Introduction
It always starts with a phone call from an irate customer.
You're given a program that instead of running, crawls. You check the usual suspects: file IO, database access, even Web service calls: all this, to no avail.
You use your favorite profiling tool, which tells you that the culprit is a tiny little function that writes a long list of strings to a text file.
You improve this function by concatenating all the strings into a long one and writing it all in a single operation, instead of hundreds or thousands of writes of a few bytes each.
No cigar.
You measure how long it takes to write to the file. It's lightning fast. Then, you measure how long it takes to concatenate all the strings.
Ages.
What's going on? And how can you solve it?
You know that .NET programmers use a class named StringBuilder for this purpose. That's a starting point.
Background
If you google "C++ StringBuilder", you'll find quite a few answers. Some of them suggest using std::accumulate, which almost does what you need:
#include <iostream>// for std::cout, std::endl
#include <string> // for std::string
#include <vector> // for std::vector
#include <numeric> // for std::accumulate
int main()
{
using namespace std;
vector<string> vec = { "hello", " ", "world" };
string s = accumulate(vec.begin(), vec.end(), s);
cout << s << endl; return 0;
}
So far, so good: the problem begins when you have more than a few strings to concatenate, and memory reallocations start to pile up.
std::string provides the infrastructure for a solution, in function reserve(). It is meant for our purpose exactly: allocate once, concatenate at will.
String concatenation may hit performance ruthlessly with a heavy, blunt instrument. Having some old scars from the last time this particular beast bit me, I fired up Indigo (I wanted to play with some of the shiny new toys in C++11), and typed this partial implementation of a StringBuilder:
template <typename chr>
class StringBuilder {
typedef std::basic_string<chr> string_t;
typedef std::deque<string_t> container_t;
typedef typename string_t::size_type size_type;
container_t m_Data;
size_type m_totalSize;
void append(const string_t &src) {
m_Data.push_back(src);
m_totalSize += src.size();
}
StringBuilder(const StringBuilder &);
StringBuilder & operator = (const StringBuilder &);
public:
StringBuilder(const string_t &src) {
if (!src.empty()) {
m_Data.push_back(src);
}
m_totalSize = src.size();
}
StringBuilder() {
m_totalSize = 0;
}
StringBuilder & Append(const string_t &src) {
append(src);
return *this; }
template<class inputIterator>
StringBuilder & Add(const inputIterator &first, const inputIterator &afterLast) {
for (inputIterator f = first; f != afterLast; ++f) {
append(*f);
}
return *this; }
StringBuilder & AppendLine(const string_t &src) {
static chr lineFeed[] { 10, 0 }; m_Data.push_back(src + lineFeed);
m_totalSize += 1 + src.size();
return *this; }
StringBuilder & AppendLine() {
static chr lineFeed[] { 10, 0 };
m_Data.push_back(lineFeed);
++m_totalSize;
return *this; }
string_t ToString() const {
string_t result;
result.reserve(m_totalSize + 1);
for (auto iter = m_Data.begin(); iter != m_Data.end(); ++iter) {
result += *iter;
}
return result;
}
string_t Join(const string_t &delim) const {
if (delim.empty()) {
return ToString();
}
string_t result;
if (m_Data.empty()) {
return result;
}
size_type st = (delim.size() * (m_Data.size() - 1)) + m_totalSize + 1;
result.reserve(st);
struct adder {
string_t m_Joiner;
adder(const string_t &s): m_Joiner(s) {
}
string_t operator()(string_t &l, const string_t &r) {
l += m_Joiner;
l += r;
return l;
}
} adr(delim);
auto iter = m_Data.begin();
result += *iter;
return std::accumulate(++iter, m_Data.end(), result, adr);
}
};
The interesting bits
Function ToString() uses std::string::reserve() to minimize reallocations. Below you can see the results of a performance test.
Function join() uses std::accumulate(), with a custom functor that uses the fact that its first operand has already reserved memory.
You may ask: why std::deque instead of std::vector for StringBuilder::m_Data? It is common practice to use std::vector unless you have a good reason to use another container.
In the first version, I used list, based on these two:
- Strings will always be appended at the end of the container.
std::list allows doing this with no reallocations: since vectors are implemented using a continuous memory block, using one may generate memory reallocations. std::list is reasonably good for sequential access, and the only access that will be done on m_Data is sequential.
In the second version, after testing vector, list and deque, I kept deque, which was slightly faster.
Measuring performance
To test performance, I picked a page from Wikipedia, and hard-coded a vector of strings with part of the contents.
Then, I wrote two test functions. The first one used the standard function clock().
The second one used the more accurate Posix function clock_gettime(), and also tests StringBuilder::Join()
Finally, there is a main() function that calls all others, shows the results on the console, then executes the performance tests:
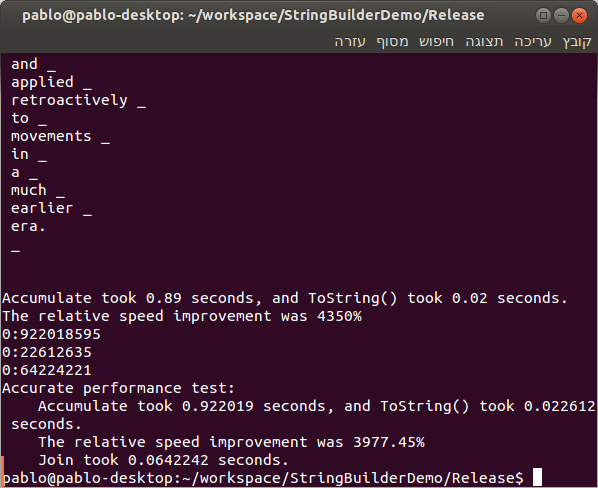
The picture above is the source of the title.
These tests were good enough for me; they showed that std::accumulate can be painfully slow when used with strings, and that std::string::reserve()
can save a lot of time. But there were significant flaws, as you can see in the comment
by Arash Partow below, so I rewrote them based on his suggestions.
I also loaded one of the vectors from a text file, instead of hard-coding it, and added some alternative solutions that were proposed in the comments. Here are the results:

The first conclusion is that everything that anyone thought about is better than std::accumulate by orders of magnitude.
The second conclusion is that std::basic_ostringstream is the fastest, so we should use it whenever possible.
(Not) using the code
Don't use the code.
Honest. I mean it. Don't use the code.
Before using the code, consider using ostringstream. As you can see in the comment by mrjeff below, and the test results above, it is much faster than the code for this article.
Another option suggested in the comments, by Oktalist, combines the simplicity of a one-liner with very good performance: see the result for lambda in the image above.
You may ask: if the code is not meant to be used, then what is it good for?
The point I'm trying to make is: don't use std::accumulate for strings.
You may want feel tempted to use the code if:
- You're writing code that will be maintained by programmers with C# experience, and you
want to provide a familiar interface. In that case, you should consider using an adapter to
std::basic_ostringstream, and an interface that resembles the StringBuilder. - You're writing code that will be converted to .NET in the near future, and you want to indicate a possible path. Again, consider encapsulating a
std::basic_ostringstream. - For some reason, you don't want to (or cannot)
#include <sstream>. A few years ago, some of the stream IO implementations were pretty heavy; if your compiler is a few years old, you may have no choice.
If, despite everything, you decide to use the code, just follow what is done in main(): create an instance of a StringBuilder, fill it using Append(), AppendLine() and Add(), then call ToString() to retrieve the result.
Like this:
int main() {
StringBuilder<char> ansi;
ansi.Append("Hello").Append(" ").AppendLine("World");
std::cout << ansi.ToString();
std::vector<std::wstring> cargoCult
{
L"A", L" cargo", L" cult", L" is", L" a",
L" kind", L" of", L" Melanesian",
L" millenarian", L" movement",
L" applied", L" retroactively", L" to", L" movements",
L" in", L" a", L" much", L" earlier", L" era.\n"
};
StringBuilder<wchar_t> wide;
wide.Add(cargoCult.begin(), cargoCult.end()).AppendLine();
std::wcout << wide.ToString() << std::endl;
std::wcout << wide.Join(L" _\n") << std::endl;
return 0;
}
Again: beware of std::accumulate when concatenating more than a handful of strings.
Now wait a minute!
You may ask: Are you trying to sell us premature optimization?
I'm not. I agree that premature optimization is bad. This optimization is not premature: it is timely. It is based on experience: I found myself wrestling this particular beast in the past.
Optimization based on experience (not stumbling twice on the same stone) is not premature.
When we optimize performance, the 'usual suspects' include disk I-O, network access (database, web services), and innermost loops; to these, we should add memory allocation, the Keyser Söze of bad performance.
Thanks
First of all, I'd like to thank Guy Rutenberg, for the code for accurate profiling in Linux.
I really want to thank all of you who commented, pointed at flaws and suggested alternatives. I was particularly touched (in the good way) by two members that posted their first comments under this article: thanks for sharing your knowledge.
Thanks to Wikipedia, for making the dream of 'information at your fingertips' come true.
Thank you for taking the time to read this article. I hope you enjoyed it: in any case, please share your opinion.
History
- 2013, September 3: First release.
- 2013, September 12: Improvements based on the suggestions in the comments below.

