduction
A lot of attention is given to processing live webcam feeds in areas of object detection or face recognition. There are uses cases for processing video from saved or downloaded videos so let's do a very quick walkthrough of using CodeProject.AI Server to process a video clip.
For this we'll use Python, and specifically the OpenCV library due to its built in support for many things video. The goal is to load a video file, run it against an object detector, and generate a file containing objects and timestamps, as we as viewing the video itself with the detection bounding boxes overlaid.
Setup
This will be bare-bones so we can focus on using CodeProject.AI Server rather than focussing on tedious setup steps. We will be running the YOLOv5 6.2 Object Detection module within CodeProject.AI Server. This module provides decent performance, but most conveniently it runs in the shared Python virtual environment setup in the runtimes/ folder. We will shamelessly use this same venv ourselves.
All our code will run inside the CodeProject.AI Server codebase, with our demo sitting under the /demos/clients/Python/ObjectDetect folder in the video_process.py file.
To run this code, go to the /demos/clients/Python/ObjectDetect folder and run
..\..\..\..\src\runtimes\bin\windows\python39\venv\Scripts\python video_process.py
../../../../src/runtimes/bin/macos/python38/venv/bin/python video_process.py
To halt the program type "q" in the terminal from which you launched the file.
The Code
So how did we do it?
Below is minimal version of the code for opening a video file and sending to CodeProject.AI Server
vs = FileVideoStream(file_path).start()
with open("results,txt", 'w') as log_file:
while True:
if not vs.more():
break
frame = vs.read()
if frame is None:
break
image = Image.fromarray(frame)
image = do_detection(image, log_file)
frame = np.asarray(image)
if frame is not None:
frame = imutils.resize(frame, width = 640)
cv2.imshow("Movie File", frame)
vs.stop()
cv2.destroyAllWindows()
We open the video file using FileVideoStream, then iterate over the stream object until we run out of frames. Each frame is sent to a do_detection method which does the actual object detection. We've also opened a log file called "results.txt" which we pass to do_detection, which will log the items and locations detected in the image to this file.
def do_detection(image, log_file):
buf = io.BytesIO()
image.save(buf, format='PNG')
buf.seek(0)
with requests.Session() as session:
response = session.post(server_url + "vision/detection",
files={"image": ('image.png', buf, 'image/png') },
data={"min_confidence": 0.5}).json()
predictions = None
if response is not None and "predictions" in response:
predictions = response["predictions"]
if predictions is not None:
font = ImageFont.truetype("Arial.ttf", font_size)
draw = ImageDraw.Draw(image)
for object in predictions:
label = object["label"]
conf = object["confidence"]
y_max = int(object["y_max"])
y_min = int(object["y_min"])
x_max = int(object["x_max"])
x_min = int(object["x_min"])
if y_max < y_min:
temp = y_max
y_max = y_min
y_min = temp
if x_max < x_min:
temp = x_max
x_max = x_min
x_min = temp
draw.rectangle([(x_min, y_min), (x_max, y_max)], outline="red", width=line_width)
draw.text((x_min + padding, y_min - padding - font_size), f"{label} {round(conf*100.0,0)}%", font=font)
log_file.write(f"{object_info}: ({x_min}, {y_min}), ({x_max}, {y_max})\n")
return image
The only tricky parts are
- Extract frames from a video file
- Encode each frame correctly so it can be sent as a HTTP POST to the CodeProject.AI Server API
- Draw the bounding boxes and labels of detected objects onto the frame, and display each frame in turn
ALl the real grunt work has been done by CodeProject.AI Server in detecting the objects in each frame
Summing up
The techniques explained here are transferrable to many of the modules in CodeProject.AI Server: take some data, convert to a form suitable for a HTTP POST, make the API call, and then display the results. As long as you have the data to send a module that satisfies your need, you're good to go.

