Introduction
The purpose of this post is to describe a Sudoku solver web application (can be run from here) and its associated progressive search algorithm. Progressive search is a randomized iterative search algorithm that the author has developed and found to be effective for a variety of optimization problems. These include, among others, crossword generation and finding large-size magic squares (a 200×200 magic square can be found in about 3 minutes); more information on this can be found at my activities page and my book on algorithms, Algorithms: Development and Programming.
Sudoku is a logic puzzle that has become popular in recent years. The puzzle is normally of interest to people looking to challenge their logic skills. The puzzle uses a 9×9 square grid that is composed of nine 3×3 sub-squares (boxes). The solver's job is to place the digits 1-9 into the cells of the grid in such a way that each digit occurs just once in each row, once in each column, and once in each 3×3 box. A typical Sudoku puzzle may have 20 to 35 initially-filled cells, depending on the level of difficulty. A Sudoku solver is supposed to find the missing digits that can be assigned to the vacant cells.
How to use the Sudoku Solver
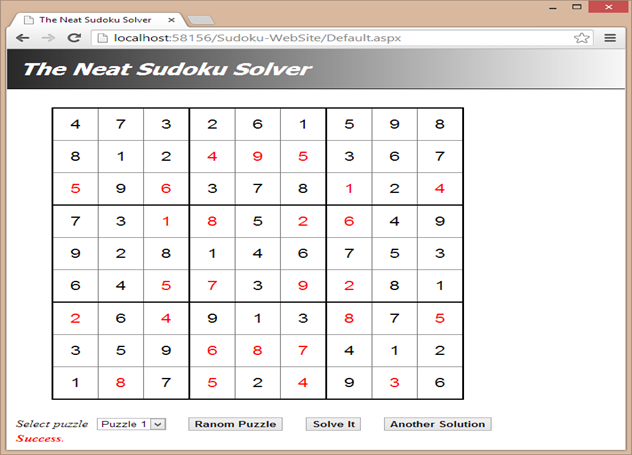
As seen from the interface exhibited in the above figure, there are three ways to input a Sudoku puzzle.
- Select a puzzle from the drop-down list.
- Generate a random puzzle by clicking the "Random Puzzle" button.
- Type in the digits for the fixed cells in the displayed puzzle grid.
The solver will try for about 20 seconds to find a final (or approximate) solution. Regardless of the returned solution being final or approximate, the "New Solution" button can be clicked to try to solve the same puzzle again.
Application Structure
Our Sudoku solver is an ASP.NET web site composed of the ASPX file "default.aspx" with code-behind C# code file "default.aspx.cs".
The HTML/JavaScript/CSS in the ASPX file provides the user-interface and handles the user actions. The client-side code is somewhat large because it avoids postback wherever possible; it only posts back to get a solution to the current Suduko puzzle. The event-handling code on the server is kept to a minimum and the viewstate is disabled.
Note: To keep the article to a reasonable size, no explanation of the client-side code is given.
The following listing shows the starting part of the server-side code.
protected void Page_Load(object sender, EventArgs e)))
{ if (Request["PuzzleData"] == null) return;
Server.ScriptTimeout = 30;
Sudoku mySudoku = new Sudoku(); int[,] grid = null;
int AllotedTime = 20;
int Cost = mySudoku.SolveIt(Request["PuzzleData"], AllotedTime, out grid);
mySudoku = null;
outData.InnerText = GridToString(grid);
outCost.InnerText = Cost.ToString();
}
string GridToString(int[,] grid)
{ string str = "";
for (int i = 0; i < 9; i++)
{ for (int j = 0; j < 9; j++)
{ str += grid[i, j]; }
}
return str;
}
As can be easily seen from the preceding code, a Sudoku puzzle is solved by the call to mySudoku.SolveIt(), where mySudoku
is a reference to an instance of Sudoku class. The method's first parameter is an input string (encoding of a Sudoku puzzle) of length 81 consisting of the digits 0-9 (0 means the corresponding cell is empty). The AllotedTime parameter is for the maximum time used for finding a solution. The last parameter (out parameter) is a 2-d array (grid) that encodes the solution to the puzzle. The grid is converted to a string by calling the method GridToString(). The Cost value returned is a non-negative integer that indicates the cost (violations) in the returned solution — a cost of zero means the returned solution is optimal (free of conflicts). Finally the solution is saved as the content of some HTML divisions for access by client-side code.
The method SolveIt() embodies the progressive search algorithm for solving the input Sudoku puzzle. The details of this method is given in a later section of the article.
Random Search Heuristics
Random search heuristics have been an active research area for many years. This has resulted in the development of various meta-search frameworks. These include tabu search, simulated annealing, genetic algorithms, variable neighborhood search and other iterative local search (ILS) heuristics collectively known as greedy randomized adaptive search procedures (GRASP).
A common characteristic to random search algorithms is that they are non-deterministic
— a decision on which search path to pursue next is often determined at random.
Thus, a random search algorithm often produces a different solution on each run. Although they are not guaranteed to find the optimal solution, random search algorithms can often find close-to-optimal solutions quickly.
What is Progressive Search?
The following listing shows progressive search algorithm expressed in pseudocode.
void ProgressiveSearch()
{ PQueue = new PriortyQueue();
NBSIZE = 50;
Threshold = some value;
smallThreshold = some value;
Let X be an initial solution;
BestX = X;
BestCost = f(X);
PQueue.Enqueue(X,f(x));
while (PQueue not empty)
{ X = PQueue.Dequeue();
nbcount =0;
while (nbcount < NBSIZE)
{ if (TimeElapsed > MaximumAllowedTime) return;
X1 = NewSolution(X);
nbcount = nbcount+1;
if (f(X1) < BestCost)
{ BestX = X1;
BestCost = f(X1);
if (BestCost == 0) return;
X = X1; nbcount = 0;
}
else if (f(X1) <= BestCost + smallThreshold)
{ PQueue.Enqueue(X1, f(X1));
X = X1; nbcount = 0;
}
else if (f(X1) <= BestCost + Threshold)
{ PQueue.Enqueue(X1, f(X1)); }
}
}
}
The basic idea of progressive search is to keep (in a priority queue) a set of solutions that are within some threshold (the Threshold parameter) of the current best solution for further mutation by the NewSolution() method. The algorithm generates and enqueues a maximum of NBSIZE (neighborhood size) solutions around the current solution but if a better solution (or a solution that is very close to the current best solution) is found then the current solution is reset to the newly found solution.
Progressive search has one distinguishing characteristic (the reason for coining this name):
The current solution is immediately reset to any newly found solution
that has the same cost (or a very close cost, i.e., within the smallThreshold) as the current best solution.
This has been found to accelerate the progress toward better solutions.
A possible explanation for this behavior is the following. A call to NewSolution() moves into the solution space by a tiny step which makes it unlikely to beat the current best solution; however, the chance of beating the current best solution is improved if moves are cascaded from several nearby solutions.
Favoring the exploration of solutions whose cost is equal to the current best is a feature of hill climbing (greedy) algorithms, except that in hill climbing the set is limited in size to one solution
(namely, the current best solution).
A Priority Queue for All Seasons
A priority queue is suited for use by iterative search because we can utilize a priority measure to rank the solutions found thus far. Using a minimizing priority queue (we use a min-heap), we can simply use the penalty cost function f(X) as the priority of X. This way, we favor exploring solutions that are near to the current best solution. Experiments show that progressive search, as given above, performs well for large-size optimization problems such as finding a maximum independent set or minimum coloring. However, the experiments also show that the rate of progress toward the optimal solution is highly dependent on the threshold and often calls for experimenting with different settings over several runs. In what follows, we propose a mechanism to:
(1) avoid the queue becoming large, and
(2) avoid using a threshold parameter.
To prevent the queue from growing large, we make use of a MaxSize property;
if set, then the queue will never have more than MaxSize items. To avoid the use of threshold, we employ a trick. We want the queue to contain items (solutions) that are within certain threshold of the “best” item found thus far. We will insert the items in “reverse” of priority (the user simply use the "negative of cost" as priority). This way, the worst item will be at the root of the queue. To implement this behavior, we only modify the enqueue operation as follows: if an item X to be enqueued is having priority worst than the root and the current number of items in the queue is equal to MaxSize then X is not inserted; otherwise, X is inserted (if there is no room then the root item is dequeued first).
The following listing shows a streamlined version of progressive search utilizing a fixed-size queue and avoiding the use of Threshold parameter. Note that the last else-if block in the preceding version is now removed. Most of the time, the smallThreshod parameter can be set to 0 (i.e., removed); it is kept for generality.
void ProgressiveSearch()
{ PQueue = new PriortyQueue();
PQueue.MaxSize = 20;
NBSIZE = 50;
smallThreshold = some value;
Let X be an initial solution;
BestX = X; BestCost = f(X);
PQueue.Enqueue(X,-f(X));
while (true)
{ X = PQueue.RandomItem();
nbcount =0;
while (nbcount < NBSIZE)
{ if (TimeElapsed > MaximumAllowedTime) return;
X1 = NewSolution(X);
nbcount = nbcount+1;
PQueue.Enqueue(X1,-f(X1));
if (f(X1) < BestCost)
{ BestX = X1;
BestCost = f(X1);
if (BestCost == 0) return;
X = X1; nbcount = 0;
}
else if (f(X1) <= BestCost + smallThreshold)
{ X = X1; nbcount = 0; }
}
}
}
Note that because the worst element is at the root, we cannot use a dequeue operation to get a favorable element; instead, we use a call to RandomItem() to get a random element from the queue. Also, note that in this version of progressive search, we have eliminated the test for empty queue since the queue cannot become empty.
A Framework for Using Progressive Search
Progressive search is a meta-search algorithm. To be used for a particular problem,
we have to develop few other helper algorithms that go with it. In short, we have to implement the following steps:
- Specify the appropriate data structures to encode a solution.
- Specify the process of mutating a solution to obtain neighboring solutions.
- Define an appropriate penalty cost function that measures the quality
(closeness to optimal) of a solution.
To facilitate the above, it is appropriate to have a Solution class.
The class is used to encode a solution (good or bad) for the problem at hand; it consists of the following methods:
SetInitialSolution() to build and return an initial solution, ComputeMeasure()
to return the cost of a solution, NewSolution() to mutate a solution into a new solution.
The NewSolution() method exhibits the following typical structure:
Solution NewSolution()
{ Solution s1 = this.CopySolution();
return s1;
}
It starts with making a duplicate of the passed solution using a call to CopySolution().
This way we keep the old solution intact for future mutations. We then mutate the copy and compute its cost. For mutation, we normally use some simple random modification. For example, for finding an Independent Set of size k in a given graph G, we may encode a solution as a set S of vertices that is a potential candidate for an independent set. Then as a mutation of S, we randomly pick a vertex from S and swap it with another randomly selected vertex from outside of S.
To select the vertices in a systematic way, rather than randomly, we can pass nbcount to NewSolution() and use it for vertex selection (for example, the expression nbcount mod |S| identifies one vertex form S and the expression nbcount mod (|G|-|S|) identifies a vertex outside of S).
In regard to ComputeMeasure(), it is more efficient to compute it incrementally.
That is, since a new solution X is a mutation of an old solution X', then f(X) should be expressed in terms of f(X').
However, finding the right expression is generally involved; therefore, it is suggested that initially one should compute f in a straight-forward way (this is needed any way for the initial solution), and then try to optimize it later.
Solving Sudoku by Progressive Search
Our program code consists of the two classes (in App_Code folder): Sudoku class and Solution class. The Sudoku class consists primarily of the methods SolveIt(), which serves as the interface to the outside world, ProgressiveSearch() and few other helper methods/objects including a FixedCells array to encode the Sudoku puzzle.
The following shows the program code for the Solution class.
class Solution
{
Random rand;
internal int[,] grid = new int[9, 9];
internal float Cost;
int[] FixedCell;
internal Solution(int[] FixedCell, Random rand) { this.FixedCell = FixedCell; this.rand = rand; }
internal void SetInitialSolution()
{ for (int i = 0; i < 9; i++)
for (int j = 0; j < 9; j++)
{ grid[i, j] = j + 1; }
Cost = ComputeMeasure();
}
int ComputeMeasure()
{ int[] perm = new int[9];
int sum = 0;
for (int k = 0; k < 27; k++)
{ for (int i = 0; i < 9; i++) perm[i] = 0;
for (int i = 0; i < 9; i++) perm[grid[Sudoku.PosRow[k, i], Sudoku.PosCol[k, i]] - 1] += 1;
for (int i = 0; i < 9; i++)
{ if (perm[i] == 0) sum++;
else if (perm[i] > 1) sum += perm[i] - 1;
}
}
for (int i = 0; i < 81; i++)
if (FixedCell[i] != 0)
if (grid[i / 9, i % 9] != FixedCell[i]) sum = sum + 8;
return sum;
}
Solution CopySolution()
{ Solution s = new Solution(FixedCell,rand);
Array.Copy(grid, s.grid, grid.Length);
return s;
}
internal Solution NewSolution( )
{ Solution s1 = this.CopySolution();
int i = rand.Next(81);
int j = i;
while (i == j) { j = rand.Next(81); }
int t = s1.grid[i / 9, i % 9];
s1.grid[i / 9, i % 9] = s1.grid[j / 9, j % 9];
s1.grid[j / 9, j % 9] = t;
s1.Cost = s1.ComputeMeasure();
return s1;
}
}
The class uses the array grid[0..8,0..8] to store a solution to a 9-by-9 Sudoku puzzle.
For an initial solution, we fill each row with the digits 1 to 9.
For mutation of a solution, we simply pick two cells at random and swap their values. The penalty cost function implemented as the ComputeMeasure() instance method) essentially measures how close a solution is to a correct (i.e., free of conflicts) solution.
Let Ri (for i=0 to 8) denote the set of numbers placed in row i.
Likewise, let Cj [Bk] denote the set of numbers placed in column j [box k].
(Note: In specifying which row (column or box), we have the indices start from 0). In total there are 27 sets. These sets are defined in class Sudoku as (where PosRow [PosCol] gives the row [column] number):
internal static int[,] PosRow = new int[27,9];
internal static int[,] PosCol = new int[27,9];
static void SetRowColPos()
{
}
A correct solution must ensure that each of these sets contain the digits 1-9 and any violation contributes a cost of 1 toward the cost. This is taken care of by the first for-block in the ComputeMeasure() method. Furthermore, a correct solution must have certain cells filled with certain digits. For this, we use the FixedCell array defined as an instance member in the Sudoku class, where FixedCell[i]=j if the cell at position i is fixed to contain j and 0 otherwise. If a grid cell does not contain the specified digit then such a violation contributes a cost of 8 to the cost. This is taken care of by the second for-block.
By assigning a large cost value (for example, 100) for a fixed-cell violation, the algorithm is forced to have the fixed cells resolved early. However, this is found to slow down the algorithm. Also, the algorithm is slowed down if the initial solution has the fixed cells intact. This is a general observation, progressive search works better if the problem's constrains are enforced gradually instead of being enforced early.
Conclusions
The Sudoku solver is a good example demonstrating the effectiveness of progressive search. The solver was tested with popular browsers and found to work properly.
History
- 22th November, 2013: Version 1.0
License

