Introduction
Displaying high volume data in a UI control in a flexible way often requires some loss of implementation generality if no performance degradation is to occur. However, this does not mean that a carefully designed generalised DataGrid cannot be specialised to handle reasonably high volumes of data while still performing in a way acceptable to users.
This article uses some advanced techniques to enhance the existing inbuilt WinForms and WPF DataGrids to handle 200,000+ rows and 100+ columns to:
- Provide user defined, parsed and fully compiled formulae involving any column(s);
- Live filtering in a similar manner;
- Live sorting via the usual column header interactions and also fully compiled;
- Ability to add/remove columns without rebinding;
- Ability to add/change row data rapidly;
- Ability to assign a unique Key and additional Metadata (like colours) to each row;
- Optimal recalculation strategies based on known row/column change sets.
Note that the same technique works to enhance the commercial WinForms DevExpress grid which, although it has adequate filtering/sorting/grouping/refresh support, is pretty poor at dealing with these other points.
Motivation
Excel spread sheets are ubiquitous in the Financial industry (as well as others) primarily because they allow business users to perform basic data analysis in a straightforward manner without engaging a pure technologist for every task.
When such projects are then shared between many users and become critical to those users, developers are often called in to "productise the spread sheet".
The result is a .NET application that revolves around a DataGrid, the choice of which is often driven by company policies and the (usually rapidly outdated) experiences of the developers involved.
The solution presented in this article was originally driven by the need to use such a commercial grid (WinForms DevExpress) while still providing acceptable performance for custom formulae, lots of columns and on demand data changes.
The aim here is to show that it is possible to use the DataGrids that come with .NET to satisfy the customisation and performance needs of particular business users without resorting to commercial alternatives and the complexities that often entails later in the project lifecycle.
The following shows WPF and WinForms sample programs with:
- Multi-column sorting (
Price + Quantity) Custom2 with an expression depending on Price, Quantity and Custom1 - Filtering the 200,000 down to 61,093 based on
Price and Custom1
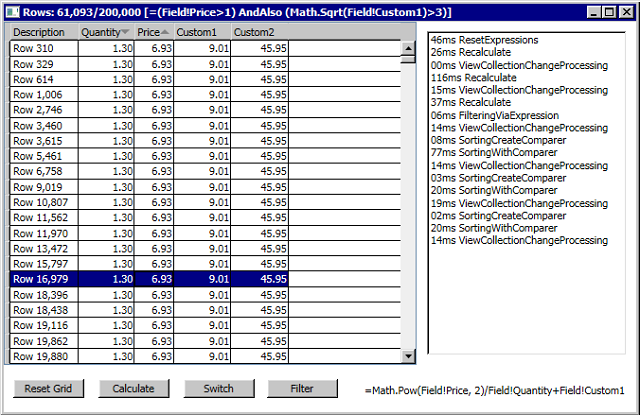

The final screen shot shows a basic Expression editor, in this case editing the complex Filter being applied to each row:
Performance
Note that (for sorting) this example is (deliberately) pathologically bad and so forms a good worst case scenario that is unlikely to occur frequently in production because a) data is not normally random and b) filtering expressions are unlikely to involve expensive calculations like the Sqrt used.
The timings in the screen shots above demonstrate that the time to parse the formula out of the text is often longer than compiling to IL, tracking dependencies and setting up the internal structures.
For example, it takes around 50ms (ResetExpressions) to do this parsing including recursive dependency tree creation and it takes around 30ms (Recalculate) to:
- Determine 200,000 random doubles, box and assign them to the
Price column - Similarly calculate and store
Custom1 as Quantity*Price - Similarly calculate and store
Custom2 as Price^2/Quantity+Custom1 - Finally calculate the filter as
Price>1 And Sqrt(Custom1)>3
However, it takes only around 5ms (SortingCreateComparer) to programmatically create and compile to IL the multi-column comparer and it takes around 20ms (SortingWithComparer) to actually perform the sorting on the post-filtered 61,242 rows and, a that number that would be considerably higher if there were no filter in affect.
Finally, the Switch button demonstrates how adding/removing/reshuffling columns can be done in a rapid manner without triggering lengthy grid setups, one of the goals of this solution.
Expressions
The expression syntax used is based on the SQL Server Reporting Services (SSRS) expressions as used by the Report Definition Language (RDL). It is actually a one-line version of Visual Basic .NET and was created for Report designers to set dynamic properties when creating reports.
Each external reference must be scoped by using '!' as the separator. For example, when mixing data from multiple sources this scope is useful to deal with duplicate names across those sources for a given column.
All expressions start with '=' to distinguish their use from raw text values in the general case.
In the sample projects attached, the scope has been fixed to the word "Field". For example, this performs the relevant arithmetic as expected:
=Field!Price*2+Field!Quantity/3.14152
Excel-like logic functions and inline operators are supported:
=IIf(Field!Price>2, Field!Quantity Mod 12, Field!Price/2)
Numerous functions are implemented outside of the grammar to allow for easy extension:
=Format(Today() + 5, "s")
Currently the above maps to DateTime.ToString("s") however the grammar itself supports such "Field Functions" like ToString() directly so this is straightforward to implement.
Parsing
The art of parsing has been studied extensively and is one of the areas of Software Engineering for which well established good algorithms are available. A reminder of the basic steps and terminology:
- Grammar - traditionally written in BNF
- Lexical analysis - traditionally taught using Flex
- Syntactical analysis - traditionally taught using YACC
- Abstract Syntax Tree - the result as an in-memory Tree structure (see AST)
- Processing of the AST - e.g. into IL
The best designed free parsing system in my opinion is the language-independent
GOLD Parser. It has the key advantage of creating a compiled grammar table (using the Builder) that can be embedded in a target application and passed to your choice of actual runtime implementation (the Engine):
The GOLD Parser system is extensively documented and there are numerous tools available for different stages of the process. Below is one of them showing part of the BNF grammar file describing the syntax of the expressions:
Loading the grammar file into the Builder allows subsequent entering of a test expression to show the "events" the parser runtime can expose. A partial expansion of the matching grammar lines is shown below:
Once the compiled grammar table is embedded into the Assembly an appropriate run-time is needed to use it. This comes down to personal preference but my choice was Calitha because of its event driven nature.
Linq's AST
The final piece of the puzzle is to re-use the existing Linq AST that is used to compile the familiar Linq-to-Object expressions at runtime. The Calitha parser events for errors, matching symbols and matching grammar rules are used as follows:
public Parser()
{
Errors = new List<string>();
FieldsNeeded = new SortedList<string,>(32);
ArrayParameter = Linq.Expression.Parameter(typeof(object[]), "Fields");
_Parser = _Reader.CreateNewParser();
_Parser.TrimReductions = true;
_Parser.StoreTokens = LALRParser.StoreTokensMode.NoUserObject;
_Parser.OnReduce += _Parser_OnReduce;
_Parser.OnTokenRead += _Parser_OnTokenRead;
_Parser.OnTokenError += _Parser_OnTokenError;
_Parser.OnParseError += _Parser_OnParseError;
}
OnTokenRead is used to handle the matching of the three symbols in the the grammar: strings, numbers and the identifiers. The simplest Linq Expression, a Constant, is used for the first two and by returning it from the handler it will be available in the UserObject property of all grammar rules:
static object RuleSymbolNumberHandler(Parser p, TerminalToken t)
{
if (t.Text.IndexOf('.') >= 0)
return Linq.Expression.Constant(double.Parse(t.Text, CultureInfo.InvariantCulture));
return Linq.Expression.Constant(int.Parse(t.Text, CultureInfo.InvariantCulture));
}
OnReduce is used to handle the matching of a grammar rule. The multiply rule below has three parts, the left expression, the multiply symbol and the right expression. Each one will have the UserObject set either by the symbol handler or by another grammar rule:
static object RuleExpressionTimesHandler(Parser p, NonterminalToken t)
{
var r = Helpers.Promote(t.Tokens[0].UserObject, t.Tokens[2].UserObject);
return Linq.Expression.Multiply(r[0], r[1]);
}
However it is essential that the type of a Linq Expression correctly matches whatever operator or function is being applied; this is not done automatically. A priority has to be applied during this type promotion and the one currently used is strings, DateTimes, doubles and then decimals.
There is no Linq casting expression, only 'As' and 'Convert'. Reverse engineering the latter reveals it handles all cases, casting if possible and boxing/unboxing if necessary. An example taken from the Helpers.Promote routine:
if (res[0].Type == typeof(double))
{
if (res[1].Type != typeof(double))
res[1] = Linq.Expression.Convert(res[1], typeof(double));
}
else if (res[1].Type == typeof(double))
{
if (res[0].Type != typeof(double))
res[0] = Linq.Expression.Convert(res[0], typeof(double));
}
Compiling
The call to the Calitha engine will return the root grammar token which will have its UserObject set to the corresponding Linq AST root:
var token = _Parser.Parse(input);
Debug.Assert(token != null || Errors.Count > 0);
if (token == null) return null;
var expression = (Linq.Expression)token.UserObject;
ResultType = expression.Type;
Description = expression.ToString();
A neat feature of such expressions prior to compilation is they have a Debug View showing the details, such as the complex filter expression used earlier:
Which just leaves the compile call that accepts the argument placeholder (ArrayParameter) and generates a DynamicMethod of the requisite type:
if (expression.Type.IsValueType)
expression = Linq.Expression.Convert(expression, typeof(object));
CompiledDelegate = (Func<object[], object>)
Linq.Expression.Lambda(expression, ArrayParameter).Compile();
The information like any fields this expression requires (passed in the ArrayParameter as object(s)) and the result type are available as fields off the Parser class.
The Row Comparer
These are implemented by programmatically creating the Linq AST and are actually more involved than the parsing approach just discussed. (Arguably these should be created using low level Reflection.Emit to avoid the verbosity of Linq however that topic is for a future article.)
Here is a flavour of the routine:
public Func<object[][], int, int, int> CreateComparer(params KeyValuePair<Type, bool>[] columns)
{
if (columns == null || columns.Length == 0) throw new ArgumentNullException("columns");
var arg0 = Linq.Expression.Parameter(typeof(object[][]), "columns");
var arg1 = Linq.Expression.Parameter(typeof(int), "firstRowIdx");
var arg2 = Linq.Expression.Parameter(typeof(int), "secondRowIdx");
var nullConstant = Linq.Expression.Constant(null);
var equalConstant = Linq.Expression.Constant(0);
var returnLabel = Linq.Expression.Label(typeof(int), "Result");
var returnGreater = Linq.Expression.Return(returnLabel,
Linq.Expression.Constant(1), returnLabel.Type);
var returnLess = Linq.Expression.Return(returnLabel,
Linq.Expression.Constant(-1), returnLabel.Type);
After arguments and constants are set up, the return labels for returning 1 for greater and -1 for less are created. Each column in the input then results in a Block of code as follows (see the source code for the full details):
var block = Linq.Expression.Block(
Linq.Expression.Label(thisLabel),
Linq.Expression.IfThen(bothValuesAreSameInstance, valuesAreEqual),
Linq.Expression.IfThen(firstValueIsNull, returnFirstIsLess),
Linq.Expression.IfThen(
secondValueIsNull, Linq.Expression.Return(returnLabel, returnFirstIsGreater)),
Linq.Expression.IfThen(
Linq.Expression.Equal(typedFirstValue, typedSecondValue), valuesAreEqual),
typedFinalCheck
);
And the final expression is compiled in the usual manner, referencing the arguments defined earlier:
var res = Linq.Expression.Lambda(Linq.Expression.Block(comparisons), arg0, arg1, arg2);
return (Func<object[][], int, int, int>)res.Compile();
The DataSource
The coordinator between Expressions, their required dependencies and the calculation order is the DataSource. Therefore this has to consist of a number of columns, some with only data and some with Expressions. Some of the functionality the DataSource provides is to make it useable by UI components and includes:
- Maintains a collection of DataColumns with bi-directional lookups by user-defined name or internal-binding name or index;
- Maintains a collection of DataRows to provide a bindable virtual row required by some DataGrids;
- Each Column can have associated user-defined Metadata;
- Each Row can have a unique Key as well as other user-defined Metadata and it is possible to lookup the row by it's Key;
- Columns contain a single object array for the data with conservative resizing and optimal delete-by-swapping;
- Rows contain only index and user-defined Metadata: they have pass-through bindable properties required by some DataGrids;
- A Filter enumerator is available to determine whether a row passes any assigned filter;
- Maintains the calculation order and coordinates state for any assigned Expressions including the filter;
- Allows for optimal Recalculation of specific changed columns or changed row-keys.
Fundamentally this is a lightweight version of the inbuilt DataTable but with data arranged in columns instead of in rows. The focus is on memory efficiency when frequently changing columns and rows rather than on adding new rows.
Basic Usage
This is a templated class designed to be used directly instead of hidden behind a binding:
public struct RowMetaData
{
public bool IsSpecial;
}
public class ColMetaData
{
public DataGridColumn Column;
}
readonly DataSource<RowMetaData, ColMetaData> _source
= new DataSource<RowMetaData, ColMetaData>();
readonly Parser _parser = new Parser();
The DataSource expects one type for each column (but it is only checked in Debug builds to avoid significant speed problems). Defining the first columns that go into it:
const int Rows = 10 * 1000;
static readonly KeyValuePair<string, Type>[] _InitialColumns = new[]
{
new KeyValuePair<string, Type>("Field.Description", typeof(string)),
new KeyValuePair<string, Type>("Field.Quantity", typeof(decimal)),
new KeyValuePair<string, Type>("Field.Price", typeof(decimal)),
new KeyValuePair<string, Type>("Field.Custom1", typeof(decimal)),
new KeyValuePair<string, Type>("Field.Custom2", typeof(double)),
};
_source.AppendColumns(_InitialColumns);
Filling in data is just a matter of creating the space all in one go for the rows (avoid doing this one-by-one as the resizing algorithm is only tuned for small increments) and then setting it:
_source.AddNewRows(Rows);
var col0 = _source.Columns[0];
var col1 = _source.Columns[1];
for (int i = 0; i < Rows; i++)
{
col0[i] = string.Format("Row {0:N0}", i);
col1[i] = 1.3m;
}
For real-world situations it would be normal to add specific row Metadata such as formatting and certainly the assignment of a Key. One example of the importance of a Key is when the user selects a range of rows in a DataGrid and you need to map these to the actual Business Objects that are associated with the DataRows in the DataSource to run some business process. Another might be just to gain access to the underlying raw typed data. Here I'm simply setting the eighth row to be "special" - in the samples it is used to change the background colour:
var custom = new RowMetaData { IsSpecial = true };
_source.SetMetaDataContainer(7, custom, key: null);
Expressions can now be assigned, noting carefully where '.' and '!' are used:
var exps = new List<KeyValuePair<string, string>>();
exps.Add(new KeyValuePair<string, string>("Field.Custom1", "=Field!Quantity*Field!Price"));
_source.ResetExpressions(_parser, exps);
And the final call must be to recalculate. Here all rows and columns will be processed and only ten Expression run-time exceptions will be allowed per column before the calculation is stopped:
var errorThreshold = 10;
_source.Recalculate(null , null , ref errorThreshold);
if (errorThreshold > 0)
{
MessageBox.Show(this,
string.Format("Over 10 errors occurred in {0:N0} expression(s)", errorThreshold),
"Possible error in expression(s)", MessageBoxButton.OK, MessageBoxImage.Stop);
}
If the user triggers some UI that means a different set of fields is needed then the optimal approach is as follows. Note that this will re-use any removed columns so the order may not be as specified. All expressions will be removed so you need ResetExpressions() and Recalculate() just like when first setting up the DataSource:
static readonly KeyValuePair<string, Type>[] _AlternateColumns = new[]
{
new KeyValuePair<string, Type>("Field.Custom2", typeof(double)),
new KeyValuePair<string, Type>("Field.Quantity", typeof(decimal)),
new KeyValuePair<string, Type>("Field.Price", typeof(decimal)),
new KeyValuePair<string, Type>("Field.Custom1", typeof(decimal)),
new KeyValuePair<string, Type>("Field.Text", typeof(string)),
new KeyValuePair<string, Type>("Field.Extra", typeof(string)),
};
_source.AdjustColumns(_AlternateColumns);
If some external event occurs and new data is available for some rows in some columns then an optimal refresh path can be used. Note carefully that the Price column is the only one that is marked for recalculation but all rows are still processed. If only a subset of rows had indeed been updated then the Keys could be provided to further decrease the recalculation time.
var price = _source.GetColumn("Field.Price");
var random = new Random();
for (int i = 0; i < Rows; i++)
{
if (i != 7) price[i] = (decimal)Math.Round(random.NextDouble() * 10, 2);
}
_source.Recalculate(new [] { price.Index }, null , ref errorThreshold);
Filters
An optional filter may be assigned - any expression that results in a boolean value may be used. The optimal solution is to use ResetExpressions() using the special name _source.ExpressionFilterName to pass in the filter along with any other Expressions:
string FilterExpression = "=Field!Price>1";
var exps = new List<KeyValuePair<string, string>>();
exps.Add(new KeyValuePair<string, string>("Field.Custom1", "=Field!Quantity*Field!Price"));
if (!string.IsNullOrEmpty(FilterExpression))
exps.Add(
new KeyValuePair<string, string>(_source.ExpressionFilterName, FilterExpression));
_source.ResetExpressions(_parser, exps);
However, the filter is the only Expression that may be added, modified or deleted directly and has it's own recalculation method:
_source.EditFilterExpression(_parser, FilterExpression);
_source.RecalculateFilter(null , ref errorThreshold);
Once a valid filter has been assigned and recalculation occurred, the results can be read as follows. Currently no indexed access is available but that is trivial to implement with the usual bit masking to index the ulong array used to optimally store the booleans:
if (_source.HasValidFilter)
{
foreach (var include in _source.FilterEnumerator())
{
if (include)
{
}
i++;
}
}
Boxing and Binding
Reverse engineering the inbuilt WPF DataGrid and the Winforms DevExpress DataGrid shows that not only is binding the only way to ensure all features are available but that they all rely on the basic .NET Reflection techniques - i.e. all value types are boxed. For these grids as well as the inbuilt Winforms DataGrid (in virtual mode) this boxing-via-Reflection occurs whenever new rows scroll into view.
This is one key reason why the DataSource stores data in object arrays, one per DataColumn and does not bother with more advanced typed approaches (the other reason is the ability to re-use the expensive object array when columns are changed).
Both the aforementioned DataGrids optimally bind to IBindingList and ITypedList implementations where a collection of rows with a fixed set of public properties is expected. Rebinding is a very expensive exercise since it is implemented as if a totally new column schema is being created even if only one column is changed.
It is essential when implementing these interfaces to act like a totally fixed size, static list that supports no notifications. This way, it is possible to support bulk updates, expressions, filtering and sorting in an optimal manner:
IBindingList methods and properties either return false or throw NotImplementedException - WPF requires quite a few
IList and ICollection members to be implemented including IndexOf and CopyTo if the default ListCollectionView is used (not recommended) - The inbuilt WinForms DataGrid and WinForms DevExpress DataGrid require minimal implementations
When binding, the DataSource appears as a list of DataRows and the properties provided by ITypedList all map down to column lookups. The key point to note here is that all properties are defined at compile time; this was primarily done to ensure a smooth development experience (when the Debug type checks inevitably fail) and also to keep the code more maintainable.
public class DataRow<R, C>
where R : struct
where C : new()
{
public struct MetaDataContainer<S> where S : struct
{
public Key Key;
public S Data;
}
private readonly DataSource<R, C> _source;
public readonly int RowIndex;
public object c00 { get { return _source[RowIndex, 0]; } }
public object c01 { get { return _source[RowIndex, 1]; } }
public object c02 { get { return _source[RowIndex, 2]; } }
public object c03 { get { return _source[RowIndex, 3]; } }
public object c04 { get { return _source[RowIndex, 4]; } }
public object c05 { get { return _source[RowIndex, 5]; } }
public object c06 { get { return _source[RowIndex, 6]; } }
public object c07 { get { return _source[RowIndex, 7]; } }
public object c08 { get { return _source[RowIndex, 8]; } }
public object c09 { get { return _source[RowIndex, 9]; } }
public object c10 { get { return _source[RowIndex, 10]; } }
public object c11 { get { return _source[RowIndex, 11]; } }
public object c12 { get { return _source[RowIndex, 12]; } }
Expressions in Practice
Taken on their own the DataSource and Expression parsing are reasonably straightforward; it is when they are combined that things get tricky:
- If the DataSource Metadata is being saved and reloaded then it is likely that the availability and types of columns used by Expressions may have changed;
- If an Expression compiles fine but at runtime throws exceptions (e.g. type mismatches) then this can make the UI unresponsive for a long time;
- A single Expression can depend upon other Expressions and so on leading to circular dependencies which hang the application;
- Any Expression could actually be a runtime constant so should only be calculated once.
State
Each column in the DataSource keeps track of the state of an an assigned Expression via the DataColumnExpression class which has these properties:
public readonly string Expression;
public string Error { get; internal set; }
public string Description { get; internal set; }
public readonly ISet<int> ColumnsNeeded;
public readonly int[] DelegateArguments;
public Func<object[], object> CompiledDelegate { get; protected set; }
public int LastErrorCount { get; internal set; }
In the current design, any re-ordering of columns immediately invalidates Expressions due to the ColumnsNeeded cache above. The creation of this class shows how the Parser, the other available fields and the mapping of field name to column index come together to initialise the Expression state and is worth examining in full:
internal DataColumnExpression(Parser parser, string expression,
IDictionary<string, Type> fields, Func<string, int> nameToIndexMapper)
{
Expression = expression;
HasNeverBeenCalculated = true;
if (Parse(parser, expression, fields))
{
Description = parser.Description;
if (parser.FieldsNeeded.Count > 0)
{
ColumnsNeeded = new HashSet<int>();
foreach (var pair in parser.FieldsNeeded)
{
ColumnsNeeded.Add(nameToIndexMapper(pair.Key));
}
DelegateArguments = new int[parser.FieldsNeeded.Count];
foreach (var pair in parser.FieldsNeeded)
DelegateArguments[pair.Value] = nameToIndexMapper(pair.Key);
}
}
else
{
Error = string.Join("\n", parser.Errors);
}
}
Creation
The ResetExpressions() function forms the core of the integration of Expressions within the DataSource. The parsing, compilation and assignment of the expressions looks roughly like this (see source for full details):
foreach (var pair in expressions)
{
var idx = _LookupColumnByName[pair.Key];
_ColumnsWithExpressions.Add(idx);
var col = _Columns[idx];
var exp = new DataColumnExpression(parser, pair.Value, dict,
name => _LookupColumnByName[name]);
if (exp.Error == null)
{
col.ResetTypeOnly(parser.ResultType);
dict[pair.Key] = parser.ResultType;
}
col.Expression = exp;
if (exp.Error == null && exp.ColumnsNeeded == null)
{
processed.Add(idx);
object constant = null;
try
{
constant = exp.CompiledDelegate(null);
exp.HasNeverBeenCalculated = false;
}
catch (Exception ex)
{
exp.Error = ex.Message;
continue;
}
col.SetConstantValue(constant);
}
}
Determining Order
Once all expressions have been parsed, their dependencies recorded and all constant expressions processed, the remaining ones determine the calculation order. A StackLimit is enforced to guard against possible long circular dependency loops and any error will result in all corresponding column data being cleared:
foreach (var idx in _ColumnsWithExpressions)
{
var col = _Columns[idx];
var expression = col.Expression;
if (!processed.Contains(idx))
{
if (expression.Error == null)
{
var stackDepth = StackLimit;
order.Clear();
_RecurseExpressionDependencies(expression, processed, order,
ref stackDepth);
if (expression.Error == null)
{
if (stackDepth >= 0)
{
_CalculationOrder.AddRange(order);
_CalculationOrder.Add(idx);
}
else expression.Error = "Circular references detected";
}
}
processed.Add(idx);
}
if (expression.Error != null && col != null) col.SetConstantValue(null);
}
Each Expression has its ColumnsNeeded property processed for Expressions and so on up to the recursion limit. Note that the type of collections used is important as order must be strictly maintained:
void _RecurseExpressionDependencies(DataColumnExpression expression, ISet<int> processed,
List<int> order, ref int stackDepth)
{
stackDepth--;
if (stackDepth < 0) return;
if (expression.ColumnsNeeded != null)
{
string errors = null;
foreach (var idx in expression.ColumnsNeeded)
{
if (processed.Contains(idx)) continue;
var col = _Columns[idx];
if (col.Expression != null)
{
if (col.Expression.Error == null)
{
_RecurseExpressionDependencies(col.Expression, processed, order,
ref stackDepth);
order.Add(col.Index);
}
if (col.Expression.Error != null)
{
processed.Add(idx);
errors = col.Expression.Error;
break;
}
}
processed.Add(idx);
}
expression.Error = errors;
}
}
Calculation
All recalculation of Expressions occurs within Recalculate() and it is used even if there are no Expressions to send notifications of the changes to any listeners - e.g. the DataSourceView described later on in this article uses this change set notification to determine when to re-apply any sorting and filtering to its view.
A simplified version of the routine is instructive - see the source for full details.
Firstly, any caller supplied list of change columns will result in a subset of the main recalculation. This makes a big difference to recalculation time especially for things like changing only the Filter Expression:
public ICollection<int> Recalculate(ICollection<int> changedColumns,
ICollection<Key> rows, ref int errorThreshold)
{
var order = _CalculationOrder;
if (changedColumns != null && changedColumns.Count > 0)
{
order = new List<int>(_CalculationOrder.Count);
var columnsToCalculate = new SortedSet<int>(changedColumns);
foreach (var idx in _CalculationOrder)
{
var exp = _Columns[idx].Expression;
if (!exp.HasNeverBeenCalculated && !changedColumns.Contains(idx))
{
var neededFields = exp.ColumnsNeeded;
if (neededFields == null) continue;
if (!columnsToCalculate.Overlaps(neededFields)) continue;
}
columnsToCalculate.Add(idx);
order.Add(idx);
}
}
Columns with expressions are then processed in the (possibly reduced) calculation order, using the cached list of ColumnsNeeded to form the array of input column(s) needed:
foreach (var idx in order)
{
var col = _Columns[idx];
var expression = col.Expression;
var error = expression.Error;
if (error == null && expression.ColumnsNeeded != null)
{
var args = new object[expression.DelegateArguments.Length];
var cols = new DataColumn<C>[args.Length];
for (int a = 0; a < args.Length; a++)
{
cols[a] = _Columns[expression.DelegateArguments[a]];
}
expression.LastErrorCount = 0;
expression.HasNeverBeenCalculated = false;
for (int i = 0; i < RowCount; i++)
{
object value;
if (_DoOneRow(i, expression, cols, args, out value, errorThreshold))
{
col[i] = value;
continue;
}
col.SetConstantValue(null, i);
res++;
break;
}
}
}
Finally the Expression is calculated for each row only if all of the input column data on that row are not null (there is currently no support for nullable value types):
static bool _DoOneRow(int i, DataColumnExpression expression, DataColumn<C>[] cols,
object[] args, out object res, int errorThreshold)
{
int nullColumns = 0;
for (int a = 0; a < cols.Length; a++)
{
var arg = cols[a][i];
args[a] = arg;
if (arg == null) nullColumns++;
}
if (nullColumns > 0)
{
res = null;
return true;
}
try
{
res = expression.CompiledDelegate(args);
return true;
}
catch (Exception)
{
res = null;
expression.LastErrorCount++;
if ((errorThreshold >= 0) && (expression.LastErrorCount > errorThreshold))
{
return false;
}
return true;
}
}
WPF Implementation
The problem with the WPF binding approach is that it tries too hard to always work even when the result will never scale. A good example of this is where it sometimes is perfectly happy to use IEnumerable thereby requiring multiple enumerations just to work out the index of a data item.
Moreover, even the availability of the new INotifyCollectionChanged interface for batched collection changes does not mean that controls like the inbuilt WPF DataGrid or its associated ICollectionView can handle more than one notification at once. The inbuilt sorting and filtering is notoriously slow primarily because of the attempt to generalise too much and to decouple the DataGrid and the ICollectionView from the data.
The DataSourceView
After much reverse engineering the best approach to overcome these (and other) deficiencies is to inherit off the CollectionView class and implement the required IItemProperties and IEnumerator interfaces:
internal class DataSourceView<R, C> : CollectionView, IItemProperties, IEnumerator, IComparer<int>
where R : struct
where C : new()
{
public readonly DataSource<R, C> Source;
Construction consists of hooking into the DataSource and sorting collections to keep track of when any filter or sorting is changing:
Source.OnFilterChanged = (exp, isValid) => _filterChanged = true;
_sortDescriptions = new SortDescriptionCollection();
((INotifyCollectionChanged)_sortDescriptions).CollectionChanged
+= (s, e) => { _sortChanged = true; _sort = null; };
Source.OnCalculation = OnSourceCalculation;
Refreshing is manually handled by firing a single collection reset event only once all changes have been made:
readonly NotifyCollectionChangedEventArgs _CollectionResetArgs =
new NotifyCollectionChangedEventArgs(NotifyCollectionChangedAction.Reset);
protected override void RefreshOverride()
{
base.OnCollectionChanged(_CollectionResetArgs);
}
The general view design is to maintain a one-based mapping between the view and the row and vice versa only when filtering or sorting is in effect. The crux of the filtering routine then looks like this:
if (!bIsSorting) Array.Clear(_mapToView, 0, _mapToView.Length);
if (Source.HasValidFilter)
{
foreach (var include in Source.FilterEnumerator())
{
if (include)
{
_mapToSource[_viewCount] = i + 1;
_viewCount++;
if (!bIsSorting) _mapToView[i] = _viewCount;
}
i++;
}
}
else
{
while (i < _sourceCount)
{
_mapToSource[i] = i + 1;
if (!bIsSorting) _mapToView[i] = i + 1;
i++;
}
_viewCount = _sourceCount;
}
Array.Clear(_mapToSource, _viewCount, _mapToSource.Length - _viewCount);
if (bIsSorting) _sortChanged = true;
The corresponding sorting routine then first has to (re)create the compiled comparer:
if (_sort == null)
{
var input = new KeyValuePair<Type, bool>[sdCount];
for (int i = 0; i < input.Length; i++)
{
var sd = _sortDescriptions[i];
var col = Source.Columns[Source.TryGetColumnIndexByBindingName(sd.PropertyName)];
_sortArgs[i] = (object[])col;
input[i] = new KeyValuePair<Type, bool>
(col.Type, sd.Direction == ListSortDirection.Ascending);
}
_sort = _parser.CreateComparer(input);
}
Then apply a sorting algorithm to the integer array such as Array.Sort(_mapToSource, 0, _viewCount, /*comparer*/):
TimSort.ArrayTimSort<int>.Sort(_mapToSource, 0, _viewCount, _Comparer);
Array.Clear(_mapToView, 0, _mapToView.Length);
for (int i = 0; i < _viewCount; i++)
{
var src = _mapToSource[i] - 1;
_mapToView[src] = i + 1;
}
These maps are then used for the two critical functions in the view. Note how the mapping arrays are one-based to avoid the need to reallocate them should a filter cause the number of rows to jump up and down a lot:
public override object GetItemAt(int viewIndex)
{
if (_usingMapping)
{
viewIndex = _mapToSource[viewIndex] - 1;
Debug.Assert(viewIndex >= 0,
"DataSourceView.GetItemAt: an invalid ViewIndex was requested");
}
return _sourceAsList[viewIndex];
}
public override int IndexOf(object item)
{
var row = item as DataRow<R, C>
if (row != null)
{
var res = row.RowIndex;
if (_usingMapping)
{
res = _mapToView[res] - 1;
}
return res;
}
return -1;
}
Basic Usage
The most optimal approach is to bind manually in the constructor of the Window with AutoGenerateColumns enabled:
public MainWindow()
{
InitializeComponent();
DataContext = this;
var cvs = new DataSourceView<RowMetaData, ColMetaData>(_source, _parser);
uiGrid.ItemsSource = cvs;
}
Before the grid becomes visible, hide the columns and enable sorting:
void Window_Loaded(object sender, RoutedEventArgs e)
{
for (int i = 0; i < uiGrid.Columns.Count; i++)
{
var ui = (DataGridTextColumn)uiGrid.Columns[i];
ui.Visibility = System.Windows.Visibility.Collapsed;
var binding = (Binding)ui.Binding;
ui.SortMemberPath = binding.Path.Path;
ui.CanUserSort = true;
}
}
To use the row Metadata to change colours as described in the DataSource section use the row events:
Brush _brushSaved;
void uiGrid_LoadingRow(object sender, DataGridRowEventArgs e)
{
var row = (DataRow<RowMetaData, ColMetaData>)e.Row.Item;
var md = _source.GetMetaData(row.RowIndex);
if (md.IsSpecial)
{
_brushSaved = e.Row.Background;
e.Row.Background = Brushes.Plum;
}
}
void uiGrid_UnloadingRow(object sender, DataGridRowEventArgs e)
{
var row = (DataRow<RowMetaData, ColMetaData>)e.Row.Item;
var md = _source.GetMetaData(row.RowIndex);
if (md.IsSpecial)
{
e.Row.Background = _brushSaved;
}
}
Resetting the DataGrid for first time usage involves using the DataSource routines previously described and controlling the visibility of the UI columns as needed:
void ResetButton_Click(object sender, RoutedEventArgs e)
{
for (int i = 0; i < _source.ColumnCount; i++)
{
var col = uiGrid.Columns[i];
col.Visibility = System.Windows.Visibility.Collapsed;
col.SortDirection = null;
col.DisplayIndex = i;
}
The key point here is that because all UI columns are actually pre-bound (even though they do not all exist in the DataSource as real Columns) each UI column must be carefully recycled:
for (int i = 0; i < _InitialColumns.Length; i++)
{
var name = _InitialColumns[i].Key;
var header = name.Split('.')[1];
var ui = uiGrid.Columns[i];
ui.Header = header;
ui.Visibility = System.Windows.Visibility.Visible;
_source.Columns[i].MetaData = new ColMetaData { Column = ui };
}
Styles need to be programmatically assigned because of the dynamic nature of the columns as does the string formatting to apply. A custom converter assigned to the Binding provides the most flexible approach since the formatting string could be stored within the column Metadata:
var cellStyle = new Style(typeof(TextBlock));
cellStyle.Setters.Add(new Setter
(TextBlock.HorizontalAlignmentProperty, HorizontalAlignment.Right));
for (int i = 1; i < _InitialColumns.Length; i++)
{
var ui = (DataGridTextColumn)uiGrid.Columns[i];
ui.ElementStyle = cellStyle;
var binding = (Binding)ui.Binding;
binding = new Binding(binding.Path.Path);
binding.Converter = _N2Converter;
ui.Binding = binding;
}
Finally the view is asked to perform a refresh, something that ends up in the overridden RefreshOverride() routine:
void RefreshVewOnly()
{
var view = (DataSourceView<RowMetaData, ColMetaData>)uiGrid.ItemsSource;
view.Refresh();
}
Tri-State Sorting
The ability to hold the shift-key down and sort multiple columns and to toggle sorting off again are standard features and it is annoying that the inbuilt WPF DataGrid does not have them already. The following code is independent of the custom view and the custom DataSource except for the refreshing which may not work for all views:
void uiGrid_Sorting(object sender, DataGridSortingEventArgs e)
{
e.Handled = true;
var view = (ICollectionView)uiGrid.ItemsSource;
var ui = (DataGridTextColumn)e.Column;
var toMatch = ui.SortMemberPath;
var sorts = view.SortDescriptions;
if (ui.SortDirection == ListSortDirection.Descending)
{
if ((Keyboard.Modifiers & ModifierKeys.Shift) == ModifierKeys.Shift)
{
for (var i = 0; i < sorts.Count; i++)
{
if (sorts[i].PropertyName == toMatch)
{
sorts.RemoveAt(i);
ui.SortDirection = null;
break;
}
}
}
else
{
_ClearSorting(sorts);
}
}
else if (ui.SortDirection == ListSortDirection.Ascending)
else
}
view.Refresh();
}
See the WPF sample application for more details on how the other two cases of adding/changing sorting are handled.
WinForms Implementation
The problem with the inbuilt WinForms DataGrid is that it takes abstraction to new levels of silliness with so much decoupling via events that it is almost unusable for real-world data sizes.
Luckily the DataGrid has a fully Virtualised data mode to avoid having to use binding and there are sufficient extension points to suppress the events before they bubble up too far.
The DataSourceView
It seemed sensible to simply alter the WPF DataSourceView to support the filtering and sorting in as similar way as possible to the WPF approach:
internal class DataSourceView<R, C> : IComparer<int>
where R : struct
where C : new()
{
public readonly DataSource<R, C> Source;
public ListSortDescriptionCollection SortDescriptions {
get { return _ListSortDescriptions; }
set
{
_ListSortDescriptions = value;
_sortChanged = true; _sort = null;
}
}
Construction consists of hooking into the DataSource and sorting collections (above) to keep track of when any filter or sorting is changing:
Source.OnFilterChanged = (exp, isValid) => _filterChanged = true;
Source.OnCalculation = OnSourceCalculation;
Refreshing has to be manually handled by the developer at the WinForms level; all this DataSourceView does is indicate if entire rows have changed due to filtering or sorting:
public bool Refresh()
{
return possibleRowChanges || _usingMapping;
}
Unfortunately the implementation of deleting rows is unspeakably bad and I have not found any way to override it. The best workaround so far is to switch to a total reset as soon as the number of rows gets "too much", something that can only be determined empirically. (Trying to use Row visibility instead opened up the whole problem of the internal UI Row classes no longer being shared between all Rows and other problems.)
Another issue is that calling the original Refresh() (causing a collection reset) is far slower than just invalidating the columns. Both these workarounds are implemented to good effect speedwise below:
void RefreshVewOnly(ICollection<int> changes = null)
{
var possibleRowChanges = _view.Refresh();
const int Tolerance = 200;
var diff = uiGrid.RowCount - _view.Count;
if (diff > Tolerance)
{
uiGrid.Rows.Clear();
}
uiGrid.RowCount = _view.Count;
if (!uiGrid.Refresh())
{
if (possibleRowChanges || changes == null || changes.Count == 0)
{
foreach (DataGridViewColumn col in uiGrid.Columns)
{
if (col.Visible)
{
uiGrid.InvalidateColumn(col.Index);
continue;
}
break;
}
}
else
{
foreach (var change in changes)
{
var col = _source.Columns[change].MetaData.Column;
uiGrid.InvalidateColumn(change);
}
}
}
}
Unfortunately to suppress the collection change events a custom DataGridView must be created that itself will create a custom DataGridViewRowCollection:
public class CustomDataGridViewRowCollection : DataGridViewRowCollection, ICollection
{
readonly static CollectionChangeEventArgs _RefreshCollectionArgs =
new CollectionChangeEventArgs(CollectionChangeAction.Refresh, null);
protected override void OnCollectionChanged(CollectionChangeEventArgs e)
{
((CustomDataGridView)base.DataGridView).OnRowCollectionDirty();
}
internal void Refresh()
{
base.OnCollectionChanged(_RefreshCollectionArgs);
}
}
This custom DataGridViewCollection marks itself as dirty in the custom DataGridView:
public class CustomDataGridView : DataGridView
{
protected override DataGridViewRowCollection CreateRowsInstance()
{
return new CustomDataGridViewRowCollection(this);
}
internal void OnRowCollectionDirty()
{
_state |= States.RowCollectionDirty;
}
public new bool Refresh()
{
if (_state.HasFlag(States.RowCollectionDirty))
{
((CustomDataGridViewRowCollection)Rows).Refresh();
_state &= ~States.RowCollectionDirty;
return true;
}
return false;
}
The general view design is to maintain a one-based mapping between the view and the row and vice versa only when filtering or sorting is in effect. It has the same implementation as the WPF version so will not be discussed again here.
Basic Usage
The grid must be created manually with VirtualMode enabled:
public Form1()
{
this.DoubleBuffered = true;
SuspendLayout();
InitializeComponent();
#region Create subclassed GridView
uiGrid = new CustomDataGridView();
uiGrid.AllowUserToAddRows = false;
uiGrid.AllowUserToDeleteRows = false;
uiGrid.AllowUserToOrderColumns = true;
uiGrid.AllowUserToResizeRows = false;
uiGrid.MultiSelect = true;
uiGrid.Name = "uiGrid";
uiGrid.ReadOnly = true;
uiGrid.SelectionMode = DataGridViewSelectionMode.FullRowSelect;
uiGrid.CellFormatting += uiGrid_CellFormatting;
uiGrid.CellValueNeeded += uiGrid_CellValueNeeded;
uiGrid.ColumnHeaderMouseClick += uiGrid_ColumnHeaderMouseClick;
#endregion
uiGrid.VirtualMode = true;
ResumeLayout(true);
_view = new DataSourceView<RowMetaData, ColMetaData>(_source, _parser);
_view.OnMetric = OnMetric;
}
Override the required event to provide the data for VirtualMode:
void uiGrid_CellValueNeeded(object sender, DataGridViewCellValueEventArgs e)
{
if (!_view.IsEmpty) e.Value = _view.GetItemAt(e.RowIndex, e.ColumnIndex);
}
To use the row Metadata to change colours as described in the DataSource section use the event:
void uiGrid_CellFormatting(object sender, DataGridViewCellFormattingEventArgs e)
{
if (e.ColumnIndex == 0)
{
var md = _source.GetMetaData(e.RowIndex);
if (md.IsSpecial) e.CellStyle.BackColor = Color.Plum;
}
}
Resetting the DataGrid for first time usage involves using the DataSource routines previously described and just removing all UI columns:
void uiReset_Click(object sender, EventArgs e)
{
uiGrid.SuspendLayout();
uiGrid.Columns.Clear();
Then just create columns in the usual way:
for (int i = 0; i < _InitialColumns.Length; i++)
{
var name = _InitialColumns[i].Key;
var header = name.Split('.')[1];
uiGrid.Columns.Add(name, header);
}
Now set the formatting and the sort mode. The formatting information could be stored within the column Metadata rather than hard-coded:
for (int i = 0; i < _InitialColumns.Length; i++)
{
var ui = uiGrid.Columns[i];
ui.SortMode = DataGridViewColumnSortMode.Programmatic;
if (i == 0)
{
ui.DefaultCellStyle.Alignment = DataGridViewContentAlignment.TopLeft;
ui.DefaultCellStyle.Format = null;
}
else
{
ui.DefaultCellStyle.Alignment = DataGridViewContentAlignment.TopRight;
ui.DefaultCellStyle.Format = "N2";
}
_source.Columns[i].MetaData = new ColMetaData { Column = ui };
}
uiGrid.ResumeLayout();
Finally the view is asked to perform a refresh: see the previously discussed RefreshVewOnly() for details.
Tri-State Sorting
The ability to hold the shift-key down and sort multiple columns and to toggle sorting off again are standard features and it is annoying that the inbuilt WinForms DataGrid does not have them already.
void uiGrid_ColumnHeaderMouseClick(object sender, DataGridViewCellMouseEventArgs e)
{
var ui = uiGrid.Columns[e.ColumnIndex];
var toMatch = _view.Properties[e.ColumnIndex];
var sorts = _view.SortDescriptions;
var newSorts = new List<ListSortDescription>(sorts.Count + 1);
if (ui.HeaderCell.SortGlyphDirection == SortOrder.Descending)
{
if ((ModifierKeys & Keys.Shift) == Keys.Shift)
{
for (var i = 0; i < sorts.Count; i++)
{
if (sorts[i].PropertyDescriptor == toMatch)
{
ui.HeaderCell.SortGlyphDirection = SortOrder.None;
continue;
}
newSorts.Add(sorts[i]);
}
}
else
{
_ClearSorting(sorts);
}
}
else if (ui.HeaderCell.SortGlyphDirection == SortOrder.Ascending)
else
}
_view.SortDescriptions = new ListSortDescriptionCollection(newSorts.ToArray());
RefreshVewOnly(changes: null);
}
See the WinForms sample application for more details on how the other two cases of adding/changing sorting are handled.
References
The stable TimSort sorting implementation used
The schema for the Report Definition Language
Issues
- The WPF grid only binds successfully on .NET v4.5
Enhancements
- Introduce support for nullable (value) types;
- Surface the first runtime error for each Expression;
- Combine the DataRow and Metadata lists into a single collection and replace with an array (with incremental allocation);
- Implement the handler for Field Expressions like
Expression.ToString(); - Extend DataColumns to support one-time Expression filtering where the result is provided as a separate set of data to enable implementation of the Excel-like drop down filtering lists;
- Investigate how Grouping might work in the WPF grid by using sorting and row metadata or DataRow;
- Consider an MRU cache of all expressions to avoid unnecessary parsing.
History
- 1.0 - Initial write up
- 1.1 - Added Expressions in Practice
- 1.2 - Added Issues section

