1. Storing images within a database
Typically, images are saved in a database as a binary large object (BLOB). However, some prefer a more cautious approach, converting the image to Base64 encoding and storing it as a variable-length character string.
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
import org.springframework.web.multipart.MultipartFile;
import java.io.IOException;
@Service
public class ImageService {
@Autowired
private ImageRepository imageRepository;
public void saveImage(MultipartFile file) throws IOException {
ImageEntity imageEntity = new ImageEntity();
imageEntity.setImageData(file.getBytes());
imageRepository.save(imageEntity);
}
}
I made this mistake when I was new to the workforce. Storing images directly in a database is a bad idea because it can slow things down and cause a lot of headaches. Even though it seems like a good way to keep your images safe, it comes with some big problems.
The biggest issue is that it makes your database really big and slow. Databases aren't built for huge files like images, so it can make your app feel sluggish. Images take up a lot of space, and when you try to save or load them from the database, it can take forever.
Another problem is that it makes backups a pain. Because the image files are so big, it takes a lot longer to back up and restore your data.
2. Create an open-ended database connection
Back when I was new to programming, I'd create database connections left and right without a second thought. I didn't realize that there's a limit to everything. I can still recall a PHP script I wrote that looked something like this:
<?php
$servername = "localhost";
$username = "your_username";
$password = "your_password";
$dbname = "your_database";
$conn = new mysqli($servername, $username, $password, $dbname);
if ($conn->connect_error) {
die("Kết nối không thành công: " . $conn->connect_error);
}
$sql = "SELECT id, name FROM users";
$result = $conn->query($sql);
if ($result->num_rows > 0) {
while ($row = $result->fetch_assoc()) {
echo "ID: " . $row["id"]. " - Name: " . $row["name"]. "<br>";
}
} else {
echo "0 result";
}
?>
Failing to close database connections after use can lead to several serious issues that impact application performance and stability.
Database connections consume system resources, including memory and network resources. If left open, these resources are not released, resulting in resource leaks. This can degrade the performance of both the application and the database server.
Most database management systems employ connection pooling, limiting the number of concurrent connections that can be open. Unclosed connections can exhaust this pool, preventing new requests from connecting to the database and causing connection refusals.
With too many open connections, the database must manage multiple concurrent connections, which can degrade overall system performance. Query operations may become slower due to resource sharing among connections.
Furthermore, unclosed database connections can pose a security risk, especially if connection information is retained longer than necessary. Attackers can exploit open connections to perform unauthorized actions or take advantage of security vulnerabilities.
3. Randomly setting up the index
At first, I believed that Non-clustered indexes were a universal solution for boosting query performance. The speed gains I achieved were often dramatic, up to 30%. However, I eventually discovered that I had been naive in my approach and that indiscriminate use of these indexes wasn't always the best strategy.
The proliferation of indexes and the exponential growth of my data have resulted in a rapid expansion of my database, approaching a critical mass.
I can vividly recall the performance of my posts table. Initially, the API responsible for news crawling from external sources exhibited a sub-500 millisecond execution time. However, following a month of system operation and the ingestion of nearly 5GB of data, I encountered a significant performance degradation, with news insertions taking approximately 2 seconds to complete.
4. Select *
I’ve found that using SELECT * in SQL queries, while easy, can be problematic. Fetching every column from a table can result in unnecessary data transfer and performance issues.
Retrieving all columns with SELECT * can significantly degrade query performance due to increased data transfer. This is particularly problematic for large tables or remote databases.
The transmission of unnecessary data over the network can consume excessive bandwidth and increase latency. Furthermore, the lack of explicit column selection can reduce code clarity and maintainability.
5. Unreasonable database design
5.1 Storing JSON as data in a column.
The ability to store diverse data structures within a single JSON column has contributed to its widespread adoption in modern databases. However, the versatility of JSON comes with certain trade-offs, and directly storing it within database columns may not always be the most suitable approach.
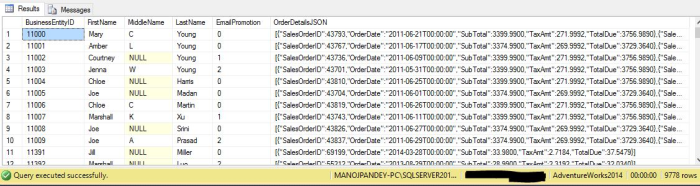
When storing data as JSON within a single column, searching or filtering for specific data becomes more challenging. Most database management systems do not support querying the JSON content without using special functions or indexes, which can degrade query performance.
Data analysis and reporting tools often have limited support for analyzing JSON data. This can make data aggregation and analysis complex and inefficient.
Maintaining data consistency and integrity can be more difficult when JSON data is stored in a single column. If the JSON structure changes, you will need to update or adjust your queries and code to accommodate these changes.
JSON data can include unnecessary or redundant information, leading to larger record sizes and increased storage requirements compared to traditional data storage formats.
While this may not be a problem for NoSQL databases, from my perspective, relational databases (RDBMS) should be designed based on relationships between entities, rather than relying on a more unstructured approach.
5.2 Poor Design (Violating 1NF, 2NF, 3NF)
1NF (First Normal Form): A table does not satisfy 1NF if it contains repeating groups or multi-valued attributes.
2NF (Second Normal Form): A table does not satisfy 2NF if it contains non-key attributes that are not fully functionally dependent on the primary key.
3NF (Third Normal Form):A table does not satisfy 3NF if it contains non-key attributes that are functionally dependent on other non-key attributes.
Suppose you have an orders table with columns order_id, product_name, and product_price. If an order has multiple products, you might repeat the product information in different rows, leading to inconsistencies and increasing the chances of errors when updating product information.
Solution:
1NF: Create an order_items table to store the products in an order, with order_id and product_id as the primary key.
2NF: Create a products table to hold product information and link it to the order_items table using product_id.
3NF: Ensure that the attributes in the order_items table are not dependent on non-key attributes.
5.3 Missing foreign keys
When foreign keys are not implemented, there is no mechanism to enforce referential integrity. This allows for the insertion of invalid data, such as referencing a record that does not exist in a related table.
Without foreign keys, it becomes difficult to track and manage relationships between different entities, leading to potential data loss and inconsistencies.
6. N+1 Problem
You guy can follow this topic to see more detail What is the most efficient way to write Hibernate queries to avoid performance bottlenecks like the N+1 issue?
7. Conclusion
Above are my experiences and mistakes in working with databases up until now. I hope that it will be helpful to you in some part of your programming.
If you have ever encountered any issues or noticed any errors that I've made, please feel free to comment below. Thank you and I look forward to seeing you again.

