Background
Typing a complete word in a search box is out. So if you are implementing a modern user friendly piece of software you will very probably need something like this:
Or this:
I have seen many questions about an efficient way of implementing a (prefix or infix) search over a key value pairs where keys are strings (for instance see: http://stackoverflow.com/questions/10472881/search-liststring-for-string-startswith).
So it depends:
- If your data source is a SQL or some other indexed database holding your data it makes sense to utilize it’s search capabilities and issue a query to find
matching records.
- If you have a small
amount of data, a linear scan will be probably the most efficient.
IEnumerable<KeyValuePair<string, T>> keyValuePairs;
...
var result = keyValuePairs.Select(pair => pair.Key.Contains(searchString));
- If you are searching in a large set of key value records you may need a special data structure to perform your
search efficiently.
Trie
There is a family of data structures referred as Trie. In this post I want to focus on C# implementations and usage of Trie data structures. If you want to find out more about the theory behind the data structure itself Google will be probably your best friend. In fact most of popular books on data structures and algorithms describe tries (see.: Advanced Data Structures by Peter Brass)
Implementation
The only working .NET implementation I found so far was this one: http://geekyisawesome.blogspot.de/2010/07/c-trie.html
Having some concerns about interface usability, implementation details and performance I have decided to implement it from scratch.
My small library contains a bunch of trie data structures all having the same interface:
public interface ITrie
{
IEnumerable Retrieve(string query);
void Add(string key, TValue value);
}
Trie – the simple trie, allows only prefix search, like .Where(s => s.StartsWith(searchString))SuffixTrie - allows also infix search, like .Where(s => s.Contains(searchString))PatriciaTrie – compressed trie, more compact, a bit more efficient during look-up, but a quite slower
during build-up.SuffixPatriciaTrie – the same as PatriciaTrie, also enabling infix search.ParallelTrie – very primitively implemented parallel data structure which allows adding data and retrieving results from different threads simultaneously.
Performance
Important: all diagrams are given in logarithmic scale on x-axis.
To answer the question about when to use trie vs. linear search better I’v
experimented with real data.
As you can see below using a trie data structure may already be reasonable after 10.000 records if you are expecting many queries on the same data set.
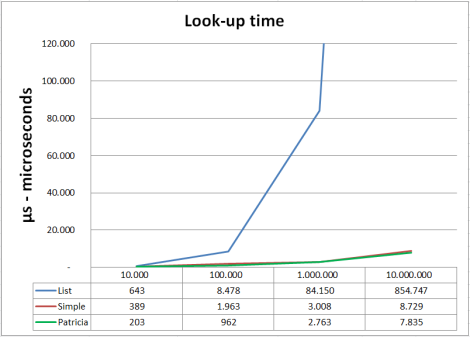
Look-up times on Patricia are slightly better, advantages of Patricia became more
noticeable if you work with strings having many repeating parts, like qualified names of classes in source code files, namespaces, variable names etc. So if you are indexing source code or something similar it makes sense to use patricia …
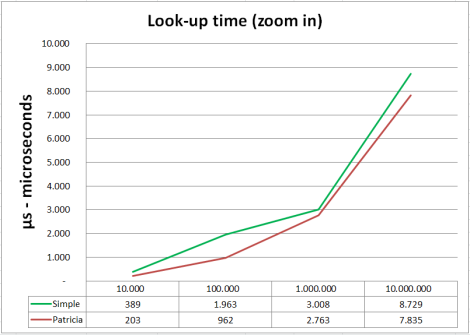
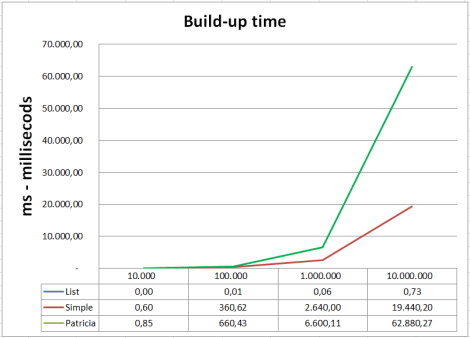
… even if the build-up time of patricia is higher compared to the normal trie.
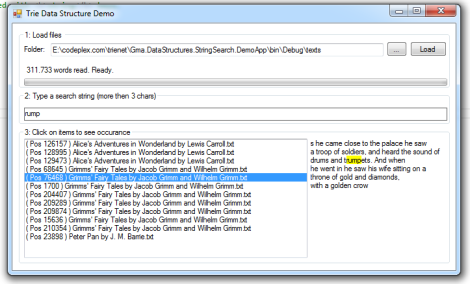
The Demo App
The app demonstrates indexing of large text files and look-up inside them. I have experimented with huge texts containing millions of words. Indexing took usually only several seconds and the look-up delay was still
unnoticeable for the user.