Introduction
One problem with applications based on XML is that in order to access data contained in files quite often a specific parser has to
be developed. Even having tons of libraries and tools that can, for instance, generate a big part of the parser, the required effort is
still high and of course maintenance of the parsers has to be done on every schema variation or extension. Also the two typical approaches,
SAX and DOM, have both intrinsic and not solvable limitations. In summary, developing a parser for every XML schema can be an expensive, inflexible, and
limited solution.
Storing conveniently the data in a database can be a good alternative, especially for those XML files that contain structured data
in form of records. In this article we will explain a database schema that is able to store any XML file plus the way we can
use it to get systematically specific schemas or tables from its contents, we call it the XMeLon schema. Also a parser (once parser)
for generating a XMeLon database with any XML files is provided and explained.
This schema was developed originally for the XML problem but, as a matter of fact, it is a general and flexible database schema that
can be used in many other applications. Just to mention another possible use of it, JSON data would also fit in the XMeLon schema.
Purpose of the XMeLon schema
We want to build a system that put all the information contained in XML files into a SQL database. Of course not just as raw data
but somehow getting it organized in "logical" tables that a program can query and use it in a comfortable way. It does not have to
cover or support all aspects that XML offers but be focused mainly in extracting and storing properly the data of a XML file that
is susceptible to be stored as records in tables.
Apart from this consideration we want the system to admit multiple files, even with different XML schemas
and using for that the solely input of the XML files. That is, no configuration or extra definition of the XML schemas
will be necessary, the logical structure will be deduced from the content. Moreover, not only the schema of the content tables
can be extracted but also the relationship between the resulting tables. This last information can be used by a system to extremely facilitate
the querying of the resulting database. A concept of connecting automatically SQL tables is explained and implemented in the article
The Deep Table.
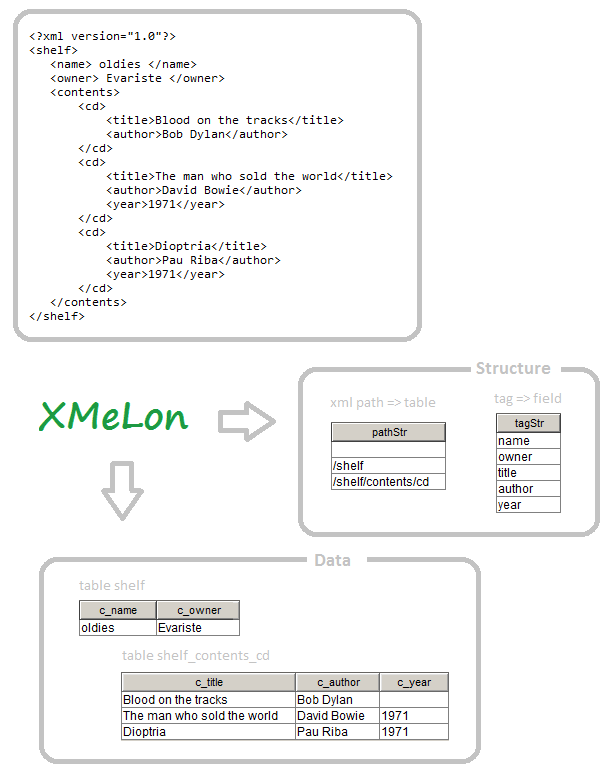
For instance, if we parse the example XML given in the article, we want to obtain the tables "shell (name, owner, ..)" and "shell_content_cd (title, author, year, ..)"
and the relationship between them so that a join of the two tables can be established.
The XMeLon approach do this in two stages using on each a different kind of schema. First a parser generates a "basis schema" database with the XML content.
Second from the basis schema database the content schema, which is the schema that reflects the particular XML structures, can be generated systematically.
Finally an application can access the whole XML content just by querying the database using SQL Select statements.
Dimensions of XML (basis schema)
By means of the basis schema we want to store any XML content into a single table or a set of few and well defined tables. So we want to discover
how may dimensions has XML as a container. A first (and certainly hastily) attempt is to observe that XML just contain text that either belongs to
the node information (path) or to the data, then we could represent our sample data as:

as if XML had only two dimensions which is not true. But before looking for the missing XML dimensions let us arrange the path more conveniently to find
afterwards the tables and dimensions we are interested in, those from the content schema, more easily. We divide the path in two: the path except the last tag, which
we call layer and the last tag which we call dimension (not meaning now XML dimension). We even get the last tag of the layer and put it in a
separate column. Now the same data looks like
We have added redundant columns so the table is still incomplete. As a matter of fact the depicted example is ambiguous, a different XML
structure could produce identical result. For example using the same data but having three shells instead of one from an XML like
<shell>
<name>oldies</name>
<owner>evariste</owner>
<contents> <cd> ... </cd> </contents>
</shell>
<shell>
<contents> <cd> ... </cd> </contents>
</shell>
<shell>
<contents> <cd> ... </cd> </contents>
</shell>
Therefore it is not only important to know from a data element the path but also the "path instance" that belongs to. Specifically we are interested in having the layer instance
as a new column. It can be represented by a counter that is incremented when the layer changes. Usually each layer will have a parent layer, we can store it
in a new column. Again the same sample with all these new columns
Now, taking a look at the value of layerCounter it is clear to which CD belongs every piece of data.
Still there are two more XML elements that we have not mention until now: attributes and "free text". Attributes can be treated just as dimensions, so for instance
these two constructions will produce basically the same:
<somenode myatt="my value">
<field2> XX </field2>
</somenode>
<somenode>
<myatt>my value</myatt>
<field2> XX </field2>
</somenode>
By free text we mean that text which is not directly enclosed within a final tag. This is allowed in XML but for the perspective of records
is not particularly interesting. For example:
<sometag>
SOME FREE TEXT
<afield>A text but data</afield>
MORE FREE TEXT
</sometag>
This data will be stored anyway, only that it will be marked using the extra field
dataOrigin which will reflect all these cases.
From the parser source code:
DATA_PLACE_ATTRIBUTE = 'A'; // as attribute e.g. <a myAtt="data"> ... </a>
DATA_PLACE_VALUEATT = 'V'; // as "value" attribute e.g. <a myAtt="xyz">data</a>
DATA_PLACE_FREETEXT = 'X'; // unstructured text e.g. <a> data <b> ... </b> data </a>
DATA_PLACE_TAGVALUE = 'D'; // normal data e.g. <a> data </a>
And this is pretty much the essence of the XMeLon basis schema, this ideal -
naive if you want - schema consists on just one table.
CREATE TABLE xmelon_data (layerCounter, //instance or unique id for the layer
layerParentCounter, //parent's layer counter
layerFullName, //layer=XML path except the last tag
layerName, //last tag of the layer
dimensionName, //specific layer's dimension
dataOrigin, //origing of data: A, V, X or D
dataValue); //data value
To be able to store multiple files as well as for a couple of other technical reasons the schema has to be extended. Nevertheless
we keep using the ideal schema, not only for clarity on the explanation but also because it might result useful in simple cases.
Before entering in the details of the parser, which only needs the basis schema, let us complete the more theoretical part and see how
the content schema can be built from a parsed XML content.
Where are the tables? (Building the content schema)
The content schema are the tables that reflect the records contained in the XML file. Since these are dependent on the content
it make sense that we build it in a separate process after having all the data stored in the basis schema. The schema can be built
completely using just few SQL statements.
Let us start with the most simple SQL statement, the one which provides the name of the content tables. These tables are nothing but
the layers that we have defined, so one SELECT and its result for that can be:
SELECT layerFullName AS tableName FROM xmelon_data GROUP BY layerName
tableName
-------------------
shelf
shelf/contents/cd
Beautifying the table names and getting all column names as well can be done with:
SELECT "t"||REPLACE(layerFullName, '/', '_') AS tableName,
"c_"||dimensionName AS columName
FROM xmelon_data
WHERE layerCounter+0 > 0
GROUP BY layerFullName, dimensionName
tableName |columName
t_shelf |c_name
t_shelf |c_owner
t_shelf_contents_cd |c_author
t_shelf_contents_cd |c_title
t_shelf_contents_cd |c_year
This can be used to create all content tables empty but also for something much more interesting : generate a SQL statement
for each table that will return all the records at once. This is actually the key step in the XMeLon approach.
Without having this possibility the basis schema database alone would be just a raw container and the goal of extracting the content in a well structured way could not be achieved.
The records we are looking for are contained in each layer instance, so grouping by
layerCounter the table xmelon_data for a specific layer (=content table)
gives as many rows as records the content table has. Now within this group we have to find the values of all columns. For that, we apply the following SQL expression
for each dimension
MAX (SUBSTR (value, 1, LENGTH(value) * (dimensionName = "xxxxxxx"))) AS c_xxxxxxx
where xxxxxxx has to be replaced by the dimension name. Maybe this is not the only solution but since it
has performed so well (I have to confess: surprisingly to me!) the expression is kept until now.
The complete SQL to build the table shell_conten_cd then is:
SELECT
layerCounter,
parentLayerCounter,
MAX (SUBSTR (value, 1, LENGTH(value) * (dimensionName = "author"))) AS c_author,
MAX (SUBSTR (value, 1, LENGTH(value) * (dimensionName = "title"))) AS c_title,
MAX (SUBSTR (value, 1, LENGTH(value) * (dimensionName = "year"))) AS c_year
FROM xmelon_data
WHERE layerFullName = '/shelf/contents/cd'
GROUP BY layerCounter ;
layerCounter|parentLayerCounter|c_author |c_title |c_year
5 |1 |Bob Dylan |Blood on the tracks |
8 |1 |David Bowie |The man who sold the world |1971
12 |1 |Pau Riba |Dioptria |1971
Now if we apply the select to a "CREATE TABLE ... AS <select>" or "CREATE VIEW ... AS <select>" we can create directly the content table
or just create a view for it, that which were most convenient for the application. Using views the content schema is kept more flexible
to new or updated content and tables might result much more performing since tables can be indexed.
At this point we are able to generate and populate with data all content tables. Not bad but it is still possible to
squeeze the orange more, or in our case the xmelon_data. Just with a single SQL
SELECT we can obtain all parent-child relationships
between the content tables. As mentioned at the beginning, the article The Deep Table gives
more details about how this information can be used to generate automatically useful
SELECT joins.
To get the connections it is enough to join xmelon_data with itself using
layerCounter and layerParentCounter like:
SELECT
REPLACE(parent.layerName, '/', '') AS connName,
'v'||REPLACE(parent.layerFullName, '/', '_') AS tableSource,
'parentLayerCnt' AS fieldSource,
'v'||REPLACE(child.layerFullName, '/', '_') AS tableTarget,
'layerCnt' AS fieldTarget
FROM
xmelon_data AS child, xmelon_data AS parent
WHERE parent.layerCounter+0 > 0 AND
parent.layerCounter+0 = child.parentLayerCounter+0
GROUP BY child.layerFullName
ORDER BY tableSource, connName ;
connName |tableSource |fieldSource |tableTarget |fieldTarget
shelf |v_shelf |parentLayerCnt |v_shelf_contents_cd |layerCnt
For the final basis schema this SQL is larger because fileID has to be included as key field in all connections but it still
can be done in just one select.
As last note just mention that the field "layerName" might have, depending on the XML schema to treat,
more uses. For instance, in many cases it can replace layerFullName in all above SQLs of the content schema. That would be
especially useful when the XML schema admits composition of structures. This is a special and more advanced use of the XMeLon schema that we will not cover here.
The XMeLon parser
The XMeLon parser will create and populate the basis schema from one or a set of XML files. It is universal in the sense that it does
not depend on the XML schema, thus it only has to be developed once. We provide parsers for both, the ideal basis schema and the final one, but
give more detailed explanation only for the first one. Anyway, inspecting the differences between the two parsers using some diff tool
should be illustrative enough to understand the final parser as well.
It is developed in Java since this language offers many useful libraries by default. For instance our implementation uses the SAX parser
org.xml.sax.XMLReader.
The main class of the parser is called xmelonIdealParser, on it an object of type
XMLReader will read and take care of the syntax validity
of the XML file. The constructor initializes it as shown in the code below and the method
parseFile call its method parse,
from this moment the XMLReader object will read and recognize the XML elements and data and it will:
- call the callback method
startElement each time a tag is opened, providing the attributes if any - call the callback method
characters each time it founds data - call the callback method
endElement each time a tag is closed
These are the methods from the Java interface org.xml.sax.ContentHandler that our parser has to implement.
Additionally we extend the class org.xml.sax.DefaultHandler to have some other required implementations done by default
and implement the interface EntityResolver to avoid some exceptions when a XML file requires this feature but for our purpose
a dummy implementation of resolveEntity is enough.
The code related with XMLReader is:
import javax.xml.parsers.*;
import org.xml.sax.*;
import org.xml.sax.helpers.*;
public class xmelonIdealParser extends DefaultHandler implements ContentHandler, EntityResolver
{
...
private XMLReader saxParserReader = null;
public xmelonIdealParser ()
{
try
{
saxParserReader = ( (SAXParserFactory.newInstance ()).newSAXParser () ).getXMLReader();
saxParserReader.setContentHandler (this);
saxParserReader.setEntityResolver (this);
}
catch (Exception e) ;
}
public void parseFile (String fileName)
{
...
try
{
saxParserReader.parse (new org.xml.sax.InputSource (fileName));
}
catch (Exception e) ;
}
public void startElement (String namespace, String localname,
String type, Attributes attributes) throws SAXException
public void endElement (String namespace, String localname, String type) throws SAXException
public void characters (char[] ch, int start, int len)
public InputSource resolveEntity (String publicId, String systemId)
Before looking at the implementation of the XMLReader callbacks (startElement, etc.) we need two more classes. As seen in
the basis schema, we want to separate the path in layer and dimension and track instance and parent instance of all layers.
All this is achieved in the parser by using a stack of XML elements (tags) with the information we need. The class that will
represent the XML element as we need is xmelonSaxElement:
public class xmelonSaxElement
{
public xmelonSaxElement ()
{
}
public xmelonSaxElement (String pTagName, long pLayerCounter, long pLayerParentCounter)
{
tagName = pTagName;
layerCounter = pLayerCounter;
layerParentCounter = pLayerParentCounter;
}
public String tagName = "?";
public long layerCounter = 0;
public long layerParentCounter = 0;
public boolean hasData = false;
public boolean hasAttribute = false;
}
A particular xmelonSaxElement in the stack will represent a specific layer instance, therefore apart from the tagName
we give on its construction we have also counters for the layer and for the parent layer. The Sax element will also track if
some record or some attribute has been stored in the layer instance, especially the first flag is important to avoid creating artificial
content tables having only link information which is very common in XML because of the verbosity of nodes.
Then the class xmelonSaxElementStack is just a stack of elements xmelonSaxElement offering the
typical methods push, pop, size, elementAt and two more methods to build layerFullName and
layerName based on the elements in the stack.
With the information of this stack and three values more: dimensionName, dataOrigin and dataValue we have all necessary to store a
record of xmelon_data. This is done by the method outData. The methods related with SQL output are:
private xmelonSaxElementStack eleStack;
private void out (String str)
{
System.out.println (str);
}
protected void startSQLScript ()
{
out ("CREATE TABLE xmelon_data (layerCounter,
parentLayerCounter, layerName, dimensionName, valueOrigin, value);");
out ("INSERT INTO TABLE xmelon_data VALUES (0, 0, '/', '', '', '', '');");
out ("BEGIN TRANSACTION;");
}
private void outData (String dimensionName, char dataPlace, String value)
{
xmelonSaxElement last = eleStack.lastElement ();
last.hasData = true;
out ("INSERT INTO xmelon_data VALUES ("
+ last.layerCounter + ", "
+ last.layerParentCounter + ", '"
+ eleStack.getFullLayerName () + "', '"
+ eleStack.getLayerName () + "', '"
+ dimensionName + "', '"
+ dataPlace + "', '"
+ strUtil.escapeStr(value) + "');"
);
}
protected void endSQLScript ()
{
out ("COMMIT TRANSACTION;");
}
The parser just prints out SQL statements for the creation and population of the database. The output can be redirected to a file
and be used as input for the SQL engine, in our case SQLite. Or simply do all in just one command line, for example:
java -cp . xmelonIdealParser myfile.xml | sqlite3 myXmelon.db
This would parse the XML file generate myfile.xml and generate from it the
SQLite database myXmelon.db.
The use of the SQL engine SQLite is useful and very convenient not only because it is free, open source and public domain but
also because of its typeless concept (do not have to define each field type) that permits to be concentrated only in the aspects of SQL
that are really productive. Also we do not have at the end a database schema with arbitrary limitations on the values the fields can admit which hardly can be useful.
Now let us examine the callback methods. The method startElement basically push a new xmelonSaxElement into the stack
and stores the element attributes if any.
public void startElement (String namespaceURI, String localname,
String qName, Attributes attributes) throws SAXException
{
lastWasClosingTag = false;
storeTextDataIfAny ();
xmelonSaxElement xElem = new xmelonSaxElement(qName,
(currentLayerCounter ++),
getLayerParentCounter ());
xElem.hasAttribute = attributes.getLength () > 0;
eleStack.pushElement (xElem);
if (attributes.getLength () > 0)
for (int ii = 0; ii < attributes.getLength (); ii ++)
outData (attributes.getQName (ii),
DATA_PLACE_ATTRIBUTE,
attributes.getValue (ii));
}
The method characters just add data to a member variable.
public void characters (char[] ch, int start, int len)
{
currentStrData += (new String (ch, start, len)).trim ();
}
Finally the method endElement basically stores the data of the element doing a special check for the "anonymous field".
That would appear for example in the XML construction:
<sometag att1="valatt1">
some data
</sometag>
sometag is a layer since it has a dimension given in the attribute att1, but what is some data?
It has no dimension name.
The parser treats it as an anonymous field and gives it the dimension name "sometag_value".
Only in the "normal" case, when the field is given within a explicit tag, the stack has to be popped before storing the value in order to have
it at the layer position.
public void endElement (String namespace, String localname, String type) throws SAXException
{
if (lastWasClosingTag)
{
storeTextDataIfAny ();
eleStack.popElement ();
}
else
{
if (currentStrData.length () > 0)
{
if (eleStack.lastElement ().hasAttribute)
{
outData (type + "_value", DATA_PLACE_VALUEATT, currentStrData);
eleStack.popElement ();
}
else
{
eleStack.popElement ();
outData (type, DATA_PLACE_TAGVALUE, currentStrData);
}
}
else eleStack.popElement ();
}
currentStrData = "";
lastWasClosingTag = true;
}
The case of free text is checked in both methods startElement and endElement. Let us repeat our free text sample:
<sometag>
SOME FREE TEXT
<afield>A text but data</afield>
MORE FREE TEXT
</sometag>
On starting <afield> we have some data, thus it is free text. When finishing </sometag> we have some data
and the last operation was also closing a tag (</afield>), therefore the data is free text.
Final XMeLon schema and parser
Now we will develop the final XMeLon basis schema based on the ideal one.
To support multiple input files we add a new table for the source files and a new column fileID in the table xmelon_data to reference
the file the data belongs to.
CREATE TABLE xmelon_files (fileID, timeParse, fullPath);
CREATE TABLE xmelon_data (fileID, layerCounter, ...);
Layer and dimension names, in particular layer name, can be large and it would be inefficient to store it repeatedly. Also these names
might contain punctuation characters and other symbols that would be not accepted in a table or column name, so we have to convert them
previously to a valid names. We can model this by adding two more tables, one for dimension and one for layer, and replacing its values in xmelon_data with
references to the tables. So finally the complete XMeLon basis schema is:
CREATE TABLE xmelon_files (fileID, //unique id of the file
timeParse, //date time when the file was parsed
fullPath); //full path of the file parsed
CREATE TABLE xmelon_layerDef (layerID, //layer's unique id
layerParentID, //layer's unique id of the parent layer
layerFullNameRaw, //layer full name as given in the xml file
layerFullName, //layer full name as feasible name
layerName); //layer last name as feasible name
CREATE TABLE xmelon_dimensionDef (dimensionID, //dimension's unique id
dimensionNameRaw, //dimension's name as given in the xml file
dimensionName); //dimension's name as feasible name
CREATE TABLE xmelon_data (fileID, //file unique id
layerCounter, //layer instance to which the data belongs
layerParentCounter, //layer instance of the parent layer
layerID, //reference to the layer in table xmelon_layerDef
dimensionID, //reference to the dimension in table xmelon_dimensionDef
dataOrigin, //data origin 'A' attribute, 'X' free text, 'V' tag value, 'D' data
dataValue); //data value
Finally, in order to avoid conflicts with special characters in our parser as well as to support
Unicode,
all values and names will be encoded in the database. For that is enough to use the method
java.net.URLEncoder.encode, logically
the method java.net.URLEncoder.decode has to be used when reading the database.
Conclusions
The XMeLon schemas and parser not only store XML files into a database but literally extract and build in a way of
tables and relationships the structures contained in the these files. If all this work is done automatically then an application
has only to make use of the powerful SQL features like sorting, filtering and grouping to do whatever is needed with the data.
If the XML system uses multiple files and/or different XML schemas then the advantage of using the XMeLon approach is even more noticeable.

