Introduction
First thing – Using a threadpool efficiently is not everybody’s cup of tea – It’s not that you begin programming today and you will master this art tomorrow. Even biggies (or in our terminology they may like to call themselves a geek!) can also make mistakes there and the outcome is hell lot of threads that results in slow performance, bad responsiveness of system, deadlocks, live-locks and after all this sometimes you develop a desire to unplug your system and give it a bathing by dipping it in a water-tub. Hold on… somebody told me in this kind of situation count from FIVE to ONE slowly… YA; and you may repeat this for five times if that helps more - and after that, things will be under-control - believe me – it will be.
OK – so here I am not going to essay how we can use threading or perhaps multi-threading to our advantage; we
will talk a little on that but not delve deeper. What I am going to do here basically is – creating my own threadpool that will provide me a way to do things asynchronously using multiple threads. I will have control on maximum and minimum no of threads in the pool. Framework threadpool do the same thing and perhaps do so better than my pool – but that does not stop me from creating this one. My idea is to understand the threadpool from its core, the complexity it deals internally, the power it brings and finally the loop-wholes it exposes to bring your system down.
With my experience so far I have come across many developers who don’t understand the concept properly even though they might have used it many times. I am targeting mostly these sorts of fellows – just come along and try to find out what a thing it is after all.
So here is the list of things I am gonna walk through;
- Thread Background – a brief description
- Multi-Threading and the misconception around it
- Synchronization and critical section
- Object Pooling pattern for effective resource utilization
- Microsoft .NET framework provided Thread Pool
- The idea of creating a Custom threadpool and expectations
- Walk through code step-by-step
- Closing Note
Thread Background - a brief description
Well - it’s not a small thing to define but I am trying to cover conceptually everything being reasonable and brief also at the same time. Let’s see how it goes from here.
The main part of a computer is the central processing unit (CPU) which has processor/s, RAM, registers among few other things. When we start the system - OS gets loaded and runs in the processor. OS is written based on computer architecture like x-86 families. OS is the one that facilitates other application to load/run. It exposes API for using the resources that is available with system – like memory request, processor request etc. To execute a program processor time is required. With a single processor system there is effectively only one executing unit and so only one thing can run at any moment. Before windows in DOS era you could run only one thing at time. If a document is printing you just have to wait for that to finish. Worst thing – if some problem comes during that then just you have to re-boot the system. Windows 3.1 was also not a full OS. It was then an operating environment – means it provided a GUI environment for use where windows application such as word, excel and power point can run together. This was possible because of the new concept – A Process. Process is a mapping on
top of processor. Each application started opening under a Process. It was a big achievement in the sense that it provided Isolation. Now, the memory would get allocated separately to each process so as it was not shared it became impossible for a process to corrupt memory allocated to other process. Isolation was very much required for security reasons and to that it was great achievement.
Now the next hurdle was CPU. CPU is not something like memory that could be divided that way. If a process just executes an infinite loop then the other process has to wait forever. Even the OS couldn't help much with this. Until the process doesn't leave the CPU other process can’t actually do anything.
Something was required to divide the CPU somehow – and it came in form of a new approach - threading.
Thread is a window concept – it’s a virtualization of processor.
A Process is nothing but a running program - while running it has certain state at any moment of time. As it progresses the states keep changing. The state information is really necessary – without that there is no benefit of running a program. Like a method is called with certain arguments – then arguments are necessary for the method to compute/run properly. The argument would be loaded in registers or pushed into stack to be read easily by processor. The result again has to be written back to registers so that calling code can access that. This collaboration/coordination is defined by CPU architecture and it will be that way always. At any moment values - what all the register is loaded with and any other thing that a CPU relies on is what we are calling state. It is better
known as Context.
How then can virtualization help here?
The OS runs a scheduler whose job is to provide virtualization. Each program that begins (or we can say at start of a process) is given a thread – that thread behaves like a processor. Its entire context is loaded into physical registers then it starts progressing. Then quickly it stops – scheduler stops it - process actually does not exit – it just goes on on-hold mode. The scheduler then notes down the context and writes down to thread allocated memory (1 MB each thread gets as the default allocation for these purposes). It looks for other threads on halted state then gets the written context from thread local memory to registers and asks processor to start again. Quickly again this will be halted and in same round-robin fashion all the process threads will get to execute their respective tasks. CPU is so fast and this time slicing happens so rapidly that normally few active processes will never find that they are in waiting state any moment.
This is amazing development. We can send a huge document to print then ask a website to download a file for us then further ask the visual studio to build our huge code base and while all this happens I can go through my photo-album and can enjoy a song too all the same time. Great till this point.
Multi-threading and misconception around it
Till the time multiple processes are running single threaded it is just the benefit we are reaping. Synchronization problems will also not persist as processes works in different address spaces. It provided the much needed isolation – now if a process crashes for what so ever reason – the impact will be limited to that. Re-boot will not be required as other process will still get their slices of CPU time. This was the main reason why threading came in first place and it does this very well. This is multi-tasking. Multiple tasks are running in parallel.
Now as overtime expectation of users are increasing everyday and the processor speed also keeps on improving so the burden of making an application more responsive has come to software side – with single threaded approach much of the CPU time still goes on waste – bringing the overall utilization factor down. How it can be utilized in more efficient way? And thread was the answer.
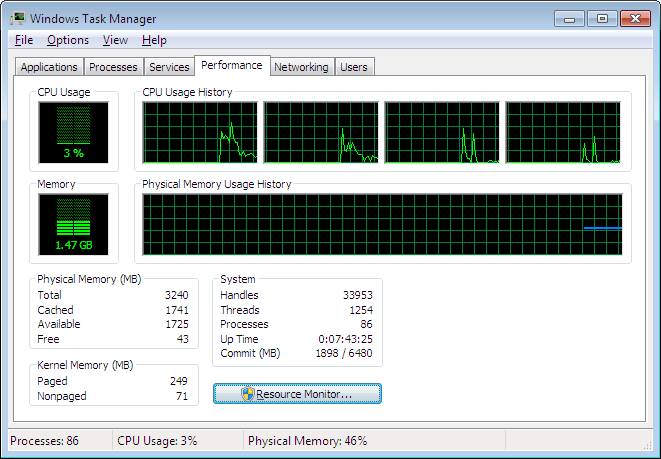
If there are five single threaded applications and one application that uses multiple thread then it will get more CPU time compare to other single threaded applications given slicing is even done among all threads. So being super intelligent I should spawn as many threads as possible so that my app will get more CPU time and things will get done quickly. And voila – suddenly everyone got intelligent and the result is that if you open visual studio, then word and excel and outlook as well – and then you open windows task manager and you can see here in screen-shot below taken from my box – here I have as many as 1254 threads and 86 processes running. 1.47 GB of RAM is in use. There is something seriously wrong about the way threads are spawned. With all these CPU utilization is still 3% only.
Now imagine a situation where a thread really needs CPU time for some extensive computations. As per slicing rule that will not get enough of it to do so because there are thousands of threads in active state. If nature of computation is synchronous then only one thread can execute that. In such cases multiple threads created by our app actually disturb CPU hungry threads and so overall execution time increases. The idea we started with getting more CPU for our app fails here drastically so getting mad behind creating thread actually kills and it kills in more ways than you think.
Creating multiple threads simply doesn't help increasing CPU utilization. It’s mainly how efficiently we design our application – that will. It introduces a lot of other complexity also. It doesn't mean that we should never go for it – we should - but only if we understand what we are doing and how it is going to help or waste existing resources.
In one line – creating multiple threads simply will not improve performance of an application – rather it will bring own efficiency of overall
system because it promotes inefficient utilization of resources.
Synchronization and critical section handling
Many times it makes sense to spawn a new thread for a dedicated time consuming task – like say doing a web-request. It takes UN-predictable time because of many factors involved in. the time on many occasion is enough for a end-user to lose patience and then overall experience doesn't leave a good impression. To change this scenario – we handover such UN-predictable tasks to another thread and by the time it
completes user can still do other things with UI.
The idea is good but it introduces a problem that needs our attention. Just to understand the issue let’s take an example where we download a feed for a company and store it in a temp file. Every time we do this we write on the existing file in append mode so that it doesn't get cluttered with many files in the memory. We have a form with a textbox where we supply company ticker such as IBM, YHOO and TRI. Then there is a button “upload”. It starts a web-request for that ticker and then the feed gets downloaded to the temp file on end-user system. As it is time consuming so we do this in a thread. Let’s say it takes 30 seconds in downloading and then another 20 seconds in writing to file.
User makes download request for IBM and within five seconds he makes another request for TRI. the situation can be represented with following diagram.

Sending two requests in parallel is OK. Web service will give result as expected. But now both will attempt to write to temp file. If such operation would be allowed we will get corrupt value written on the file because content written by one will mix with another feed. So file writing here need to happen synchronously. In other word while one thread updating the temp file – all others should wait for that to complete. The temp file here is the hot-spot or critical section. It’s the piece of resource in high demand by many potential competing threads. Access to critical section has to be in synchronous fashion even though thread doing so is running parallels.
For this there are constructs like Monitor and lock that makes sure only one thread enters critical section.
Before we proceed further in synchronization let’s take a turn and have a look on object pool pattern.
Object pool pattern for effective resource utilization
Starting with one note found on MSDN website related to this:
Doing Actual Work or Acquiring Resources
If you have a component that clients will use briefly and in rapid succession, where a significant portion of object use time is spent in acquiring resources or initializing prior to doing specific work for the client, chances are that writing your component to use object pooling will be a big win for you.<o:p>
There can be objects that take time in creation and initialization. If you are dealing with such resource too often then it will make sense to keep created object alive even after its dedicated task is done. If a new object is required again then instead of creating a new one just reset the existing object and hand it over. This pattern is targeted to improve performance by effective resource utilization. There are several practices for this – one of the popular among these can be summarized like following:
- Objects are costly in terms of creation time so better keep it ready for usage in advance to some limit - the minimum limit.
- Have pool – List where ready objects will be available for use always.
- There should be an upper limit of objects in pool – so that it doesn’t grow beyond certain limit and introduces other problem associated with it.
Set the maximum limit.
- Pool should be freed or should drop to minimum level in case objects are not in use for some time.
- Monitor the pool performance and re-size accordingly.
These are very basic points for creating an object pool – the pattern is simple and sometimes very effective.
Framework provided threadpool in .NET
As threads are costly to create – it made a lot of sense to have a pool for it. On the other hand it will guarantee that beyond a certain limitation it won’t grow.
The usage is so common that instead of developers doing this Microsoft itself created a threadpool class under
System.Threading namespace which can be utilized for doing asynchronous operation. It is a static class and exposes following methods among few others.
public static void GetMaxThreads(out int workerThreads, out int completionPortThreads);
public static void GetMinThreads(out int workerThreads, out int completionPortThreads);
public static bool QueueUserWorkItem(WaitCallback callBack);
public static bool QueueUserWorkItem(WaitCallback callBack, object state);
public static bool SetMaxThreads(int workerThreads, int completionPortThreads);
public static bool SetMinThreads(int workerThreads, int completionPortThreads);
WaitCallback is a delegate similar to ParameterizedThreadStart:
public delegate void WaitCallback(object state);
public delegate void ParameterizedThreadStart(object obj);
Here we see methods for setting upper and lower limit. We should leave this decision to framework because that can set it properly depending upon system parameters. We have the
QueUserWorkItem method that takes a task of WaitCallback type. This is the entrance point for a user task in the managed threadpool. It will get called when a thread is available in the pool in Free State.
Here instead of creating a thread we would be handing over the task to the threadpool which will execute that by a new or available free thread at a later time on best effort basis. And the delegate used is similar to the one we use
while delegating a task to thread using
ThreadStart duo. It is a very useful class and framework itself uses this for the Asynchronous callback pattern that it provides with
BeginInvoke and
EndInvoke family of methods available with Delegate and few other classes.
The idea of creating a Custom Thread Pool and expectations from it
Tons of information and tutorials are available online around Threadpool. Let’s not go deeper in that at this moment – instead we will create our own Custom-Thread-Pool with minimum set of things for our demo. We will
walk through the internal complexity it will bring. Some of these are related to object pool pattern then some related to synchronization. We will see as it comes.
Then going little further – we will provide a feature to cancel a task; here also there will be some intricacies. We will also provide a way to get callback notification on completion of a task. It’s not necessary as user can achieve that using lambda expression easily – but we will do that just to get better understanding. So here is the list of items.
- Create a custom thread pool with required variables/constants set.
- Define public interface for the threadpool with which it can be used.
- Expose a way for callback notification.
- Provide a way for cancelling an already requested task.
- Expectation is - that it will not maintain more than the MIN limit if threads are not busy executing task.
- It will not create more than the MAX limit of threads in the pool.
- One more feature we will implement – cancelling a task after it takes more than expected execution time if we mark
that task as simple task.
One more note – I am going to have singleton implementation of my pool instead of making it static – it’s my preferred approach. I haven’t done much analysis whether
static or singleton would be better;
Code walk-through step-by-step
Creating the singleton custom thread pool and defining few constants inside:
public class CustomThreadPool
{
private const int MAX = 8;
private const int MIN = 3;
private const int MIN_WAIT = 10;
private const int MAX_WAIT = 15000;
private const int CLEANUP_INTERVAL = 60000;
private const int SCHEDULING_INTERVAL = 10;
private static readonly CustomThreadPool _instance = new CustomThreadPool();
private CustomThreadPool() {
InitializeThreadPool();
}
public static CustomThreadPool Instance
{
get
{
return _instance;
}
}
private void InitializeThreadPool() {
}
}
Now I am going to define basic types to for our communication with the pool
public delegate void UserTask();
public class ClientHandle
{
public Guid ID;
public bool IsSimpleTask = false;
}
public class TaskStatus
{
public bool Success = true;
public Exception InnerException = null;
}
UserTask is a void delegate which will represent user task to be executed by threadpool thread. It is similar to Action provided by framework. Using lambda expression
it is now possible to encapsulate any method call within this UserTask. we will see this when we start using this threadpool.
Now the next thing is the public interface of the threadpool. Adding these public methods to
CustomThreadPool class.
public ClientHandle QueueUserTask(UserTask task, Action<TaskStatus> callback)
{
throw new Exception("not implemented yet.");
}
public static void CancelUserTask(ClientHandle handle)
{
}
Adding few private nested classes to be used internally by our threadpool:
enum TaskState
{
notstarted,
processing,
completed,
aborted
}
class TaskHandle
{
public ClientHandle Token;
public UserTask task;
public Action<TaskStatus> callback;
}
class TaskItem
{
public TaskHandle taskHandle;
public Thread handler;
public TaskState taskState = TaskState.notstarted;
public DateTime startTime = DateTime.MaxValue;
}
Now we must create the Queue for UserTask and a threadpool. we are also adding some initialization code:-
private Queue<TaskHandle> ReadyQueue = null;
private List<TaskItem> Pool = null;
private Thread taskScheduler = null;
private void InitializeThreadPool()
{
ReadyQueue = new Queue<TaskHandle>();
Pool = new List<TaskItem>();
taskScheduler = new Thread(() =>
{
});
taskScheduler.Start();
}
The important thing to note here is taskScheduler. This is a additional thread which will be running throughout the life cycle of threadpool.
Its job is to monitor UserTask in queue and take them for execution as soon as possible by any free thread. Its responsibility is also to force Minimum and Maximum limits.
Do cleanup activity on times. Its the master thread that owns the responsibility of the whole poll functionality.
Now let's implement this Initialization with near-complete algorithm.
private void InitializeThreadPool()
{
ReadyQueue = new Queue<TaskHandle>();
Pool = new List<TaskItem>();
InitPoolWithMinCapacity();
DateTime LastCleanup = DateTime.Now;
taskScheduler = new Thread(() =>
{
do
{
while (ReadyQueue.Count > 0 && ReadyQueue.Peek().task == null)
ReadyQueue.Dequeue();
int itemCount = ReadyQueue.Count;
for (int i = 0; i < itemCount; i++)
{
TaskHandle readyItem = ReadyQueue.Peek();
bool Added = false;
foreach (TaskItem ti in Pool)
{
if (ti.taskState == TaskState.completed)
{
ti.taskHandle = readyItem;
ti.taskState = TaskState.notstarted;
Added = true;
ReadyQueue.Dequeue();
break;
}
}
if (!Added && Pool.Count < MAX)
{
TaskItem ti = new TaskItem() { taskState = TaskState.notstarted };
ti.taskHandle = readyItem;
AddTaskToPool(ti);
Added = true;
ReadyQueue.Dequeue();
}
if (!Added) break;
}
if ((DateTime.Now - LastCleanup) > TimeSpan.FromMilliseconds(CLEANUP_INTERVAL))
{
CleanupPool();
LastCleanup = DateTime.Now;
}
else
{
Thread.Yield();
Thread.Sleep(SCHEDULING_INTERVAL);
}
} while (true);
});
taskScheduler.Priority = ThreadPriority.AboveNormal;
taskScheduler.Start();
}
private void InitPoolWithMinCapacity()
{
for (int i = 0; i <= MIN; i++)
{
TaskItem ti = new TaskItem() { taskState = TaskState.notstarted };
ti.taskHandle = new TaskHandle() { task = () => { } };
ti.taskHandle.callback = (taskStatus) => { };
ti.taskHandle.Token = new ClientHandle() { ID = Guid.NewGuid() };
AddTaskToPool(ti);
}
}
private void AddTaskToPool(TaskItem taskItem)
{
taskItem.handler = new Thread(() =>
{
do
{
bool Enter = false;
if (taskItem.taskState == TaskState.aborted) break;
if (taskItem.taskState == TaskState.notstarted)
{
taskItem.taskState = TaskState.processing;
taskItem.startTime = DateTime.Now;
Enter = true;
}
if (Enter)
{
TaskStatus taskStatus = new TaskStatus();
try
{
taskItem.taskHandle.task.Invoke();
taskStatus.Success = true;
}
catch (Exception ex)
{
taskStatus.Success = false;
taskStatus.InnerException = ex;
}
if (taskItem.taskHandle.callback != null && taskItem.taskState != TaskState.aborted)
{
try
{
taskItem.taskState = TaskState.completed;
taskItem.startTime = DateTime.MaxValue;
taskItem.taskHandle.callback(taskStatus);
}
catch
{
}
}
}
Thread.Yield(); Thread.Sleep(MIN_WAIT);
} while (true);
});
taskItem.handler.Start();
Pool.Add(taskItem);
}
private void CleanupPool()
{
throw new NotImplementedException();
}
Let's implement the QueueUserTask also:
public ClientHandle QueueUserTask(UserTask task, Action<taskstatus> callback)
{
TaskHandle th = new TaskHandle()
{
task = task,
Token = new ClientHandle()
{
ID = Guid.NewGuid()
},
callback = callback
};
ReadyQueue.Enqueue(th);
return th.Token;
}
This implementation is all fine - however we have omitted one important thing; we have not taken care of synchronization.
Here we have things that are shared among multiple resources like the ReadyQueue. Caller can add an Item and the scheduler same time can try to Dequeue that.
In such cases the result will be unpredictable.
So it the first thing now to identify resources that are shared among threads; define private synchronization
objects to be used for locking such resource. In case of multiple locks need to avoid constructs that can lead to deadlock situation.
And also user-task must not hold any lock defined inside Pool - because in that case the Pool can be stalled by any Task for any amount of time; so this has to be prevented.
Instead of explaining each line of code I am giving the full implementation here hoping it is self explanatory.
private object syncLock = new object();
private object criticalLock = new object();
public ClientHandle QueueUserTask(UserTask task, Action<taskstatus> callback)
{
TaskHandle th = new TaskHandle()
{
task = task,
Token = new ClientHandle()
{
ID = Guid.NewGuid()
},
callback = callback
};
lock (syncLock)
{
ReadyQueue.Enqueue(th);
}
return th.Token;
}
Add Task To Pool-
private void AddTaskToPool(TaskItem taskItem)
{
taskItem.handler = new Thread(() =>
{
do
{
bool Enter = false;
lock (taskItem)
{
if (taskItem.taskState == TaskState.aborted) break;
if (taskItem.taskState == TaskState.notstarted)
{
taskItem.taskState = TaskState.processing;
taskItem.startTime = DateTime.Now;
Enter = true;
}
}
if (Enter)
{
TaskStatus taskStatus = new TaskStatus();
try
{
taskItem.taskHandle.task.Invoke();
taskStatus.Success = true;
}
catch (Exception ex)
{
taskStatus.Success = false;
taskStatus.InnerException = ex;
}
lock (taskItem)
{
if (taskItem.taskHandle.callback != null && taskItem.taskState != TaskState.aborted)
{
try
{
taskItem.taskState = TaskState.completed;
taskItem.startTime = DateTime.MaxValue;
taskItem.taskHandle.callback(taskStatus);
}
catch
{
}
}
}
}
Thread.Yield(); Thread.Sleep(MIN_WAIT);
} while (true);
});
taskItem.handler.Start();
lock (criticalLock)
{
Pool.Add(taskItem);
}
}
Initialize Thread Pool -
private void InitializeThreadPool()
{
ReadyQueue = new Queue<TaskHandle>();
Pool = new List<TaskItem>();
InitPoolWithMinCapacity();
DateTime LastCleanup = DateTime.Now;
taskScheduler = new Thread(() =>
{
do
{
lock (syncLock)
{
while (ReadyQueue.Count > 0 && ReadyQueue.Peek().task == null)
ReadyQueue.Dequeue();
int itemCount = ReadyQueue.Count;
for (int i = 0; i < itemCount; i++)
{
TaskHandle readyItem = ReadyQueue.Peek();
bool Added = false;
lock (criticalLock)
{
foreach (TaskItem ti in Pool)
{
lock (ti)
{
if (ti.taskState == TaskState.completed)
{
ti.taskHandle = readyItem;
ti.taskState = TaskState.notstarted;
Added = true;
ReadyQueue.Dequeue();
break;
}
}
}
if (!Added && Pool.Count < MAX)
{
TaskItem ti = new TaskItem() { taskState = TaskState.notstarted };
ti.taskHandle = readyItem;
AddTaskToPool(ti);
Added = true;
ReadyQueue.Dequeue();
}
}
if (!Added) break;
}
}
if ((DateTime.Now - LastCleanup) > TimeSpan.FromMilliseconds(CLEANUP_INTERVAL))
{
CleanupPool();
LastCleanup = DateTime.Now;
}
else
{
Thread.Yield();
Thread.Sleep(SCHEDULING_INTERVAL);
}
} while (true);
});
taskScheduler.Priority = ThreadPriority.AboveNormal;
taskScheduler.Start();
}
Cancel User Task -
public static void CancelUserTask(ClientHandle clientToken)
{
lock (Instance.syncLock)
{
var thandle = Instance.ReadyQueue.FirstOrDefault((th) => th.Token.ID == clientToken.ID);
if (thandle != null)
{
thandle.task = null;
thandle.callback = null;
thandle.Token = null;
}
else
{
int itemCount = Instance.ReadyQueue.Count;
TaskItem taskItem = null;
lock (Instance.criticalLock)
{
taskItem = Instance.Pool.FirstOrDefault(task => task.taskHandle.Token.ID == clientToken.ID);
}
if (taskItem != null)
{
lock (taskItem)
{
if (taskItem.taskState != TaskState.completed)
{
taskItem.taskState = TaskState.aborted;
taskItem.taskHandle.callback = null;
}
if (taskItem.taskState == TaskState.aborted)
{
try
{
taskItem.handler.Abort();
taskItem.handler.Priority = ThreadPriority.BelowNormal;
taskItem.handler.IsBackground = true;
}
catch { }
}
}
}
}
}
}
Cleanup Pool:
private void CleanupPool()
{
List<TaskItem> filteredTask = null;
lock (criticalLock)
{
filteredTask = Pool.Where(ti => ti.taskHandle.Token.IsSimpleTask == true &&
(DateTime.Now - ti.startTime) > TimeSpan.FromMilliseconds(MAX_WAIT)).ToList();
}
foreach (var taskItem in filteredTask)
{
CancelUserTask(taskItem.taskHandle.Token);
}
lock (criticalLock)
{
filteredTask = Pool.Where(ti => ti.taskState == TaskState.aborted).ToList();
foreach (var taskItem in filteredTask)
{
try
{
taskItem.handler.Abort();
taskItem.handler.Priority = ThreadPriority.Lowest;
taskItem.handler.IsBackground = true;
}
catch { }
Pool.Remove(taskItem);
}
int total = Pool.Count;
if (total >= MIN)
{
filteredTask = Pool.Where(ti => ti.taskState == TaskState.completed).ToList();
foreach (var taskItem in filteredTask)
{
taskItem.handler.Priority = ThreadPriority.AboveNormal;
taskItem.taskState = TaskState.aborted;
Pool.Remove(taskItem);
total--;
if (total == MIN) break;
}
}
while (Pool.Count < MIN)
{
TaskItem ti = new TaskItem() { taskState = TaskState.notstarted };
ti.taskHandle = new TaskHandle() { task = () => { } };
ti.taskHandle.Token = new ClientHandle() { ID = Guid.NewGuid() };
ti.taskHandle.callback = (taskStatus) => { };
AddTaskToPool(ti);
}
}
}
Points to Note
See the CancelUserTask implementation. If task is still in Queue simply making that null works as when that will go for execution the scheduler will see the null
and will simply discard that. But in case that is already running then we are trying to abort the thread.
try
{
taskItem.handler.Abort();
taskItem.handler.Priority = ThreadPriority.BelowNormal;
taskItem.handler.IsBackground = true;
}
catch { }
Abort doesn't work as we have thought; the reason is if that thread is holding a lock then that lock won't get released at all and other threads will keep-on waiting for that;
this will hamper the system. So calling abort on a thread other that itself does not yield any result. Instead of that we then DE-prioritize the thread and make that background.
We are just making sure that this thread should not take much of CPU time. we remove that from the Pool. that thread will live to complete it's task but it won't disturb other threads much.
And upon completion of the task it will die it's natural death.
This logic is implemented in
AddTaskToPool.
lock (taskItem)
{
if (taskItem.taskState == TaskState.aborted) break;
if (taskItem.taskState == TaskState.notstarted)
{
taskItem.taskState = TaskState.processing;
taskItem.startTime = DateTime.Now;
Enter = true;
}
}
when the TaskState is aborted we are breaking the loop - so that immediately the thread will exit and release resources claimed by it.
Remember the IsSimpleTask property with ClientHandle class. if after Queuing a Task we change the
IsSimpleTask property to true then the CleanupPool
will Cancel such operation if they are taking too much time.
lock (criticalLock)
{
filteredTask = Pool.Where(ti => ti.taskHandle.Token.IsSimpleTask == true &&
(DateTime.Now - ti.startTime) > TimeSpan.FromMilliseconds(MAX_WAIT)).ToList();
}
foreach (var taskItem in filteredTask)
{
CancelUserTask(taskItem.taskHandle.Token);
}
This isn't a really interesting feature by the way as threads are not aborting here.
The locks - are they good enough or there's a loophole for deadlocks
Let's analyze it - Here are all the methods using lock and the sequence they are using it in.
| Method | Locks |
QueueUserTask |
SyncLock |
InitializeThreadPool
|
SyncLock->criticalLock->taskItem |
AddTaskToPool | taskItem,
criticalLock
|
CleanupPool
|
criticalLock, criticalLock |
CancelUserTask | syncLock->criticalLock, syncLock->taskItem
|
| |
There aren't any lock chain that would conflict with any other chain. Chain will conflict when lets say on thread gets
syncLock and another gets the criticalLock; now the first thread wants
criticalLock and the second one wants the syncLock. In this case there will be dead-lock - but fortunately we don't have it there.
But now look at the following line of code taken from
CleanupPool. It is under critical lock.
if (total >= MIN)
{
filteredTask = Pool.Where(ti => ti.taskState == TaskState.completed).ToList();
foreach (var taskItem in filteredTask)
{
taskItem.handler.Priority = ThreadPriority.AboveNormal;
taskItem.taskState = TaskState.aborted;
Pool.Remove(taskItem);
total--;
if (total == MIN) break;
}
}
when we do
Pool.where(ti => ti.taskState == taskState.completed).ToList()
then we aren't locking the taskItem. By the time this loop executes the state can be modified by a different thread. However it's not a problem here because we are doing so with completed and aborted state and we are only reading the state. we are not modifying that. These two state are final state here so logically it won't cause a issue; But these kind of things we tend to miss so easily and that can cause a potential dead-lock.
One more point here is regarding the calling of UserTask and callback notification. We should never do that when we have acquired any lock. because we don't know how much time user task is going to take and stalling a lock for that much time means blockage for threadpool. That's certainly not what we want.
The Test Application
With the attached code I have a simple windows app that opens message box on button press. This is just for testing the behavior and does not represent how
we should use it. Here you keep on pressing the button and it will keep opening new message boxes. After eight such boxes it will not open any more - however you can still
press the button. The request is getting queued. when we close an existing message box then a new one will come to life from the ReadyQueue. the code is simple.
It is passing a callback also which displays the status of executed task. Here is how the the threadpool getting called.
CustomThreadPool MyPool;
private void Form1_Load(object sender, EventArgs e)
{
MyPool = CustomThreadPool.Instance;
}
void showMessage(string message)
{
MessageBox.Show(message);
}
int x = 0;
private void btnStart_Click(object sender, EventArgs e)
{
x++;
int arg = x;
MyPool.QueueUserTask(() =>
{
showMessage(arg.ToString());
},
(ts) =>
{
showMessage(ts.Success.ToString());
});
} Closing Note
With multi-core processors all around it makes more sense these days to code intelligently to leverage that power.
While doing so we should not be blind to see the problems associated with such coding.
My effort here is to roam around the basics of threading and do some coding to understand situations that we need to care. this pool is far from complete but it provides a basic structure. I hope it helps struggling developers who falls in my category to better understand it and take care of issues that lies in the root. There's a lot of thing about threading that we should know and I have not covered many of those at all. Framework 4.0 onward we have a class like Task in System.Threading namespace. It's an abstraction over thread; it utilizes ThreadPool internally and then there is full TPL-Task Parallel Library. that should be the topic to cover immediately after it.
With that I am closing it here; Comments and suggestions are most welcome!
Thanks.

