Please Note
If you use the keyword extraction software or dynamic
link library (dll) in your program or research, please indicate
that the part of paper and program cites the following paper.All the source
code in the article can be fully copy.
l Zhen YANG, Jianjun LEI, Kefeng FAN, Yingxu LAI. Keyword Extraction by Entropy Difference between the Intrinsic and Extrinsic Mode, Physica A: Statistical Mechanics and its Applications, 392 (2013), 4523-4531. http://dx.doi.org/10.1016/j.physa.2013.05.052
Introduction
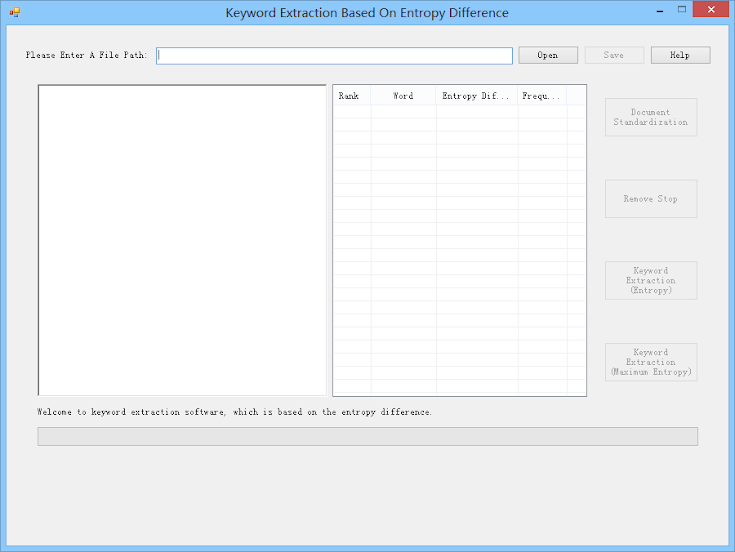
Figure1: software interface
In this software, we use a kind of entropy difference measure
to extract the keywords in a text. It's a simple measure, without any
a priori information and effectively extract the keywords in a single
text. Here we provide the dll which is developed by C++ and C#
language. We also provide keywords extraction software for you to use
which is developed by C#. By using this software, the only thing you
need to do is set the path of files to be done, and the software can help
you finish the rest of work. For English text, you should ensure that the
text is a standard format, or you can use the "pretreatment"
function in the software to format the text. Then, you can select one of
the methods-general entropy or Maximum Entropy to extract the keywords.
For Chinese text, in order to format the text, you
should follow the next steps. First, remove the punctuation and charts in
the text. Then, divide the sentences into a list of words. Two successive
words are separated by a space. Here we provide the function to remove the
punctuation and charts. You should ensure that the sentences in the text
has been divide into a list of words. Last, you can select one of the
methods----general entropy or Maximum Entropy to extract the keywords.
The Standardization text will be given in the part of usage. With these things, you can easily complete text keyword extraction work!
Background
One of the most significant different between human-written texts and monkeys typing is the general existence of meaningful topics in human written texts.keyword/relevant word extraction and ranking are the staring point for critical tasks like topic detection and tracking in written texts,and they are widely applied in information extraction,selection and retrieval.
Features of the Algorithm
As a new method in keyword extraction field, this
method has the following highlights :
• It’s
a new metric to evaluate and rank the relevance of words in a text.
• The
metric uses the Shannon’s entropy difference between the intrinsic and
extrinsic mode.
• This
work is a new result in keyword extraction and ranking.
• This
method is especially suitable for single documents of which there is
no a priori information available.
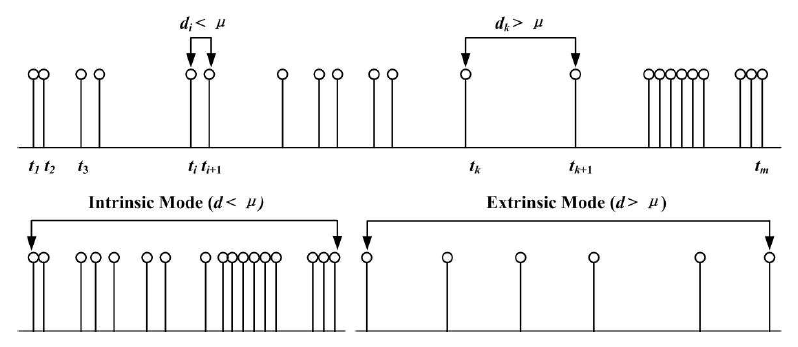
Figure 2: Intrinsic mode and extrinsic mode in positions of word-type occurrences in text.
Here's the brief introduction
of the principle of the algorithm, it can help you understand and use the
dll and software better. The
idea of intrinsic-extrinsic mode is based on the general idea that highly significant words tend to
be modulated by the writer’s intension,
while common words are essentially uniformly spread throughout a text. So the intrinsic mode denotes the
statistical properties of the appearance of a relevant word within a topic, i.e., the
statistical properties of
clustering within each topic. Meanwhile, the extrinsic mode captures the statistical properties of the disappearance of a
word clustering along a written
text and it characterizes the relationship between word clustering occurrence within a topic and an author’s written
style. As shown in FIG. 2. the distances between two words which is successive occurrences
is defined as di = ti+1 − ti. Ti is
the position of the word in the text. The arrival time difference di belongs to the intrinsic mode
if di <μ. In other words,
a given occurrence of the word is a part of an intrinsic mode if its local
separation is less than its mean waiting time. Let dI = {di|di <μ} be the union
set for all di <μas shown in
the bottom-left figure in FIG. 2. We found through experiments, that
the keyword which appears in the article presents the characteristics of
aggregates. so its intrinsic mode entropy is large while its extrinsic
mode entropy is small; the general words are evenly distributed in the
article, any two consecutive word spacing appears little change, so the
entropy difference between the intrinsic and extrinsic mode is small. In
this way, you can use the value E which is the entropy difference between
the intrinsic and extrinsic mode to extract keywords. In practice, in
order to eliminate the words randomly distributed and boundary conditions,
we use the Cc boundary
conditions and the normalized entropy difference Enor as the final indicators. If you want to learn
more details of this algorithm, please click here (http://dx.doi.org/10.1016/j.physa.2013.05.052)
to view the full paper.
Usage
Now
we will make a detailed description for the keyword extraction software
and use of dll. Here are two samples that we will use in numerous examples
to illustrate the performance of Enor metric, one is scientific book
in English, the other is a news report in Chinese.
Please
Note: To start the evaluation of the text, any punctuation symbols
were removed from the text, all words were changed to lowercase and then a
simple tokenization method based on whitespaces was applied. For
the Chinese text, the extra chinese word segmentation would be done at
first.
In the
keyword extraction software, we also provide you with a text
pre-processing function. After pre-processing, the standardized format of
text as follows:
Standardization
text input: can any body hear me oh am I talking to myself
my mind is running empty In the search for someone else cause tonight I'm
feeling like an astronaut……
Using
the software: First, please click the icon to start the
keyword extraction software. According to the flow shown in the following
figure, you can conduct a keyword extraction process.
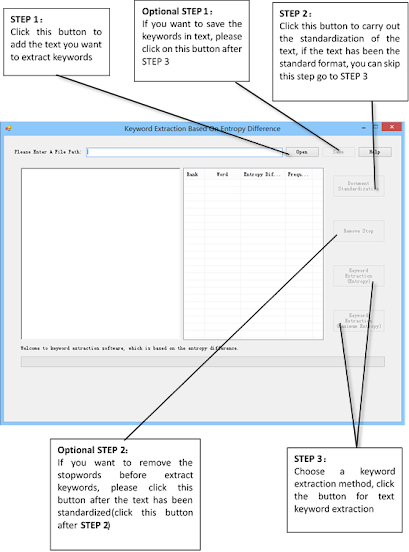
Using the dll:
The using of the dll we
provided here is fairly simple, as long as you are familiar with C++ or C#
dll calling, you will be able to easily use it.
Using the dll of C++:
Please note: Before
using the dll of the C++ version, please set you Visual Studio (VS2010) as
follows:
Open your Visual Studio, click
the menu project -> Properties ->Configuration Properties -> C/C++
-> Code Generation -> Runtime library, select Multi-threaded (/MD)
Here provides two
versions of the C++ dll, release version of dll and debug version of dll,
please select the corresponding dll for use. Such as, using the dll in the
"release" folder if you want to compile your code with the
solution configuration as “realse” method. We recommend to use the release
version because it's faster than the debug version.
Step1:
In the unzipped folder
find dll (in the c++ folder) and click the release folder. There will be
three file in the folder,as show in the following picture.Then,copy these
three files in your project and import the "Node.h" file in your
project directory

Step2:
Add the head file “Node.h” in
your code as follow,#include"Node.h"
Please note:The order of variables in the
structure in "Node.h" can not be changed! Now,we
introduce the structure NODE,as follow:
#include<vector>
using namespace std;
typedef struct
{
string word; double EDnor; int frequency; vector<int> t_loc; vector<int> d_list; }Node;
#pragma comment (lib,"Keyword_Extraction.lib")
extern Node* keyword_extra_entropy(string text,int&num); extern Node* keyword_extra_entropy_MAX(string text,int&num); The dll encapsulates two
functions: Node *keyword_extra_entropy (string text, int & num) and Node
*keyword_extra_entropy_MAX (string text, int & num). Respectively,
first function use general entropy method, while to second function use
maximum entropy method to calculate the maximum entropy. Both of the
functions have two inputs: string type - preprocessed text; int type -
return the size of the array. output: Node* type - the array of type Node,
the structure Node include the content which is introduced above.
Step3:
After following above
steps, you can call the function to get keywords, such as the following
code to showing TOP-10 Keywords:
int i;
int num;
Node *result;
result=keyword_extra_entropy_MAX(text,num);
for(i=0;i<10;i++)
cout<<endl<<result[i].word<<"==="<<result[i].EDnor<<"==="<<result[i].frequency; <span style="font-family: 'Times New Roman', serif; color: rgb(17, 17, 17); font-size: 14px;"> </span>
Example:
Now,
we select the book "Origin of Species" as an example, and
demonstrate the whole process of using the dll:
code:
#include<fstream>
#include<iostream>
#include<string>
#include"Node.h"
void main(){
filebuf *pbuf;
ifstream filestr;
long size;
char * buffer;
filestr.open ("D:\\test.txt",ios::binary); pbuf=filestr.rdbuf();
size=pbuf->pubseekoff
(0,ios::end,ios::in);
pbuf->pubseekpos (0,ios::in);
buffer=newchar[size+1];
pbuf->sgetn (buffer,size);
buffer[size]='\0';
filestr.close();
string text=buffer;
int num;
Node *result;
result=keyword_extra_entropy_MAX(text,num);
for(int i=0;i<num;i++)
cout<<endl<<result[i].word<<"==="<<result[i].EDnor<<"==="<<result[i].frequency;
system("pause");
} Using the dll of C# :
The dll of C#
version packages the entire class, so there contains more functions than
the dll of C++ version(including preprocessing functions, etc.). Please
refer to file "KEBOED interface documentation" to learn the
usage of C# dll.
The results of experiments:
For
the English example, here we select "Origin of Species" by using
our keyword extraction software, and select the "maximum
entropy" keyword extraction method,

For
the Chinese sample, we have chosen a news report on the network, the title
of this report is《让雷锋精神代代相传》. We use the keyword extraction software, and select
the "maximum entropy" keyword
extraction method and get the following result:

This
two samples text will also be given in the compressed package.
Conclusion
In summary, understanding the
complexity of human written text requires an appropriate analysis of the statistical distribution of the
words in texts. We find highly significant words tend to be modulated by the writing
writer’s intension, while common words are essentially uniformly spread in a text. The ideas of this
work can be applied to
any natural language with words clearly identified, without requiring any previous knowledge about semantics
or syntax.

