(click here for a full screen image)
The latest versions of this code can be obtained from my GitHub account
here.
In The Beginning...
"In the beginning of creation, when Marc made the website, the website
was without form and void, with darkness over the face of the HTML, and a mighty
script that swept over the surface of the IDE. Marc said, 'Let there be a
database spider UI', and there was a database spider UI; and Marc saw that the
UI was good, and he separated primary keys from foreign keys. He called
the foreign keys parent/child relationships, and the darkness Ruby on Rails.
So evening came, and morning came, the first day."
I've been wanting to create a database navigator, what a friend of mine
termed a "Spider UI", for quite some time now. I originally wrote an
implementation in WinForms for an Oracle database but that never went as far as
I wanted it to go. Currently, I'm working a lot with Ruby on Rails and
also encountered a couple layers called Slim
("a lightweight templating engine") and Sass
("Syntactically Awesome Style Sheets") in another project. Wanting to
learn more about how Slim and Sass work together, I came up with this project
idea. In its full glory, I'm wanting to add all sorts of interesting
features, such as custom layout for editing, but first, I wanted to get some
basic functionality in place first.
Internally, the website must support:
- Connect to SQL Server (yes, Ruby on Rails can connect to SQL Server.)
- Use a separate database for session and other metadata store, leaving
the database we're connecting to for navigation untouched.
- Rather than physical Models for each table, implement a dynamic Model.
- Dynamic discovery of user tables and foreign key relationships by inspecting
the database schema rather than relying on the Rails application schema (which
would be otherwise generated from concrete Models backed by physical tables.)
The user interface must support:
- Selecting a table from a list
- Viewing the data for that table
- Selecting parent and child tables to navigate to
- Selecting records to qualify navigation and display of parent/child
records
- Pagination
- Breadcrumb trail of parent/child navigation
What I'm leaving for "Day 2" are several metadata features:
- Replacing foreign key ID's with "display field" lookups.
- Describing the display fields in a lookup table to use when resolving
foreign keys.
- Specifying fields that need not be displayed.
- Aliasing field names
- Aliasing table names
"Day 3" will consist of supporting:
- type-based automated generation of UI's to edit table data.
- custom record editing templates.
"Day 4" will consist of:
- views (described in metadata as opposed to database-side views), as
creating views with full schema information is required.
- creating SQL statements to support transactions on views
What comes after that will probably involve the support of custom processing
of data during transactions (both code and PL/SQL calls) using Ruby as well as
server-side triggers on transactions. We'll see!
If Your New To Ruby on Rails
Code Project is primarily (at the time of this writing!) a site for all
things Microsoft, so if this is the first time you're encountering Ruby on
Rails, I'd recommend reading through some of my other articles on the Ruby
language and Ruby on Rails:
as these are more tutorial based for developing Ruby on Rails (RoR)
applications. This article assumes that you already have some familiarity
with the project structure of a RoR application.
AdventureWorks2008
This article uses Microsoft's example database, Adventure Works, to
demonstrate Ruby on Rails connectivity to SQL Server as well as example dataset
for all the screenshots in this article.
About the Ruby Code
You'll notice that I tend to write very short Ruby functions - this is
intended to promote the clarity of higher-level functions, which can otherwise
detract from the purpose of the function when embedding idiomatic Ruby and
arcane operations. I also like to explicitly state what the return value
of a function is, even when it's unnecessary. This promotes further
clarity to someone who is unfamiliar with the application code.
About the Slim and Sass Markup
I've tried to keep the markup concise and I've put comments where it seems
appropriate to describe the intent of the markup. This is especially
salient in the Sass markup, where the intention behind the styling is not
necessarily obvious.
Gems and What They Are Used For
Gems are Ruby on Rails' plug-in mechanism for adding functionality from the
vast amount of free and open source components that people have contributed to
over the years. Besides the Rails gems, the ones I'm taking advantage of
are:
gem 'tiny_tds'
gem 'activerecord-sqlserver-adapter'
gem 'sqlite3'
gem 'slim'
gem 'thin'
gem 'sass'
gem 'will_paginate'
TinyTDS
The gem tiny_tds
necessary for connecting to SQL Server. TinyTDS requires a SQL Server
Authentication login, as opposed to a Windows Authentication login. I have
a short blog entry here on connecting to SQL Server Express from Ruby which
covers configuring SQL Server Express and testing the TinyTDS connectivity.
In this application, TinyTDS is used to acquire the schema information from SQL
Server -- see the section "Schema Class" below.
activerecord-sqlserver-adapter
This gem uses the "dblib" connection mode which in turn is dependent upon
TinyTDS. What this gem enables you to do is to work with the Rails
ActiveRecord
API for all transactions with the database. It's important that we use
ActiveRecord for table queries because the pagination system relies on our Model
classes being derived from ActiveRecord::Base. In future articles, we'll
also be relying, in part, on ActiveRecord for other transactions on the table
records.
Rails expects the connection information to be specified in the config\database.yml
file. Here we set up our development connection, specifying the sqlserver
adapter which the above gem provides us, along with the connection information
required by TinyTDS.
development:
adapter: sqlserver
database: AdventureWorks2008
dataserver: localhost\SQLEXPRESS
username: ruby
password: rubyist1
Sqlite3
One of the requirements of this application is to not change the schema of
the database that we're "spidering." Also, there's a lot of session
information that is being preserved -- too much to place is session cookies on
the client. We're using Sqlite3 for storing session information
independent of our SQL Server database and
this gem provides
the connectivity. To see how this is done, read the
section on "Storing
Session Information in a Separate Database."
Slim
This gem eliminates the angle brackets and ending tags of the HTML script.
Here's a simple example of the lighter-weight syntax:
doctype
html
head
title Database Spider
= stylesheet_link_tag "application", media: "all"
= javascript_include_tag "application"
= csrf_meta_tags
body
= yield
Notice how indentation is used to determine where the closing tags should go
in the generated HTML.
Sass
This gem is also "lightens" the description of CSS and works very well in
conjunction with Slim. You'll see Slim/Sass used such that the structure
of the Slim and Sass markup are identical. Here's a short example taken
from the user table list markup:
The Slim Markup
.table_list_region
p Tables:
.table_list
ul
- @tables.each do |table_name|
li
= link_to(table_viewer_path(table_name: table_name)) do
t #{table_name}
Notice how Slim knows how to work with both HTML and Ruby script in the
markup!
The Sass Markup
.table_list_region
width: 240px
height: 700px
float: left
p
text-align: left
margin-bottom: 2px
.table_list
text-align: left
border: 1px solid
border-radius: 3px
width: 100%
height: 100%
line-height: 1.5em
ul
width: 190px
height: 99%
overflow: auto
margin-top: 2px
li
list-style-type: none
margin-left: -30px
a:visited
color: #000000
a:link
color: #000000
text-decoration: none
a:hover
color: #0000FF
You can see how Sass markup can follow the same structure as the Slim markup.
The problem with this approach is that it obfuscates re-use of CSS. For
example, I might want to re-use the table_list styling but since it's a child of table_list_region, I can't
(at least not without a table_list_region container).
However, I can certainly outdent the styling:
.table_list_region
width: 240px
height: 700px
float: left
p
text-align: left
margin-bottom: 2px
.table_list
text-align: left
... etc ...
without affecting the structure of the Slim markup. Now <ocde>table_list is
accessible inside the container as well as reusable by other containers. Unfortunately, I
have worked on at least one major open source project in which the developers
chose not to promote styling re-use, resulting in complex Sass structures in
which one has to follow the hiearchy of the Slim exactly to locate the
styling that I wanted to change. Don't do this unless your styling is
truly specific to its container context!
Will_paginate
This is an amazing
gem that paginates your data and provides a variety of pre-existing styling and
also the ability to customize the styling of the pagination bar. And of
course, one of the advantages of using pagination is that for tables with large
numbers of records, only the records for that page are returned from the
database, greatly improving usability.
The Code
I'm not going to go into every detail of the code, but I will point out some
of the more interesting features.
This class (schema.rb) encapsulates the static functions we need for
connecting to SQL Server directly and obtaining schema information and thus
relies on the TinyTDS gem for the direct SQL connection. The
main workhorse is this function:
def self.execute(sql)
client = create_db_client
result = client.execute(sql)
records = result.each(as: :array, symbolize_keys: true)
array = convert_to_array_of_hashes(result.fields, records)
array
end
We rely on these helper methods (helpers\my_utils.rb) to create a client
connection:
# create a client connection.
def create_db_client
config = get_current_database_config
config_as_symbol = symbolize_hash_key(config)
client = TinyTds::Client.new(config_as_symbol)
client
end
# Returns the current database config has a dictionary of string => string
def get_current_database_config
Rails.configuration.database_configuration[Rails.env]
end
# Given a dictionary of string => string, returns :symbol => string
# Example: config_as_symbol = symbolize_hash_key(config)
def symbolize_hash_key(hash)
hash.each_with_object({}){|(k,v), h| h[k.to_sym] = v}
end
Once the records are returned from TinyTDS, I want to package them into an
array of hashes (field => value) so that there's a consistent representation of
the resulting data. This requires a couple post-processing functions:
# Convert the array of records from the TinyTDS query into an array of hashes, where
# the keys are the field names.
def self.convert_to_array_of_hashes(fields, records)
array = []
records.each { |record|
dict = hash_from_key_value_arrays(fields, record)
array << dict
}
array
end
# Given two arrays of equal length, 'keys' and 'values', returns a hash of key => value
def hash_from_key_value_arrays(keys, values)
Hash[keys.zip values]
end
Schema Queries
We can now define the three functions that we need for our Spider UI:
- get_user_tables
- get_parent_table_info_for
- get_child_table_info_for
In the last two functions, we replace the string "[table]" with the table
name before executing the query:
sql.sub!('[table]', table_name.partition('.')[2])
What we're not dealing with at the moment is that the table name being passed
in is fully qualified (it includes also the schema name) but the query doesn't
pay attention to the schema name, hence we need to extract just the table name
from the parameter value. This is one of those "TODO" items for a later
date.
These functions rely on our storing the actual queries in a "queries.yml"
file, which is a hierarchical file similar to XML in concept but very different
in implementation. In this file, we store our schema queries:
Schema:
user_tables: "
select
s.name + '.' + o.name as table_name
from
sys.objects o
left join sys.schemas s on s.schema_id = o.schema_id
where
type_desc = 'USER_TABLE'"
get_parents: "
SELECT
f.parent_object_id as ChildObjectID,
SCHEMA_NAME(f.schema_id) SchemaName,
OBJECT_NAME(f.parent_object_id) TableName,
COL_NAME(fc.parent_object_id,fc.parent_column_id) ColName,
SCHEMA_NAME(ref.schema_id) ReferencedSchemaName,
OBJECT_NAME(f.referenced_object_id) ReferencedTableName,
COL_NAME(fc.referenced_object_id, fc.referenced_column_id) ReferencedColumnName
FROM
sys.foreign_keys AS f
INNER JOIN sys.foreign_key_columns AS fc ON f.OBJECT_ID = fc.constraint_object_id
INNER JOIN sys.tables t ON t.object_id = fc.referenced_object_id
INNER JOIN sys.tables ref ON ref.object_id = f.referenced_object_id
WHERE
OBJECT_NAME (f.parent_object_id) = '[table]'"
get_children: "
SELECT
f.parent_object_id as ChildObjectID,
SCHEMA_NAME(f.schema_id) SchemaName,
OBJECT_NAME(f.parent_object_id) TableName,
COL_NAME(fc.parent_object_id,fc.parent_column_id) ColName,
SCHEMA_NAME(ref.schema_id) ReferencedSchemaName,
OBJECT_NAME(f.referenced_object_id) ReferencedTableName,
COL_NAME(fc.referenced_object_id, fc.referenced_column_id) ReferencedColumnName
FROM
sys.foreign_keys AS f
INNER JOIN sys.foreign_key_columns AS fc ON fc.constraint_object_id = f.OBJECT_ID
INNER JOIN sys.tables t ON t.OBJECT_ID = fc.referenced_object_id
INNER JOIN sys.tables ref ON ref.object_id = f.referenced_object_id
WHERE
OBJECT_NAME (f.referenced_object_id) = '[table]'"
and we again use a small helper function to retrieve the text:
# Gets the specified query from the config.yml file
# Example: sql = get_query("Schema", "user_tables")
# TODO: cache keys
def get_query(key1, key2)
sql = YAML.load_file(File.expand_path('config/queries.yml'))
sql[key1][key2]
end
Here's another "TODO" item for later: eventually this structure will be "refactored" to include the database
context, because of course querying the schema of a database is very database
specific!
Get User Tables
This function simply returns a collection of user table names:
# Returns an array of strings containing the user tables in the database to which we're connecting.
def self.get_user_tables
client = create_db_client
sql = get_query("Schema", "user_tables")
result = client.execute(sql)
records = result.each(as: :array, symbolize_keys: true)
names = get_column(records, 0)
names
end
Get Parent Table Info
This function returns the foreign key associations of the current table,
resulting in an array of all parent tables along with schema information
describing the columns of both child and parent tables that describe the foreign
key relationship:
# Returns an array of hashes (column name => value) of the parent table schemas of the specified table.
def self.get_parent_table_info_for(table_name)
sql = get_query("Schema", "get_parents")
sql.sub!('[table]', table_name.partition('.')[2])
execute(sql)
end
Get Child Table Info
This function returns the child tables and their foreign key column
relationships to the specified parent table. This query has a similar
structure as what is returned in the previous function, courtesy of how the SQL
is formatted (see earlier.)
# Returns an array of hashes (column name => value) of the child table schemas of the specified table.
def self.get_child_table_info_for(table_name)
sql = get_query("Schema", "get_children")
sql.sub!('[table]', table_name.partition('.')[2])
execute(sql)
end
We need to tell Rails in initializers\session_store.rb
that we want to use a database rather than cookies for storing session
information:
DatabaseSpider::Application.config.session_store :active_record_store
However, we want to tell Rails not to use the SQL Server database, so we also
need:
ActiveRecord::SessionStore::Session.establish_connection(:sessions)
and finally, we need to put the session definition in the config\database.yml
file:
# use sqlite3 as the DB for storing session information.
sessions:
adapter: sqlite3
database: db/session.sqlite3
pool: 5
timeout: 5000
Dynamic Active Records
Another requirement is to avoid creating a concrete Model class for every
physical table in the database. To accomplish this, we derive a class from
ActiveRecord::Base but specify the table name to which it is associated:
class DynamicTable < ActiveRecord::Base
# Returns an array of records for the specified table.
def set_table_data(table_name)
DynamicTable::table_name = table_name
end
# Returns the field names given at least one record.
def get_record_fields(records)
fields = []
fields = records[0].attributes.keys if records.count > 0
fields
end
end
This enables us to interact with the table just as we would with any other
ActiveRecord instance.
The function get_record_fields is used to return the field names for the
record - we arbitrarily pick the first record for the field list, assuming any
records exist at all. This is a bit problematic because even if there are
no records returned, we'd like the table to at least display the field names.
So one of the "TODO" items is to use a TinyTDS query with "where 1=0", which,
though it returns zero rows, will populate the field names for us.
TableViewerController, the Index Function
The index function of the TableViewerController is the main workhorse of the
website:
def index
initialize_attributes
update_model_page_numbers
if self.table_name
restore_page_number_on_nav # restores the page number when navigating back along the breadcrumbs
self.last_page_num = self.model_page_nums[self.table_name+'_page'] # preserve the page number so selected navigation records are selected from the correct page.
@data_table = load_DDO(self.table_name, self.last_page_num, self.qualifier, MAIN_TABLE_ROWS)
add_hidden_index_values(@data_table)
load_navigators(self.table_name)
@parent_dataset = load_fk_tables(@parent_tables)
@child_dataset = load_fk_tables(@child_tables)
# Update the parent tab index based on the existence and value of the selected_parent_table_index parameter
update_parent_child_tab_indices
end
end
Various attributes are initialized, of most important are:
- the list of user tables.
- a DynamicTable instance.
- the navigation breadcrumb trail is restored from the session.
Session Variables
There are several session variables defined in the controller:
attr_session_accessor :table_name # the selected user table
attr_session_accessor :qualifier # the qualifier currently being used to filter the selected user table
attr_session_accessor :breadcrumbs # the breadcrumb trail
attr_session_accessor :last_page_num # the last page number of the user table
attr_session_accessor :force_page_num # if set, forces the pagination to a different page, used with breadcrumbs
attr_session_accessor :model_page_nums # dictionary of page numbers for all the models being displayed.
which help preserve the state of the page between posts.
Custom Attribute Accessor
I get tired of having to write code like this:
@qualifier = session[:qualifier]
session[:table_name] = @table_name
so I wrote a custom attribute accessor that simplifies getting and setting
session values:
# Adds an "attr_session_accessor" declarator that, in addition to setting/getting the value
# to the attribute, it also gets/sets the value from the session.
# Usage inside the class defining the attribute: self.foobar = 1
# Note that "self." must prefix the usage of the attribute.
class Class
def attr_session_accessor(*args)
args.each do |arg|
self.class_eval("def #{arg}; @#{arg}=session['#{arg}']; end")
self.class_eval("def #{arg}=(val); @#{arg}=val; session['#{arg}']=val; end")
end
end
end
For the getter, this code initializes the specified attribute from the
session name, and is equivalent to writing (for the variable qualifier):
@qualifier = session[:qualifier]
The setter initializes both the attribute and the session key with the
specified value, and is the equivalent of writing (for the variable table_name):
@table_name = val
session[:table_name] = @table_name
Thus, we can code like this (this is the handler for clicking on a
breadcrumb):
# Navigate back to the selected table in the nav history and pop the stack to that point.
# Use the qualifier that was specified when navigating to this table.
# Restore the page number the user was previously on for this table.
def nav_back
stack_idx = params[:index].to_i
breadcrumb = self.breadcrumbs[stack_idx] # get the current breadcrumb
self.table_name = breadcrumb.table_name # we want to go back to this table and its qualifier
self.qualifier = breadcrumb.qualifier
self.breadcrumbs = self.breadcrumbs[0..stack_idx] # remove all the other items on the stack
self.force_page_num = breadcrumb.page_num
redirect_to table_viewer_path+"/index"
end
I suppose it would be more readable if I named these variables with some
prefix, perhaps "sess_" to make it clear to the reader that we're accessing
session data, however, an more useful "TODO" would be to put together a Session
class that has all the session attributes that the controller referenecs.
Internally, this class could still use my custom attribute accessor, but it
would also allow intellisense to work within the IDE, improving the programmer's
experience and providing clarity as to what is going on behind the scenes.
Byte Encoding
One of the issues I encountered was with SQL Server fields that were using
byte encoding. This gave Rails fits and required a helper method, applied
to each field value:
# Fixes encoding to UTF-8 for certain field types that cause problems.
# http:
helper_method :fix_encoding
def fix_encoding(value)
value.to_s.encode('UTF-8', {:invalid => :replace, :undef => :replace, :replace => '?'})
end
Hiding Fields
Certain fields that are found in the Adventure Works database can simply
always be hidden. Also, the paginator adds a column that it uses
internally for keeping track of what page the user is viewing, and finally, I
add a column that the checkbox on each row uses to identify the selected row.
None of these need to be displayed, therefore we have a couple helper methods:
# Return true if the field can be displayed.
# All sorts of interesting things can be done here:
# Hide primary keys, ModifiedDate, rowguid, etc.
helper_method :display_field?
def display_field?(table_name, field_name)
# '__rn' is something that will_paginate adds.
# '__idx' is my hidden column for creating a single column unique ID to identify selected rows, since
# we can't guarantee single-field PK's and we need some way to identify a row uniquely other than the actual data.
return false if ['__rn', '__idx', 'rowguid', 'ModifiedDate'].include?(field_name)
true
end
# Returns only the visible fields
helper_method :get_visible_fields
def get_visible_fields(data_table)
data_table.fields.keep_if {|f| display_field?(data_table.table_name, f)}
end
The User Interface
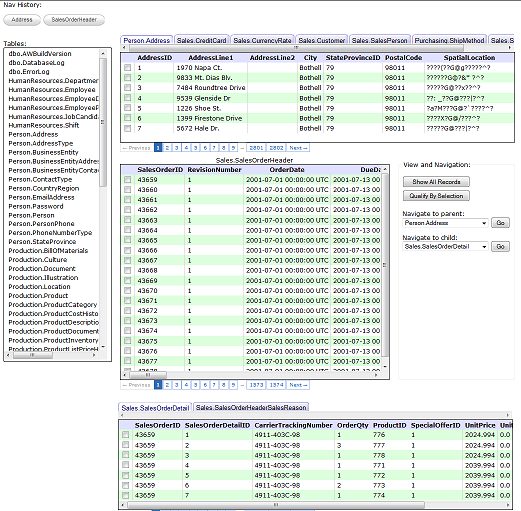
The user interface consists of six areas:
- The list of user tables in the database
- The selected table's data
- The parent tables of the selected table
- The child tables of the selected table
- Navigation options
- List of navigations (breadcrumbs)
I decided to put each of these sections into their own render block, thus the
resulting index.html.slim file is simply:
=form_for @table_viewer do |f|
= render 'breadcrumbs'
= render 'user_tables'
- # The selected table data
- if !@table_name.nil?
= render 'parent_tables'
= render 'selected_table'
= render 'navigation', f: f
= render 'child_tables'
- # Restore current page selections
javascript:
select_fk_tab('#parent_tab', '#parent_tab_content', #{@parent_tab_index}, #{@parent_tables.count})
select_fk_tab('#child_tab', '#child_tab_content', #{@child_tab_index}, #{@child_tables.count})
Breadcrumbs

The breadcrumbs is a clickable list of tables that the user has already
navigated to using the "navigate to parent" and/or "navigate to child" options.
When a breadcrumb is selected, any selection that was made to qualify the data
for that table is restored as well as the table's data.
The Slim Markup
- # The navigation breadcrumbs
.navigation_history
p = "Nav History:"
br
- if @breadcrumbs
- @breadcrumbs.each_with_index do |breadcrumb, index|
- table_name = breadcrumb.table_name
= link_to content_tag(:span, "#{table_name.partition('.')[2]}"), navigate_back_path(index: index), {:class => "button"}, :onclick => 'this.blur();'
User Tables
This is simply an alphabetical list of user tables.
The Slim Markup
- # The list of all tables.
.table_list_region
p Tables:
.table_list
ul
- @tables.each do |table_name|
li
= link_to(table_viewer_path(table_name: table_name)) do
t #{table_name}
Selected Table Data
The selected user table is displayed with a checkbox on each row so that the
user can select a specific row or rows and navigate to a child or parent table
whose resulting data is displayed in the same box but qualified by the
selection. If no selection is made, then all the parent or child data is
displayed. At the bottom of the table is the paginator (see the parent and
child table data for visual examples.)
The Slim Markup
- # The selected user table data.
.table_data_region
p #{@data_table.table_name}
= render "table_data", data_table: @data_table
.digg_pagination
= will_paginate @data_table.records, param_name: @data_table.table_name+"_page"
Note that this code (and the code used for child and table navigation) all
re-use another render called "table_data".
_table_data.html.slim
This is file used in common for rendering the table data in the selected
table, parent tables and child tables:
- # render for table data. The paginator is separate because it requires additional parameters that are specific
- # to the data being paginated.
.table_data
- visible_fields = get_visible_fields(data_table)
table
- # Display header
tr
- # Dummy header column for checkbox
th
- # Header of field names
- visible_fields.each do |field_name|
th = field_name
- # Display records
- data_table.records.each do |record|
tr class=cycle('row0', 'row1')
td
- # __idx is added by the controller to uniquely identify a record.
= check_box_tag 'selected_records[]', record["__idx"]
- visible_fields.each_with_index do |field_name, field_index|
- # Extends the last column out to the right edge of the table.
- if field_index == visible_fields.length - 1
td.last = fix_encoding(record[field_name])
- else
td = fix_encoding(record[field_name])
The interesting part of this markup is figuring out when the last column is
being rendered and to change the styling slightly so that the row color extends
to the right edge of the table box:
<rep>td
border-left: 1px solid #d0d0d0
white-space: nowrap
padding-left: 5px
padding-right: 5px
td.last
// the last column fills any remaining space
width: 100%
Also notice the snazzy cycle function of Ruby:
tr class=cycle('row0', 'row1')
which cycles through the class styling strings for the rows, achieving the
alternating colors:
tr.row0
background-color: #ffffff
tr.row1
background-color: #ddffdd
Navigation
The Navigation area lets the user select which parent or child table to
navigate to. If rows have been selected in the user table display, the
parent/child records are qualified by the selected records. In that case,
to show unqualified records, the user clicks on Show All Records. To
return to the qualified records, click on the last breadcrumb button, as the
navigation "breadcrumb" trail preserves the qualifiers.
Parent Navigation
The selected user table is treated as the child table, with foreign keys to
the parent table. If no rows in the user table have been selected, then
all rows of the parent table are displayed. If one or more rows has been
selected (using checkboxes) then all columns involved in the foreign key
relationship to the parent table are considered to construct the qualifying
"where" clause. For example, if there are two columns, one for billing
address and one for shipping address, that refer to an address, then both
address records of the parent (assuming the child has different values for the
foreign key ID) will be displayed when navigating to the parent.
Child Navigation
Here the selected user table is considered to be the parent, and the table
selected in the combobox "Navigate to child:" is inspected for foreign key
fields that map to the primary key fields of the selected user table. If
no rows in the user table have been selected (using checkboxes) then all child
records are displayed. If rows have been selected, then the qualifier is
constructed programmatically to limit the child records to only those records
that reference the selected rows.
The Slim Markup
- # table navigation
.navigation
fieldset
legend View and Navigation:
br
.nav_button
= f.submit("Show All Records", name: 'navigate_show_all')
- # Separate div because 'Go' buttons are left padded.
.nav_options
br Navigate to parent:
= select_tag "cbParents", options_from_collection_for_select(@parent_tables, 'id', 'name')
= f.submit("Go", name: 'navigate_to_parent')
br Navigate to child:
= select_tag "cbChildren", options_from_collection_for_select(@child_tables, 'id', 'name')
= f.submit("Go", name: 'navigate_to_child')
Parent and Child Tables
These two regions of the page are almost identical except for how the
pagination is handled and of course the tables and their records that they
display. The checkboxes in these tables don't do anything, yet.
The fun part about this markup is that the tabs are styled columns of a table
row, and we utilize a scrollbar for when there are more tabs that fit on the
screen.
The Slim Markup (for parent tables only)
- # if we have a selected table and it has parent tables, show the parent tables.
- if !@table_name.nil? && @parent_tables.length > 0
.tab_region
.tab_list
table
tr
- @parent_tables.each_with_index do |table_info, index|
td id="parent_tab#{index}"
a title="View #{table_info.name}"
onclick="select_fk_tab('#parent_tab', '#parent_tab_content', #{index}, #{@parent_tables.count})"
span = "#{table_info.name}"
- # table_info isn't used because this data is formatted for the comboboxes.
- # What we're actually simply interested in here is the index.
- @parent_tables.each_with_index do |table_info, index|
.tab_content id="parent_tab_content#{index}"
.tab_table_data_region
= render "table_data", data_table: @parent_dataset[index]
.digg_pagination
= will_paginate @parent_dataset[index].records,
param_name: @parent_dataset[index].table_name+"_page",
params: {selected_parent_table_index: index }
Javascript
Finally, we need a tiny amount of Javascript to put it all together, which
handles selecting a tab and rendering the page after a post or refresh:
function select_fk_tab(tab_selector, content_selector, index, num_tabs)
{
for (var i=0; i<num_tabs; i++)
{
$(tab_selector + i.toString()).removeClass('current');
$(content_selector + i.toString()).hide();
}
$(tab_selector + index.toString()).addClass('current');
$(content_selector + index.toString()).show();
}
Conclusion
When all is said and done, we have:
- successfully connected Ruby on Rails with SQL Server
- dealt with using a separate database for session state
- successfully used ActiveRecord in a dynamic context
- implemented a good start for a general purpose, web-based, database
navigator
- learned a lot about Slim and Sass in the process (which was one of my
primary goals)

