In this article, we will look at the details of what Radix sort really does, and examine ways to implement it on GPUs with C++ AMP. The full source code is also provided for you to learn from, hack, and improve. Most of the logic is presented as diagrams and pseudo code.
Introduction
Sorting is a fundamental operation, crucial to many high performance algorithms that depend on it for partitioning and clustering of data. Radix sort is a non-comparative counting based sort that is linear in the number of elements to be sorted. This makes it especially attractive for algorithms that need to sort millions of elements. Today, we will look at the details of what Radix sort really does, and examine ways to implement it on GPUs with C++ AMP, an excellent cross platform GPU computing API from Microsoft. The full source code is also provided for you to learn from, hack, and improve. The knowledge of C++ AMP/CUDA/Any other GPU compute API is assumed, however, as most of the logic is presented as diagrams and pseudo code.
The Basic Algorithm
The sequential version of Radix sort is actually a very simple algorithm. It can be best expressed as follows:
for every element in array:
select a digit from most significant to least significant;
sort by the digit;
if digits are equal place elements in the order they appear.
The following diagram illustrates this concept:
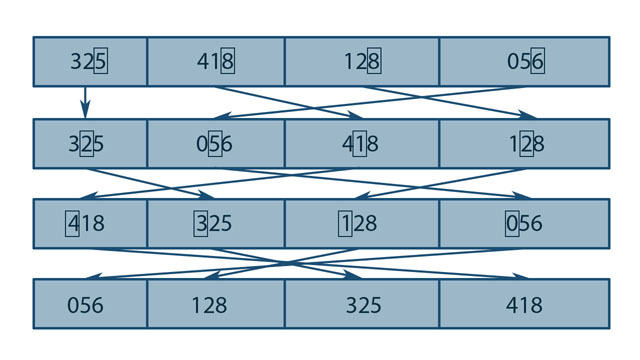
Figure: Basic logic of Radix sort
The diagram illustrates sorting using decimal digits. However, for unsigned integers, digits of any base can be used to sort the elements. Sorting using each bit as a digit (radix) would require 32 successive sorts, 2-bit radices would require 16 successive sorts, and so on. At this point, we still need to know how to sort by the selected digit. For this, we apply a prefix sum (a sort of cumulative counting) algorithm that is illustrated as follows for binary radices.
Prefix Sum Based Sorting
The Prefix Sum is a cumulative sum. Each element of the prefix sum of an array is the sum of all of its elements whose indices are less than the index being considered. The following diagram would hopefully make this clear:

Figure: Basic logic of Prefix Sum
Now how does this relate to sorting? The logic behind this is quite elegant. When we sort an array using 1-bit radices, we are essentially partitioning the input bit into 0s and 1s. The partitioning involves determining the cumulative count of the bits that were encountered before this one, and writing it to an output location given by that count. The algorithm is detailed below:
Step 1
Flag all the digits equal to 0 as 1, and then take the prefix sum of the flag bit. All the bits which are flagged with a 1 get written to the output array at position given by the prefix sum.
Step 2
Flag all digits equal to 1 as 1, and take prefix sum of the flag bit. All the bits that are flagged with a 1 get written to the output array at position given by the prefix sum.
GPU Implementation
So far, we have understood that Radix sort basically involves repeated prefix sums and scattered writes based on the values of the prefix sums. The algorithm spends bulk of its time calculating prefix sums. The rest are simply memory accesses. The key, therefore, is to figure out an efficient parallel algorithm for prefix sum.
The problem is that prefix sum is an inherently serial operation. There are data dependencies between every element and all its preceding elements. This problem can be somewhat alleviated by taking it step by step, adding 2 elements at every step. As usual, a picture is worth a thousand words:
Figure: Naïve implementation of prefix sum
The pseudo code for this algorithm is as follows:
For index in 0 .. log2(N):
For all k in parallel:
If k >= pow2(index)
x[k] = x[k] + x[k – pow2(index)]
Memory Bandwidth Requirements
You might have noticed that there might be performance problems with our naïve implementation when handling large arrays. Every step of the process requires access to the entire array in memory, and the lack of locality would bring even the best caches to their knees. Add to this the fact that most GPUs do not have automatic memory caching (some recent NVIDIA GPUs are an exception to this), and require you to manually manage the cache through tile static (shared memory in CUDA) accesses.
Let us refine our algorithm to be able to efficiently handle large arrays.
Divide and Conquer for Faster Prefix Sums
The solution is to handle the array in parts. Each part of the array would reside completely within a thread tile, and the prefix sum of this part would be calculated as discussed earlier. Memory access problems would go away, as we would be doing all of the work in ultra-fast tile static shared memory.
Once the partial prefix sums are calculated, they can be combined together using the sums that would be calculated in a previous step. The algorithm boils down to:
- Divide the array into tiles, find the sum of elements of each tile and store in an intermediate buffer. This can be done using a tile-wise partial reduction, using well known reduction algorithms. For the juicy details, refer to the code.
- Find the partial prefix sum of each tile, and combine using the sums that were calculated in the previous step.
Finally
That wraps up our discussion on the inner workings of radix sort. As you may remember, the sorting can be done using digits of any base. The code sorts integers using digits of 2-bits each, requiring 16 total sorting steps for 32 bit integers. Each sort step has to deal with 4 values (0, 1, 2, and 3), requiring 4 prefix sums. All 4 prefix sums are calculated in one step of the divide and conquer algorithm, reducing memory requirements even further.
Performance
The code was profiled on a GTX470 GPU, with a Q6600 CPU. Feel free to benchmark on your own configuration, and share the results:
You will notice that for very few keys (less than ~30,000 keys), the CPU performs better. However, for larger number of keys (more than ~ 1M), the GPU performs around 50x - 80x faster. Furthermore, the time taken by GPU sort seems to vary by very little up to about 1 million keys. The linear relationship becomes evident only after this point. This is because a large amount of parallel work is required to fully saturate the GPU, and before this point, any increase in work amount will have little to no impact on GPU performance.
Code
You can browse the code along with this article from the link at the top of this article, and also check it out on GitHub.

