1. Table of Contents
- Table of Contents
- Introduction
- Installing the sample database
- Defining a query
- Our first query; the SELECT statement
- Eliminating duplicates; DISTINCT
- Filtering data; the WHERE clause
- 7.1. The NOT keyword
- 7.2. Combining predicates
- 7.3. Filtering strings
- 7.4. Filtering dates
- 7.5. The IN and BETWEEN keywords
- Sorting data; ORDER BY
- Further limiting results; TOP and OFFSET-FETCH
- 9.1. TOP
- 9.2. OFFSET-FETCH
- Aggregating data; GROUP BY and HAVING
- Selecting from multiple tables; using JOINS
- 11.1. CROSS JOIN
- 11.2. INNER JOIN
- 11.3. OUTER JOIN
- 11.4. Self JOIN
- 11.5. Multiple JOINS
- Multiple groups; GROUPING SETS
- 12.1. GROUPING SETS
- 12.2. CUBE
- 12.3. ROLLUP
- 12.4. GROUPING
- 12.5. GROUPING_ID
- Windowing functions; the OVER clause
- 13.1. Aggregate functions
- 13.2. Framing
- 13.3. Ranking functions
- 13.4. Offset functions
- That's not it yet...
Part II
- Table of Contents
- Welcome back!
- Queries in your queries; Subqueries
- Querying from subqueries; Derived tables
- Common Table Expressions a.k.a. CTEs
- Set operators; UNION, INTERSECT and EXCEPT
- Pushing over tables; PIVOT and UNPIVOT
- More uses for Table Expressions; APPLY
- Other aspects of querying
- Conclusions
2. Welcome back!
As you can read in the title of this article this is actually the second and last part of an article dedicated to querying a Microsoft SQL Server database. I strongly recommend that you read the first article, Querying SQL Server 2012 Part I, if you have not done so already.
The first article focused on building up your query. It started of simple with the SELECT statement and built up difficulty by adding filtering, grouping and windowing functions to your queries.
This second part of the article focuses on combining multiple SELECT statements and still returning a single result set. In addition we will see how to use functions and manipulate data so we can combine values from our database and apply functions to values.
3. Queries in your queries; Subqueries
So as I said this article will focus on using multiple SELECT statements within a query. The easiest and most common way to do this is by using a subquery. A subquery is a query within a query that returns a result that is expected at the place where the subquery is placed. Some of the windowing functions we used in part I of this article return results that could have been returned by using a subquery. Say we want to query the orders table and for each order we want to show the most expensive order and least expensive order as well. To get this result we could use the following query, as we have seen in part I.
SELECT
SalesOrderID,
SalesOrderNumber,
CustomerID,
SubTotal,
MIN(SubTotal) OVER() AS LeastExpensive,
MAX(SubTotal) OVER() AS MostExpensive
FROM Sales.SalesOrderHeader
ORDER BY SubTotal
We could get this same result using subqueries. The subquery returns a result for each row. So let me show you the above query rewritten with subqueries.
SELECT
SalesOrderID,
SalesOrderNumber,
CustomerID,
SubTotal,
(SELECT MIN(SubTotal)
FROM Sales.SalesOrderHeader) AS LeastExpensive,
(SELECT MAX(SubTotal)
FROM Sales.SalesOrderHeader) AS MostExpensive
FROM Sales.SalesOrderHeader
ORDER BY SubTotal
That is a lot more code to get the same result you might think. Besides, this method is more error prone than using a windowing function. What if we would forget our aggregate function? The subquery would return all subtotals from the order table, but we cannot put more than one value in, well, a single value! See what happens for yourself. The error message is pretty clear I think.
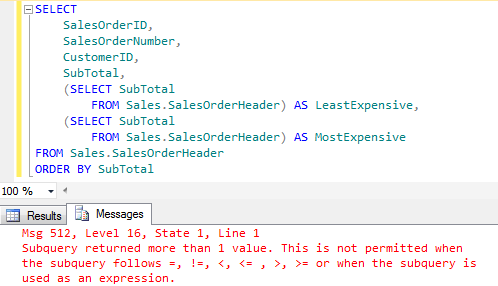
So if subquerying requires more code and is more error prone to boot then why would we use a subquery? Well, subqueries can be a lot more complex than I have just shown you. You can query anything from anywhere as long as it returns a result set that is expected at the place where you use it. In a SELECT statement that would be a single value. You could query from the Person table and still include the most and least expensive orders.
SELECT
BusinessEntityID,
Title,
FirstName,
MiddleName,
LastName,
(SELECT MIN(SubTotal)
FROM Sales.SalesOrderHeader) AS LeastExpensive,
(SELECT MAX(SubTotal)
FROM Sales.SalesOrderHeader) AS MostExpensive
FROM Person.Person
ORDER BY FirstName, MiddleName, LastName
Now that is already pretty neat, but wait, there is more. The subqueries I have just shown you are self-contained subqueries. That means the subquery can be executed without the outer query and still return a result. These can be useful, but a lot of the times you might want to select something based on a value of the outer query. In this case we can use correlated subqueries. That simply means that we use a value from our outer query in our subquery. Let us use the query above, but now show the least and most expensive orders for that particular person. Remember that a person does not make an order. A customer makes an order and a customer is linked to a person. We are going to need a join for this... Or another subquery!
SELECT
BusinessEntityID,
Title,
FirstName,
MiddleName,
LastName,
(SELECT MIN(SubTotal)
FROM Sales.SalesOrderHeader AS s
WHERE s.CustomerID = (SELECT
c.CustomerID
FROM Sales.Customer AS c
WHERE c.PersonID = p.BusinessEntityID)
) AS LeastExpensive,
(SELECT MAX(SubTotal)
FROM Sales.SalesOrderHeader AS s
WHERE s.CustomerID = (SELECT
c.CustomerID
FROM Sales.Customer AS c
WHERE c.PersonID = p.BusinessEntityID)
) AS MostExpensive
FROM Person.Person AS p
ORDER BY FirstName, MiddleName, LastName
Allright, now that is looking complex! It really is not. Both subqueries are the same except for the MIN and MAX functions, so focus on one subquery. Notice that I have used column aliases because CustomerID is a column in both SalesOrderHeader and Customer. So let us isolate the subquery and take a closer look at it. Note that you cannot run it, because it references a column from the outer query.
(SELECT MAX(SubTotal)
FROM Sales.SalesOrderHeader AS s
WHERE s.CustomerID = (SELECT
c.CustomerID
FROM Sales.Customer AS c
WHERE c.PersonID = p.BusinessEntityID)
) AS MostExpensive
So that is it. Notice that you can actually use a subquery in a WHERE clause? Now that is pretty cool! Remember that windowing functions cannot be used in any clause except ORDER BY. So in the WHERE clause we select the CustomerID from the Customer table where PersonID is equal to the BusinessEntityID from the outer query. So far so good, right? The CustomerID returned by the query is used to select the most (or least) expensive order from that customer from the SalesOrderHeader table. Notice that when the subquery does not return a value the row is not discarded, but a NULL is shown instead.
3.1 Writing the same queries differently
Here is a nice challenge, if you are up for it. Rewrite the last query using no subselects. There are actually multiple ways to tackle this. I used JOINS instead of subqueries. There are a lot of other methods as well, but they are not covered in this article or not covered yet. Here are two possible solutions, one using a GROUP BY clause and the same solutions, but using windowing and DISTINCT instead of GROUP BY.
SELECT
BusinessEntityID,
Title,
FirstName,
MiddleName,
LastName,
MIN(s.SubTotal) AS LeastExpensive,
MAX(s.SubTotal) AS MostExpensive
FROM Person.Person AS p
LEFT JOIN Sales.Customer AS c ON c.PersonID = p.BusinessEntityID
LEFT JOIN Sales.SalesOrderHeader AS s ON s.CustomerID = c.CustomerID
GROUP BY
BusinessEntityID,
Title,
FirstName,
MiddleName,
LastName
ORDER BY FirstName, MiddleName, LastName
SELECT DISTINCT
BusinessEntityID,
Title,
FirstName,
MiddleName,
LastName,
MIN(s.SubTotal) OVER(PARTITION BY s.CustomerID) AS LeastExpensive,
MAX(s.SubTotal) OVER(PARTITION BY s.CustomerID) AS MostExpensive
FROM Person.Person AS p
LEFT JOIN Sales.Customer AS c ON c.PersonID = p.BusinessEntityID
LEFT JOIN Sales.SalesOrderHeader AS s ON s.CustomerID = c.CustomerID
ORDER BY FirstName, MiddleName, LastName
So if all three queries return the same result which one should you use!? query optimization is outside the scope of this article, but I do want to mention this. You can see IO statistics by running the following statement in your query window.
SET STATISTICS IO ON
Next you can turn on the option 'Include actual query plan' under the 'Query' menu option.

Now run your query again. In the messages window you will see detailed IO information. As a rule of thumb goes the lesser reads the better. You will now also find a third window, the 'Execution plan', which shows exactly what steps SQL Server had to perform to get to your result. Read it from right to left. Less steps is not always better, some steps require more work from SQL Server than others.
So which query did actually perform best? The one with the GROUP BY. And which was worst (by far)? The one including the subqueries.
That does not automatically mean subqueries are slow or evil. It simply means there are more queries to get to the same result and what is best in one scenario is not always the best in another. In addition, sometimes subqueries can be used where other functions cannot be used.
3.2 More filtering options; IN, ANY, SOME, ALL and EXISTS
3.2.1 IN
I have already shown a subquery in a WHERE clause. You can use it to check if values are greater than, less than, like another value etc. The following query shows a somewhat lame example of using a subquery and the LIKE operator. It selects all people whos first name begins with a 'Z'.
SELECT *
FROM Person.Person
WHERE FirstName LIKE (SELECT 'Z%')
Now remember the IN function? It can actually take a range of values as input. We can easily combine that with a subquery. We just have to make sure our subquery returns a single column and whatever number of rows. So far we have only seen subqueries that return a single value. Let us say we want to find all people who are also a customer. If a Person is a Customer we know that there is a Customer with the PersonID of that Person. So the next query will easily solve this.
SELECT *
FROM Person.Person AS p
WHERE p.BusinessEntityID IN (SELECT PersonID
FROM Sales.Customer)
Which is equivalent to:
SELECT *
FROM Person.Person AS p
WHERE p.BusinessEntityID = x OR p.BusinessEntityID = y OR p.BusinessEntityID = z... etc.
And if we want to know which people are not a customer we use the keyword NOT. In this case we also have to check for NULL.
SELECT *
FROM Person.Person AS p
WHERE NOT p.BusinessEntityID IN (SELECT PersonID
FROM Sales.Customer
WHERE PersonID IS NOT NULL)
Remember that NULL can also be explained as UNKNOWN, so if a single NULL is returned from your subquery SQL Server returns no rows because it does not know if a value is or is not contained in the result. After all, it might be that NULL value. The previous query is equivalent to the following.
SELECT *
FROM Person.Person
WHERE BusinessEntityID <> x AND BusinessEntityID <> y AND BusinessEntityID <> z... etc.
3.2.2 ANY and SOME
The ANY operator works much like the IN operator, except in that you can use the >, <, >=, <=, = and <> operators to compare values. ANY returns true if at least one value returned by the subquery makes the predicate true. So the following query returns all persons except that with BusinessEntityID 1, because 1 > 1 returns FALSE.
SELECT *
FROM Person.Person
WHERE BusinessEntityID > ANY (SELECT 1)
In queries such as these ANY may not be that useful, even when you specifiy a more meaningful subquery. In some cases ANY can be useful though. For example if you want to know if all orders (from a specific date) have at least a certain status. The following query illustrates this.
DECLARE @OrderDate AS DATETIME = '20050517'
DECLARE @Status AS TINYINT = 4
IF @Status > ANY(SELECT Status
FROM Purchasing.PurchaseOrderHeader
WHERE OrderDate = @OrderDate)
PRINT 'Not all orders have the specified status!'
ELSE
PRINT 'All orders have the specified status.'
If @Status is bigger than any result from the subquery then the result is TRUE (because there are some/any orders that are not at least status 4. The query prints "Not all orders have the specified status!".
Instead of ANY you can use SOME, which has the same meaning.
DECLARE @OrderDate AS DATETIME = '20050517'
DECLARE @Status AS TINYINT = 4
IF @Status > SOME(SELECT Status
FROM Purchasing.PurchaseOrderHeader
WHERE OrderDate = @OrderDate)
PRINT 'Not all orders have the specified status!'
ELSE
PRINT 'All orders have the specified status.'
3.2.3 ALL
Unlike ANY, ALL looks at all results returned by a subquery and only returns TRUE if the comparison with all results makes the predicate true. The previous query could have been rewritten as follows.
DECLARE @OrderDate AS DATETIME = '20050517'
DECLARE @Status AS TINYINT = 4
IF @Status < ALL(SELECT Status
FROM Purchasing.PurchaseOrderHeader
WHERE OrderDate = @OrderDate)
PRINT 'All orders have the specified status.'
ELSE
PRINT 'Not all orders have the specified status!'
3.2.4 EXISTS
EXISTS can be used like ANY and ALL, but returns true only if at least one record was returned by the subquery. It is pretty useful and you will probably use this more often. Let us say we want all customers that have placed at least one order.
SELECT *
FROM Sales.Customer AS c
WHERE EXISTS(SELECT *
FROM Sales.SalesOrderHeader AS s
WHERE s.CustomerID = c.CustomerID)
Now we might be more interested in customers that have not placed any orders.
SELECT *
FROM Sales.Customer AS c
WHERE NOT EXISTS(SELECT *
FROM Sales.SalesOrderHeader AS s
WHERE s.CustomerID = c.CustomerID)
Notice that the EXISTS functions only returns TRUE or FALSE and not any columns. For that reason it does not matter what you put in your SELECT statement. In fact, this is the only place where you can use SELECT * without worrying about it!
4. Querying from subqueries; Derived tables
In the previous chapter we have seen subqueries. We have seen them in our SELECT statement, in our WHERE statement and passed as parameters to functions. You can put subqueries almost anywhere you want, including HAVING and ORDER BY clauses. This also includes the FROM clause.
When we use subqueries in our FROM clause the result is called a derived table. A derived table is a named table expression and, like a subquery, is only visible to its outer query. It differs from subqueries in that they return a complete table result. This can actually solve some problems we had earlier! Remember that we could not use windowing functions anywhere except in the ORDER BY clause? What if we selected the values first and then filtered them in an outer query? This is perfectly valid!
SELECT *
FROM (SELECT
SalesOrderID,
SalesOrderNumber,
CustomerID,
AVG(SubTotal) OVER(PARTITION BY CustomerID) AS AvgSubTotal
FROM Sales.SalesOrderHeader) AS d
WHERE AvgSubTotal > 100
ORDER BY AvgSubTotal, CustomerID, SalesOrderNumber
There are a few things you will have to keep in mind. The result of a subquery needs to be relational. That means every column it returns must have a name. AVG(SubTotal)... would not have a name, so we MUST alias it. We must also alias the derived table itself.
Also, a relation is not ordered, so we cannot specify an ORDER BY in the derived table. There is an exception to this last rule. Whenever you specify a TOP or OFFSET-FETCH clause in your derived table you can use ORDER BY. In this case the query will not return an ordered result, but it returns the top x rows that should be in the result IF the result was ordered. So the ORDER BY is used as a filter rather than ordering. The next query illustrates this.
SELECT *
FROM (SELECT TOP 100 PERCENT
SalesOrderID,
SalesOrderNumber,
CustomerID,
Freight
FROM Sales.SalesOrderHeader
ORDER BY Freight) AS d
And here is the result.
Notice that I am making a select on the entire table, because it is kind of hard to NOT have SQL Server return sorted data. In every other case it would have to sort the data first before it can check which rows should and should not be returned. And when the data is sorted SQL Server does not unsort them before returning the result. In this case a sort is not necessary because the entire table needs to be returned anyway. The bottom line here is that the ORDER BY did not actually order our result set.
The next query illustrates that the result MAY be ordered though.
SELECT *
FROM (SELECT TOP 10000
SalesOrderID,
SalesOrderNumber,
CustomerID
FROM Sales.SalesOrderHeader
ORDER BY CustomerID) AS d
And here are the results.
It may look like these results are ordered, but remember that SQL Server cannot guarantee ordering. In this case SQL Server needed to sort the rows on CustomerID before returning the rows. Just remember that ORDER BY in any relational result is used for filtering, not ordering.
One thing you can not do using derived tables is joining with the derived table. You might want to do something like I did in my example on self JOINs in part I of the article. This is not valid however.
SELECT *
FROM (SELECT
SalesOrderID,
SalesOrderNumber,
CustomerID,
AVG(SubTotal) OVER(PARTITION BY CustomerID) AS AvgSubTotal
FROM Sales.SalesOrderHeader) AS d
JOIN d AS d2 ON d2.CusomerID = d.CustomerID + 1
WHERE AvgSubTotal > 100
ORDER BY AvgSubTotal, CustomerID, SalesOrderNumber
This is NOT valid syntax and the only way you will be able to join on your derived table is by duplicating your derived table in your JOIN clause!
SELECT *
FROM (SELECT
SalesOrderID,
SalesOrderNumber,
CustomerID,
AVG(SubTotal) OVER(PARTITION BY CustomerID) AS AvgSubTotal
FROM Sales.SalesOrderHeader) AS d
JOIN (SELECT
SalesOrderID,
SalesOrderNumber,
CustomerID,
AVG(SubTotal) OVER(PARTITION BY CustomerID) AS AvgSubTotal
FROM Sales.SalesOrderHeader) AS d2 ON d2.CustomerID = d.CustomerID + 1
WHERE d.AvgSubTotal > 100
ORDER BY d.AvgSubTotal, d.CustomerID, d.SalesOrderNumber
Yikes! This also exposes another problem with derived tables and subqueries in general. They can make your query big, complex and difficult to read.
5. Common Table Expressions a.k.a. CTEs
Like derived tables a Common Table Expression, also commonly abbreviated as CTE, is a named table expression that is only visible to the query that defines it. The CTE makes up for some of the shortcomings of the derived table though. For starters, a CTE is defined at the beginning of your query, or actually at the top. This makes it more readable than a derived table. You first name and define your CTE and then work with it in a following query. The first example I showed using a derived table can be rewritten using a CTE.
WITH CTE
AS
(
SELECT
SalesOrderID,
SalesOrderNumber,
CustomerID,
AVG(SubTotal) OVER(PARTITION BY CustomerID) AS AvgSubTotal
FROM Sales.SalesOrderHeader
)
SELECT *
FROM CTE
WHERE AvgSubTotal > 100
ORDER BY AvgSubTotal, CustomerID, SalesOrderNumber
The syntax as clear and concise. But that is not all a CTE can do. You can use multiple CTEs and join them together in your final SELECT statement. The following is actually a case I have had a few times in production. We have a header and a detail table. The detail has some sort of total (a total price or weight) and the total of all lines is stored in the header. Somethimes things do not go the way they should and your header total does not actually reflect the total of all of your details.
WITH SOH
AS
(
SELECT
s.SalesOrderID,
s.SalesOrderNumber,
s.CustomerID,
p.FirstName,
p.LastName,
s.SubTotal
FROM Sales.SalesOrderHeader AS s
JOIN Sales.Customer AS c ON c.CustomerID = s.CustomerID
JOIN Person.Person AS p ON p.BusinessEntityID = c.PersonID
),
SOD AS
(
SELECT
SalesOrderID,
SUM(LineTotal) AS TotalSum
FROM Sales.SalesOrderDetail
GROUP BY SalesOrderID
)
SELECT *
FROM SOH
JOIN SOD ON SOD.SalesOrderID = SOH.SalesOrderID
WHERE SOH.SubTotal <> SOD.TotalSum
Notice a few things. The first CTE focuses on getting the data we need and performing necessary joins. The second CTE focuses on getting the sum for all salesorder details. The final query joins the two CTEs and filters only those where the total of the order is not equal to that of the details. We could have written this without CTEs. The following query shows how.
SELECT
s.SalesOrderID,
s.SalesOrderNumber,
s.CustomerID,
p.FirstName,
p.LastName,
s.SubTotal,
sd.SalesOrderID,
SUM(sd.LineTotal) AS TotalSum
FROM Sales.SalesOrderHeader AS s
JOIN Sales.Customer AS c ON c.CustomerID = s.CustomerID
JOIN Person.Person AS p ON p.BusinessEntityID = c.PersonID
JOIN Sales.SalesOrderDetail AS sd ON sd.SalesOrderID = s.SalesOrderID
GROUP BY
s.SalesOrderID,
s.SalesOrderNumber,
s.CustomerID,
p.FirstName,
p.LastName,
s.SubTotal,
sd.SalesOrderID
HAVING SUM(sd.LineTotal) <> s.SubTotal
So which one should you use? Actually it really does not matter. Both queries perform exactly the same in terms of reads. The only difference is that the query plan for the last query performs an extra step for the HAVING clause.
You could go crazy with CTEs and even perform your last join in a seperate CTE. This illustrates a nice use of CTEs. You can refer to a CTE within another CTE. The following query compiles to the exact same query as the one with 'only' two CTEs.
WITH SOH
AS
(
SELECT
s.SalesOrderID,
s.SalesOrderNumber,
s.CustomerID,
p.FirstName,
p.LastName,
s.SubTotal
FROM Sales.SalesOrderHeader AS s
JOIN Sales.Customer AS c ON c.CustomerID = s.CustomerID
JOIN Person.Person AS p ON p.BusinessEntityID = c.PersonID
),
SOD AS
(
SELECT
SalesOrderID,
SUM(LineTotal) AS TotalSum
FROM Sales.SalesOrderDetail
GROUP BY SalesOrderID
),
TOTAL AS
(
SELECT
SOH.SalesOrderID,
SOH.SalesOrderNumber,
SOH.CustomerID,
SOH.FirstName,
SOH.LastName,
SOH.SubTotal,
SOD.TotalSum
FROM SOH
JOIN SOD ON SOD.SalesOrderID = SOH.SalesOrderID
WHERE SOH.SubTotal <> SOD.TotalSum
)
SELECT *
FROM TOTAL
Unlike a derived table a CTE can be used in JOINs and can also make self JOINs. I still have no use case for self JOINs in AdventureWorks2012, so I will use the same example I used in part I, but this time using a CTE.
WITH CTE AS
(
SELECT
BusinessEntityID,
Title,
FirstName,
LastName
FROM Person.Person
)
SELECT
CTE1.BusinessEntityID AS CurrentID,
CTE1.Title AS CurrentTitle,
CTE1.FirstName AS CurrentFirstName,
CTE1.LastName AS CurrentLastName,
CTE2.BusinessEntityID AS NextID,
CTE2.Title AS NextTitle,
CTE2.FirstName AS NextFirstName,
CTE2.LastName AS NextLastName
FROM CTE AS CTE1
LEFT JOIN CTE AS CTE2 ON CTE2.BusinessEntityID = CTE1.BusinessEntityID + 1
ORDER BY CurrentID, CurrentFirstName, CurrentLastName
CTEs actually have another use within SQL, which is recursion. I will get to that in the next section.
6. Set operators; UNION, INTERSECT and EXCEPT
6.1 Combining sets; UNION and UNION ALL
There are a few operators that can be used to combine multiple result sets into a single set. The UNION operator is one of those. UNION takes two result sets and glues them together. There are two types of UNIONs, the UNION and the UNION ALL. The difference between the two is that UNION eliminates rows that are in both sets (duplicates that is) while UNION ALL keeps these rows. The following example makes clear how to use UNION and UNION ALL and what the difference is.
SELECT TOP 1
BusinessEntityID,
Title,
FirstName,
MiddleName,
LastName
FROM Person.Person
UNION
SELECT TOP 2
BusinessEntityID,
Title,
FirstName,
MiddleName,
LastName
FROM Person.Person
ORDER BY BusinessEntityID
And the result.
Notice that we actually selected a total of three records, yet the result shows only two. That is because the first record was eliminated by the UNION because all attributes had the same value (they were duplicates). Notice that NULLs are considered as equal.
If we wanted to keep that third row we could use UNION ALL.
SELECT TOP 1
BusinessEntityID,
Title,
FirstName,
MiddleName,
LastName
FROM Person.Person
UNION ALL
SELECT TOP 2
BusinessEntityID,
Title,
FirstName,
MiddleName,
LastName
FROM Person.Person
ORDER BY BusinessEntityID
This time the duplicate row was not discarded from the result.
A UNION operator can work on any two sets that have the same number of columns with the same type at each column index.
SELECT
'Sales order' AS OrderType,
SalesOrderID AS OrderID,
SalesOrderNumber,
CustomerID AS CustomerOrVendorID,
SubTotal,
NULL AS RevisionNumber
FROM Sales.SalesOrderHeader
WHERE SubTotal < 2
UNION
SELECT
'Purchase order',
PurchaseOrderID,
NULL,
VendorID,
SubTotal,
RevisionNumber
FROM Purchasing.PurchaseOrderHeader
WHERE RevisionNumber > 5
ORDER BY OrderType, OrderID
As you can see we can select from any two tables, but the number of columns must be the same for both queries, as well as the type of the returned value (text, numeric, date, etc).
Other than that there are a few things to notice. The column names of the first query are used. For columns that are not applicable in the current select we can use NULLs (or any other value of the correct type) as placeholders. Each query has its own WHERE clause (and any other clauses) except ORDER BY. ORDER BY is placed at the end to order the entire result set.
You can use more than one UNION to combine even more sets. The following query adds an additional row for each order types total subtotal.
SELECT
'Sales order' AS OrderType,
SalesOrderID AS OrderID,
SalesOrderNumber,
CustomerID AS CustomerOrVendorID,
SubTotal,
NULL AS RevisionNumber
FROM Sales.SalesOrderHeader
WHERE SubTotal < 2
UNION
SELECT
'Purchase order',
PurchaseOrderID,
NULL,
VendorID,
SubTotal,
RevisionNumber
FROM Purchasing.PurchaseOrderHeader
WHERE RevisionNumber > 5
UNION
SELECT
'Sales order total',
NULL,
NULL,
NULL,
SUM(SubTotal),
NULL
FROM Sales.SalesOrderHeader
WHERE SubTotal < 2
UNION
SELECT
'Purchase order total',
NULL,
NULL,
NULL,
SUM(SubTotal),
NULL
FROM Purchasing.PurchaseOrderHeader
WHERE RevisionNumber > 5
ORDER BY OrderType, OrderID
6.2 Recursion with CTEs and UNION ALL
I already mentioned that CTEs can be used for recursive functions. Remember the self JOIN example from part I? An Employee might have a ManagerID which refers to another Employee. Of course any manager can have his own manager all the way up to the top manager. There is no way for us to tell how many managers are up the hierarchy. For this we can use recursion. Just give us the manager of the manager of the manager... up to the point where a manager has no manager. This can be achieved using UNION ALL. Such a recursive CTE consists of two or more queries, one being the anchor member and the other as the recursive member. The anchor member is invoked once and returns a relational result. The recursive member is called until it returns an empty result set and has a reference to the CTE.
Unfortunately I have no use case for recursion in AdventureWorks2012 so I am just going to use recursion to select any Person from the Person table with a BusinessEntityID that is one lower than the previous until there is no ID that is one lower anymore
WITH REC AS
(
SELECT
BusinessEntityID,
FirstName,
LastName
FROM Person.Person
WHERE BusinessEntityID = 9
UNION ALL
SELECT
p.BusinessEntityID,
p.FirstName,
p.LastName
FROM REC
JOIN Person.Person AS p ON p.BusinessEntityID = REC.BusinessEntityID - 1
)
SELECT *
FROM REC
And here is the result for running this query for BusinessEntityID 9.
And to prove this really works, here is the result of the same query, but with BusinessEntityID 1704. It stops at 1699 because appearently there is no Person with a BusinessEntityID of 1698.
A small word of caution: the maximum recursion in SQL Server is 100. So the following query will run without problems.
WITH REC AS (
SELECT 100 AS SomeCounter
UNION ALL
SELECT SomeCounter - 1
FROM REC
WHERE SomeCounter - 1 >= 0
)
SELECT *
FROM RECAdding one will result in an overflow though!
Using the query hint MAXRECURSION can help overcome this limitation. The following query will run fine again (up to 200 recursion depth).
WITH REC AS (
SELECT 101 AS SomeCounter
UNION ALL
SELECT SomeCounter - 1
FROM REC
WHERE SomeCounter - 1 >= 0
)
SELECT *
FROM REC
OPTION (MAXRECURSION 200)
6.3 INTERSECT
INTERSECT is another set operator and the syntax and rules are the same as that of the UNION operator. The difference between the two is the results that are returned. UNION returns all rows and discards duplicate rows. INTERSECT returns only duplicate rows (once). Let us take the first example I used for UNION, but replace the UNION with an INTERSECT.
SELECT TOP 1
BusinessEntityID,
Title,
FirstName,
MiddleName,
LastName
FROM Person.Person
INTERSECT
SELECT TOP 2
BusinessEntityID,
Title,
FirstName,
MiddleName,
LastName
FROM Person.Person
ORDER BY BusinessEntityID
Since only the TOP 1 record is returned by both queries this is also the result that INTERSECT returns.
Like with UNIONs in INTERSECT NULLs are considered as equal.
6.4 EXCEPT
EXCEPT is the third set operator and the syntax and rules are also the same as for that of the UNION operator. EXCEPT returns only the records from the first query that are not returned by the second query. In other words, EXCEPT returns rows that are unique to the first query. We should notice here that with UNION and INTERSECT it does not matter which query comes first and which query comes second, the result remains the same. With EXCEPT the order of queries does matter. I will show this by using the same example I used for UNION and INTERSECT, but use EXCEPT instead. The following query returns no rows.
SELECT TOP 1
BusinessEntityID,
Title,
FirstName,
MiddleName,
LastName
FROM Person.Person
EXCEPT
SELECT TOP 2
BusinessEntityID,
Title,
FirstName,
MiddleName,
LastName
FROM Person.Person
ORDER BY BusinessEntityID
No rows were returned because the first query returned no rows that were not returned by the second query. Now let us switch the TOPs. The second row is now only returned by the first query.
SELECT TOP 2
BusinessEntityID,
Title,
FirstName,
MiddleName,
LastName
FROM Person.Person
EXCEPT
SELECT TOP 1
BusinessEntityID,
Title,
FirstName,
MiddleName,
LastName
FROM Person.Person
ORDER BY BusinessEntityID
In this query a result is returned.
You can use UNION, INTERSECT and EXCEPT in the same query. In this case INTERSECT takes precedence over UNION and EXCEPT. UNION and EXCEPT are considered equal and are performed in the order in which they appear.
7. Pushing over tables; PIVOT and UNPIVOT
7.1 Pivoting
Pivoting and unpivoting are specialized cases of grouping and aggregating data. Pivoting is the process of creating columns from rows while unpivoting is the process of creating rows from columns. We start with pivoting data. For example, we want to know the total subtotal that customers ordered grouped by sales person. However, for some reason we want to make columns out of the sales persons. So we'd get the columns CustomerID, SalesPerson1, SalesPerson2, etc. and the rows showing the ID for a customer and then the total subtotal ordered for SalesPerson1, SalesPerson2, etc. This is exactly what the PIVOT operator is for. To understand this better let us look at an example.
WITH PivotData AS
(
SELECT
s.CustomerID,
s.SalesPersonID AS SpreadingCol,
s.SubTotal AS AggregationCol
FROM Sales.SalesOrderHeader AS s
)
SELECT
CustomerID,
[274] AS StephenJiang,
[275] AS MichaelBlythe,
[276] AS LindaMitchell
FROM PivotData
PIVOT(SUM(AggregationCol) FOR SpreadingCol IN ([274], [275], [276])) AS P
WHERE [274] IS NOT NULL OR [275] IS NOT NULL OR [276] IS NOT NULL
And here is a part of the result (notice I'm not showing from the first line).
So that is looking pretty difficult. Let us break that up in simpler parts. First of all I am using a CTE to identify the columns I want to use in my PIVOT. I then make a rather weird SELECT statement where I select for, what seem to be, random numbers. Actually these are values from the so called spreading column defined in the PIVOT clause. So 274, 275 and 276 are actually SalesPerson ID's that I want to see as columns rather than values in rows. In the PIVOT clause I indicate the aggregation operator I want to use, in this case SUM, and the column I want to aggregate. Then I specify the spreading column, or the column which values should be columns instead of values in rows. Last, but not least, your PIVOT must have an alias assigned, even when you do not use it. The WHERE clause is optional. That is quite something so take a while to study the syntax and let it sink in.
You might have noticed I do not do anything with CustomerID in the PIVOT clause. This is because with PIVOT the grouping element(s) are identified by elimination. Since I am not using CustomerID in either an aggregate function or as speading element it automatically becomes the grouping element. This is also the reason it is best to use a CTE. If you had just selected from the Sales.SalesOrderHeader table directly the SalesOrderHeaderID would become part of the grouping and you would have gotten one row per order instead of per CustomerID!
Now there are a few limitations to using the PIVOT operator. One of those is that you cannot use expressions to define your aggregation or spreading colum values. Another limitation is that COUNT(*) is not allowed as aggregation function used by PIVOT. Instead you need to use COUNT(ColumnName). You can work around this limitation by selecting a constant value in your CTE and using COUNT on that column. Furthermore you can use only one aggregate function.
The last limitation, and in my opinion the limitation that makes you not want to use PIVOT to often, is that the spreading values must be a list of static values. In our example these values are SalesPerson ID's. So what does this mean? It means you are actually hard coding values in your query! I only showed three SalesPersons because listing them all would make the query a lot bigger. Just presume I queried for our top three sales people. What if next month someone else sells better? We would have to alter our query! Or what if a SalesPerson left the company? Back to rewriting your query... Actually I had to find the names of the SalesPersons manually and use them as column aliases to make sense of the columns (although I could have joined on the names and use those as spreading values). You can come around this limitation by using Dynamic SQL, but that is outside the scope of this article. And of course this is no problem at all when you are writing queries for values that are really (sort of) static, like VAT percentages or status ID's.
7.2 Unpivoting
Unpivoting, in a sense, is the opposite, or inverse, of pivoting. Instead of making columns out of row values we can make row values out of column values. In fact the starting point for an UNPIVOT is, usually, pivoted data. So let us take the PIVOT example and UNPIVOT it again. For this example I will wrap the result of the PIVOT example in a CTE and use this to unpivot the data. this is not very useful in a real world example (after all, why would you PIVOT first and UNPIVOT directly after?), but this becomes more useful when the pivoted data is stored in a table or the result of a VIEW or STORED PROCEDURE.
WITH DataToPivot AS
(
SELECT
s.CustomerID,
s.SalesPersonID AS SpreadingCol,
s.SubTotal AS AggregationCol
FROM Sales.SalesOrderHeader AS s
),
DataToUnpivot AS
(
SELECT
CustomerID,
[274] AS StephenJiang,
[275] AS MichaelBlythe,
[276] AS LindaMitchell
FROM DataToPivot
PIVOT(SUM(AggregationCol) FOR SpreadingCol IN ([274], [275], [276])) AS P
WHERE [274] IS NOT NULL OR [275] IS NOT NULL OR [276] IS NOT NULL
)
SELECT
CustomerID,
SalesPerson,
SubTotal
FROM DataToUnpivot
UNPIVOT(SubTotal FOR SalesPerson IN(StephenJiang, MichaelBlythe, LindaMitchell)) AS U
ORDER BY CustomerID
I wrapped the result of the PIVOT example in the DataToUnpivot CTE. Notice that in this example you should get three times as many rows as in the result of the PIVOT. After all each row from the PIVOT result is now applied to the StephenJiang value, the MichaelBlythe value and the LindaMitchell value. This is not the case however, since UNPIVOT removes rows where the SubTotal would be NULL for a given SalesPerson. The following example of the same customer for the pivoted and the unpivoted result might clear things up.
In the unpivoted result LindaMitchell was removed because in the pivoted result her value was missing.
Let us take another look at an example where we unpivot a table that is not actually pivoted. The Sales.SpecialOffer table has special offers with a Description, a MinQty and a MaxQty. Instead of showing all three in one row we want a seperate row for both MinQty and MaxQty.
SELECT
SpecialOfferID,
Description,
QtyType,
Qty
FROM Sales.SpecialOffer
UNPIVOT(Qty FOR QtyType IN (MinQty, MaxQty)) AS U
As you can see QtyType gets the value of either MinQty or MaxQty (previous column names) and the Qty now shows the value that was previously either in the MinQty column or in the MaxQty column, dependent on QtyType.
Again it is not possible to use expressions for the value of the new values column or the new column name values column.
8. More uses for Table Expressions; APPLY
The APPLY operator can be used to 'join' a table expression to your query. I use the term 'join' because an APPLY actually looks like a JOIN in that you can merge multiple tables into the same result set. There are two types of APPLY operators, being the CROSS APPLY and the OUTER APPLY. The interesting part about the APPLY operator is that it can have a table expression that references values from the outer query. One thing you should remember is that CROSS APPLY actually looks most like the INNER JOIN while the OUTER APPLY works like an OUTER JOIN. Other than that an APPLY operator may perform much better than a JOIN when the JOIN conditions are rather complex.
8.1 CROSS APPLY
The CROSS APPLY operator works like an INNER JOIN in that it can match rows from two tables and leaves out rows that were not matched by the other table in the result. So let us look at an example. We want to select all Persons that have a SalesOrder and show some order information for the most expensive order that Person has made.
SELECT
p.BusinessEntityID,
p.FirstName,
p.LastName,
a.*
FROM Person.Person AS p
CROSS APPLY (SELECT TOP 1
s.SalesOrderID,
s.CustomerID,
s.SubTotal
FROM Sales.SalesOrderHeader AS s
JOIN Sales.Customer AS c ON c.CustomerID = s.CustomerID
WHERE c.PersonID = p.BusinessEntityID
ORDER BY s.SubTotal DESC) AS a
ORDER BY p.BusinessEntityID
So the CROSS APPLY operator takes a table expression as input parameter and simply joins the result with each row of the outer query. Notice that we can do a TOP 1, filter by using a WHERE clause to match the CustomerID with the BusinessEntityID and ORDER BY DESC to get the most expensive order for that particular customer. Something that would not have been possible by simply using a JOIN! Notice that Persons that have not placed an order are not returned. Like with PIVOT and UNPIVOT we need to alias the result of the APPLY operator.
Because we can reference values from the outer query in our APPLY operator it is also possible to use functions with the APPLY operator. The AdventureWorks2012 database actually has one user-defined table valued function called ufnGetContactInformation, which takes a PersonID as input and returns information about a Person (names and if they are suppliers, customers etc.). So using the APPLY operator we can show this information in our resultset by passing the BusinessEntityID of the outer query to the input of the function. Since calling this function 19972 times (once for each Person) is actually quite time consuming we are only selecting a TOP 1000.
SELECT TOP 1000
p.BusinessEntityID,
a.*
FROM Person.Person AS p
CROSS APPLY ufnGetContactInformation(p.BusinessEntityID) AS a
ORDER BY p.BusinessEntityID
Notice that we must specify the function without parenthesis or a SELECT... FROM.
And of course we can use multiple APPLY operators in a single query.
SELECT TOP 1000
p.BusinessEntityID,
a.*,
s.*
FROM Person.Person AS p
CROSS APPLY ufnGetContactInformation(p.BusinessEntityID) AS a
CROSS APPLY (SELECT TOP 1
s.SalesOrderID,
s.CustomerID,
s.SubTotal
FROM Sales.SalesOrderHeader AS s
JOIN Sales.Customer AS c ON c.CustomerID = s.CustomerID
WHERE c.PersonID = p.BusinessEntityID
ORDER BY s.SubTotal DESC) AS s
ORDER BY p.BusinessEntityID
You do not have to match rows from your outer query with your APPLY result. The following APPLY simply returns the most expensive order and as a result shows this with each Person, regardless of whether the order was placed by this Person.
SELECT
p.BusinessEntityID,
p.FirstName,
p.LastName,
a.*
FROM Person.Person AS p
OUTER APPLY (SELECT TOP 1
s.SalesOrderID,
s.CustomerID,
s.SubTotal
FROM Sales.SalesOrderHeader AS s
ORDER BY s.SubTotal DESC) AS a
ORDER BY p.BusinessEntityID
And the rows do not have to be a one on one match either. The following query gets the top three most expensive orders regardless of customer and as a result each Person is duplicated three times in the result (once for each order, regardless of whether the order was placed by this Person).
SELECT
p.BusinessEntityID,
p.FirstName,
p.LastName,
a.*
FROM Person.Person AS p
OUTER APPLY (SELECT TOP 3
s.SalesOrderID,
s.CustomerID,
s.SubTotal
FROM Sales.SalesOrderHeader AS s
ORDER BY s.SubTotal DESC) AS a
ORDER BY p.BusinessEntityID
8.2 OUTER APPLY
The OUTER APPLY works in much the same way as the CROSS APPLY with the exception that it also returns rows if no corresponding row was returned by the APPLY operator. We can see this by using the first example of the previous section, but by changing the CROSS APPLY into an OUTER APPLY. By running this query you can see that Persons that have not placed an order are now also returned in the result set.
SELECT
p.BusinessEntityID,
p.FirstName,
p.LastName,
a.*
FROM Person.Person AS p
OUTER APPLY (SELECT TOP 3
s.SalesOrderID,
s.CustomerID,
s.SubTotal
FROM Sales.SalesOrderHeader AS s
JOIN Sales.Customer AS c ON c.CustomerID = s.CustomerID
WHERE c.PersonID = p.BusinessEntityID
ORDER BY s.SubTotal DESC) AS a
ORDER BY p.BusinessEntityID
Other than that all rules that apply to the CROSS APPLY operator also apply to OUTER APPLY.
9. Other aspects of querying
So far we have only queried data and returned the values from the database as they actually are. There is much more that we can do with these values though. Suppose, for example, an order has a SubTotal and a TotalDue column. What we want to know is how much percent tax the customer paid on an order. However Freight is also added to TotalDue, so we must subtract that first. Usually we would calculate this by taking the difference between the SubTotal and TotalDue, divide that by TotalDue and multiply that by 100.
We can do this kind of math in SQL Server. The following query shows how this can be done.
SELECT
SalesOrderID,
CustomerID,
SubTotal,
TaxAmt,
Freight,
TotalDue,
(((TotalDue - Freight) - SubTotal) / (TotalDue - Freight)) * 100 AS TaxPercentage
FROM Sales.SalesOrderHeader
And of course we can use SubTotal and TaxAmt and Freight to calculate TotalDue ourselves. You should remember is that adding a numeric value to NULL always results in NULL.
SELECT
SalesOrderID,
CustomerID,
SubTotal,
TaxAmt,
Freight,
TotalDue,
SubTotal + TaxAmt + Freight AS TotalDueCalc
FROM Sales.SalesOrderHeader
How about if we want to give every customer a ten percent discount on their orders (probably a bad idea, but let's do this).
SELECT
SalesOrderID,
CustomerID,
SubTotal,
SubTotal - (SubTotal * 0.10) AS SubTotalAfterDiscount
FROM Sales.SalesOrderHeader
We can also use functions such as FLOOR, CEILING and ROUND to further manipulate our data.
SELECT
SalesOrderID,
CustomerID,
SubTotal,
FLOOR(SubTotal) AS SubTotalRoundedDown,
CEILING(SubTotal) AS SubTotalRoundedUp,
ROUND(SubTotal, 2) AS RoundedToTwoDecimals
FROM Sales.SalesOrderHeader
There are much more functions that can be used to manipulate data in various ways. I cannot possibly discuss them all here. The following sections will give an overview of some important and most used functions for manipulating data in SQL Server.
9.1 Converting types; CAST and CONVERT, PARSE and FORMAT
9.1.1 CAST and CONVERT
Casting and converting values are the same thing, being changing a datatype to another datatype. For example, we can change a numeric into a string, a string into a numeric (given that the text actually represents a numeric value), a date to a string, string to date etc.
SQL Server actually has four functions for casting and converting values. CAST, CONVERT, TRY_CAST and TRY_CONVERT.
Let us look at the CAST function first. First of all, you can cast anything to VARCHAR(x), since each and every value can be shown as plain text. Here is a simple example of casting some values to different types.
SELECT
CAST('123' AS INT) AS VarcharToInt,
CAST('20131231' AS DATETIME2) AS VarcharToDateTime2,
CAST(1.2 AS INT) AS FloatToInt,
CAST(1234 AS VARCHAR(4)) AS IntToVarchar
We can cast the SubTotal to a VARCHAR(20) and order it not as numerics, but as alphanumerics (which means 10 comes before 2 etc.).
SELECT
SalesOrderID,
SubTotal,
CAST(SubTotal AS VARCHAR(20)) AS SubTotalAsAlphaNum
FROM Sales.SalesOrderHeader
ORDER BY SubTotalAsAlphaNum
Unfortunately SQL Server formats the results for us and the alphanumeric outcome has only two digits after the comma. With CONVERT we have more control over the formatting of values.
The CONVERT function takes three parameters. The first parameter is the type you want to convert to, the second is the value you want to convert and the optional third is a style parameter. In this case we want our money to have style number 2.
SELECT
SalesOrderID,
SubTotal,
CONVERT(VARCHAR(20), SubTotal, 2) AS SubTotalAsAlphaNum
FROM Sales.SalesOrderHeader
ORDER BY SubTotalAsAlphaNum
How did I know the format? Look them up on the CAST and CONVERT page on TechNet.
With CONVERT we can cast a DATETIME value to a VARCHAR and use the style parameter to display a local date format.
SELECT
SalesOrderID,
OrderDate,
CONVERT(VARCHAR, OrderDate, 13) AS OrderDateAsEur,
CONVERT(VARCHAR, OrderDate, 101) AS OrderDateAsUS
FROM Sales.SalesOrderHeader
And of course you can convert VARCHARS to DATETIMES. To do this you should always use the text format yyyyMMdd as shown in the following query. Every other format is not guaranteed to be culture invariant and running a query in Europe with result july 6th might have the result of june 7th in America!
SELECT CONVERT(DATETIME, '20131231')
Some casts may actually not be what you expect. For example, you can cast a DATETIME value to an INT. The value that is returned is actually the difference in days between the specified value and the minimum date for the SMALLDATETIME type (which is januari first 1900). The following query shows this.
The following functions are discussed later in this article, but for now focus on the results.
SELECT CONVERT(INT, CONVERT(DATETIME, '17530101')) AS MinDateAsInt,
CONVERT(INT, GETDATE()) AS TodayAsInt,
DATEADD(d, CONVERT(INT,
CONVERT(DATETIME, '17530101')), '19000101')
AS MinSmallDateTimePlusMinDateAsInt,
DATEADD(d, CONVERT(INT, GETDATE()), '19000101')
AS MinSmallDateTimePlusTodayAsInt
And here is the result (your results will look different since I am using the current datetime and the time at which I write this is different than the time at which you are reading).
So what happens when we cast a value that cannot be cast to the specified type? In that case we make an invalid cast and an exception is thrown.
If you do not want an exception to be thrown at an invalid cast you can use the TRY_CAST and TRY_CONVERT functions. They work exactly the same as CAST and CONVERT, except that the TRY_ variants do not throw an error when a cast is invalid, but returns NULL instead.
SELECT TRY_CAST('Hello' AS INT),
TRY_CONVERT(INT, 'Hello')
SQL Server might give you a warning that TRY_CAST is not recognized as a built-in function name. This appears to be a bug and you can ignore it, the query will run fine.
9.1.2 PARSE
Parsing is a special kind of cast which always casts a VARCHAR value into another datatype. In SQL Server we can use the PARSE or TRY_PARSE function which takes as parameters a VARCHAR value, a datetype and an optional culture code to specify in which culture format the value is formatted. We can for example parse a VARCHAR value that represents a date formatted to Dutch standards into a DATETIME value.
SELECT PARSE('12-31-2013' AS DATETIME2 USING 'en-US') AS USDate,
PARSE('31-12-2013' AS DATETIME2 USING 'nl-NL') AS DutchDate
We can also use PARSE for numeric or money types. The following example shows how two differently formatted money styles produce the same output with PARSE. Notice that Americans use a point as decimal seperator while Dutch use a comma.
SELECT PARSE('$123.45' AS MONEY USING 'en-US') AS USMoney,
PARSE('€123,45' AS MONEY USING 'nl-NL') AS DutchMoney
If we ommit the currency symbol and the culture info we actually get very different results!
SELECT PARSE('123.45' AS MONEY) AS USMoney,
PARSE('123,45' AS MONEY) AS DutchMoney
Of course a parse can also fail. As with CAST and CONVERT we get an error.
And again you can use TRY_PARSE to return NULL if a PARSE fails.
SELECT TRY_PARSE('Hello' AS MONEY USING 'nl-NL')
It is recommended to use PARSE only to parse date and numeric values represented as text to their corresponding datatypes. For more general casting use CAST and CONVERT.
9.1.3 FORMAT
The FORMAT function does not really provide a means to convert between datatypes. Instead it provides a way to output data in a given format.
For example, we can format dates to only show the date without time or we can format numerics to show leading 0's and always x decimal digits.
SELECT
SalesOrderID,
FORMAT(SalesOrderID, 'SO0') AS SalesOrderNumber,
CustomerID,
FORMAT(CustomerID, '0.00') AS CustomerIDAsDecimal,
OrderDate,
FORMAT(OrderDate, 'dd-MM-yy') AS FormattedOrderDate
FROM Sales.SalesOrderHeader
And you can specify cultures to format to that specified culture.
SELECT
SalesOrderID,
OrderDate,
FORMAT(OrderDate, 'd', 'en-US') AS USShortDate,
FORMAT(OrderDate, 'd', 'nl-NL') AS DutchShortDate,
FORMAT(OrderDate, 'D', 'en-US') AS USLongDate,
FORMAT(OrderDate, 'D', 'nl-NL') AS DutchLongDate
FROM Sales.SalesOrderHeader
ORDER BY CustomerID
And here are some results.
And of course we can format numeric values as well.
SELECT
SalesOrderID,
SubTotal,
FORMAT(SubTotal, 'C', 'nl-NL') AS DutchCurrency
FROM Sales.SalesOrderHeader
You might be wondering if there is a <code>TRY_FORMAT. There is not. Ask yourself, why should a format fail? It probably doesn't. It might format to unexpected values, but other than that invalid values can be caught when SQL Server parses the query. Here is an example of what you think might go wrong, but actually just formats to a weird value.
SELECT
SalesOrderID,
SubTotal,
FORMAT(SubTotal, 'Hello', 'nl-NL') AS DutchCurrency
FROM Sales.SalesOrderHeader
For format values I once again redirect you to the FORMAT page on TechNet.
9.2 VARCHAR functions
You will be working with the (VAR)CHAR type a lot. In the previous section we have seen FORMAT which can be used to get a specific, culture dependent, output for certain values. But that is not all you can do with text data.
First of all, there are many times that you want to concatenate text. The Person table, for example, has a FirstName and a LastName column. Those combined, seperated by a space, can become a FullName field.
SELECT
BusinessEntityID,
FirstName + ' ' + LastName AS FullName
FROM Person.Person
ORDER BY FullName
When concatenating a string to NULL this results in NULL unless a session option called CONCAT_NULL_YIELDS_NULL_INPUT is turned off. This is outside the scope of this article.
A word of caution on concatenation. Make sure you are either concatenating text to text or numerics to numerics. The following concatenation results in an error.
SELECT
BusinessEntityID,
BusinessEntityID + FirstName AS IDName
FROM Person.Person
ORDER BY IDName
And here is the error.
SQL Server tries to convert FirstName to an INT, since BusinessEntityID is an INT. Switching the values will not help either. What will help is a CAST.
SELECT
BusinessEntityID,
CAST(BusinessEntityID AS VARCHAR(6)) + FirstName AS IDName
FROM Person.Person
ORDER BY IDName
Or you could use the CONCAT function, which concatenates all values passed to the function as strings. When using CONCAT NULLs are ignored.
SELECT
BusinessEntityID,
CONCAT(BusinessEntityID, FirstName) AS IDName,
CONCAT(NULL, LastName) AS LastName
FROM Person.Person
ORDER BY IDName
Other times you only want to return a portion of a string. For example the first or last letter. This can be achieved with the LEFT and RIGHT functions.
SELECT
BusinessEntityID,
LEFT(FirstName, 1) + '. ' + LastName AS AbbrvName,
RIGHT(FirstName, 3) AS LastThreeLetters
FROM Person.Person
ORDER BY AbbrvName
You can also use SUBSTRING to get a portion of a string by (1-based) index. The following query outputs the same data as the last query. Notice I also use the LEN function to determine the length of a given input.
SELECT
BusinessEntityID,
SUBSTRING(FirstName, 1, 1) + '. ' + LastName AS AbbrvName,
SUBSTRING(FirstName, LEN(FirstName) - 2, 3) AS LastThreeLetters
FROM Person.Person
ORDER BY AbbrvName
To get the index of a specific character in a string you can use the CHARINDEX function which returns the position of the first occurrence of the specified character. Using this we can, for example, format a numeric value and return the portion before the decimal seperator and the portion after the decimal seperator seperately.
SELECT
SubTotal,
SUBSTRING(
FORMAT(SubTotal, 'G', 'en-US'),
0,
CHARINDEX('.', FORMAT(SubTotal, 'G', 'en-US'))) AS DigitsBeforeDecimal,
SUBSTRING(
FORMAT(SubTotal, 'G', 'en-US'),
CHARINDEX('.', FORMAT(SubTotal, 'G', 'en-US')) + 1,
4) AS DigitsAfterDecimal
FROM Sales.SalesOrderHeader
Sometimes you want to format strings in a way that is not supported by the FORMAT function. You can use the functions UPPER and LOWER to make a string all uppercase or all lowercase. The functions LTRIM and RTRIM remove leading and trailing spaces from a string (especially useful when dealing with legacy applications!).
SELECT
UPPER(FirstName) AS UpperName,
LOWER(FirstName) AS LowerName,
LTRIM(' abc ') AS AbcWTrailing,
RTRIM(' abc ') AS AbcWLeading,
LTRIM(RTRIM(' abc ')) AS Abc
FROM Person.Person
There are a few more useful functions that you can use to alter strings. With REPLACE you can replace a character or a substring of a string with another character or string. With STUFF you can replace a part of a string based on index. With REVERSE you can, of course, reverse a string. In the following example we revert the SalesOrderNumber, we replace the 'SO' in the SalesOrderNumber with 'SALE', and we replace the first two characters of the PurchaseOrderNumber with 'PURC'.
SELECT
SalesOrderNumber,
REVERSE(SalesOrderNumber) AS ReversedOrderNumber,
REPLACE(SalesOrderNumber, 'SO', 'SALE') AS NewOrderFormat,
PurchaseOrderNumber,
STUFF(PurchaseOrderNumber, 1, 2, 'PURC') AS NewPurchaseFormat
FROM Sales.SalesOrderHeader
There are more functions you can use to format, alter or get information about string values. You can find them on TechNet.
9.3 DATETIME functions
Working with dates and time in SQL Server (or any language) has never been easy. There is no date without time, no time without date, comparisons fail if two values differ by a millisecond, every culture has its own formats, we have timezones, daylight savings time, and not even every culture has the same calendar! Luckily SQL Server provides us with lots of functions (and datatypes) to work with dates and time.
I can recommend reading the following page on TechNet: Date and Time Data Types and Functions.
First of all, how do we get the current time? SQL Server has a couple of functions you can use. GETDATE and CURRENT_TIMESTAMP to get the current date and time (on the computer that the SQL Server instance is running on) as datatype DATETIME, GETUTCDATE gets the current date and time in Coordinated Universal Time as datatype DATETIME, SYSDATETIME which also returns the current date and time, but as datatype DATETIME2(7), SYSUTCDATETIME which returns the current date and time as Coordinated Universal Time as datatype DATETIME2(7) and the SYSDATETIMEOFFSET which returns the current date and time including the timezone offset as datatype DATETIMEOFFSET(7). The following query shows these functions.
SELECT
GETDATE() AS [GetDate],
CURRENT_TIMESTAMP AS CurrentTimestamp,
GETUTCDATE() AS [GetUtcDate],
SYSDATETIME() AS [SysDateTime],
SYSUTCDATETIME() AS [SysUtcDateTime],
SYSDATETIMEOFFSET() AS [SysDateTimeOffset]
To get a date without the time part simply convert a DATETIME value to DATE. Similary, if you want the time without the date you can cast to TIME.
SELECT
SYSDATETIME() AS DateAndTime,
CAST(SYSDATETIME() AS DATE) AS [Date],
CAST(SYSDATETIME() AS TIME) AS [Time]
You may also be interested in only a part of the date, for example the day, month or year. You can use the DATEPART function for this, or the 'shortcut' functions YEAR, MONTH and DAY. Notice that you can actually extract a lot more using DATEPART. In addition there is a DATENAME function which works the same as DATEPART, except it returns the part of the date as string. DATENAME is especially useful for returning the name of the month. Be aware that the name of the month is translated in the language of your session.
SELECT
DATEPART(DAY, SYSDATETIME()) AS DayFromDatePart,
DATEPART(WEEK, SYSDATETIME()) AS WeekFromDatePart,
DATEPART(MONTH, SYSDATETIME()) AS MonthFromDatePart,
DATEPART(YEAR, SYSDATETIME()) AS YearFromDatePart,
DATEPART(SECOND, SYSDATETIME()) AS SecondFromDatePart,
DATEPART(NANOSECOND, SYSDATETIME()) AS NanoSecondFromDatePart,
DAY(SYSDATETIME()) AS DayFromFunc,
MONTH(SYSDATETIME()) AS MonthFromFunc,
YEAR(SYSDATETIME()) AS YearFromFunc,
DATENAME(DAY, SYSDATETIME()) AS DayFromDateName,
DATENAME(MONTH, SYSDATETIME()) AS MonthFromDateName,
DATENAME(YEAR, SYSDATETIME()) AS YearFromDateName
Sometimes you want to add specific intervals to dates. For example, when an order is placed today the latest delivery date is seven days ahead. Or when an item is not in stock it may take up to a month. To add or subtract dates you can use the DATEADD function. In the following example I remove the time part by casting to date.
SELECT
DATEADD(DAY, -1, CAST(SYSDATETIME() AS DATE)) AS PreviousDay,
DATEADD(DAY, 1, CAST(SYSDATETIME() AS DATE)) AS NextDay,
DATEADD(WEEK, 1, CAST(SYSDATETIME() AS DATE)) AS NextWeek,
DATEADD(MONTH, 1, CAST(SYSDATETIME() AS DATE)) AS NextMonth,
DATEADD(YEAR, 1, CAST(SYSDATETIME() AS DATE)) AS NextYear
You can also get the difference between two dates. For example, we want to know the difference in days between the order date and the delivery date of an order in the SalesOrderHeader table. This can be accomplished by using the DATEDIFF function.
SELECT
OrderDate,
ShipDate,
DATEDIFF(DAY, OrderDate, ShipDate) AS DiffBetweenOrderAndShipDate
FROM Sales.SalesOrderHeader
ORDER BY DiffBetweenOrderAndShipDate DESC
Be aware that the DATEDIFF function only looks at the part you want to know the difference of. So when you want the difference in years the function only looks at the year part of the dates. So the result of the next query is 1 for day, month and year, even though the difference between the dates is really just one day.
SELECT
DATEDIFF(DAY, '20131231', '20140101') AS DiffInDays,
DATEDIFF(MONTH, '20131231', '20140101') AS DiffInMonths,
DATEDIFF(YEAR, '20131231', '20140101') AS DiffInYears
As mentioned we live in a world divided in timezones. With the SWITCHOFFSET function you can display a date in any given offset, no matter what timezone you are currently in. For example I live in the Netherlands, which is UTC/GMT+1, now I want the Hawaiin time, which is UTC/GMT-10 and the time in Sydney which is UTC/GMT+10, or +11 when it's daylight savings time. Unfortunately there is no easy way to correct for daylight savings time, so you may figure that out by yourself (and Google). The following query shows the local time, the time in Sydney (not corrected for daylight savings) and the time in Hawaii.
SELECT
SYSDATETIMEOFFSET() AS LocalTime,
SWITCHOFFSET(SYSDATETIMEOFFSET(), '+10:00') AS SydneyTime,
SWITCHOFFSET(SYSDATETIMEOFFSET(), '-10:00') AS HawaiianTime
So far we have only constructed dates with strings in a specific format or by calling a function that returns the current date. There are also a couple of functions that can construct date values from various date parts. These functions are DATEFROMPARTS, DATETIME2FROMPARTS, DATETIMEFROMPARTS, DATETIMEOFFSETFROMPARTS, SMALLDATETIMEFROMPARTS and TIMEFROMPARTS. The function names describe what they do pretty well, so I will not expand on that further. Here are some examples of the usages of various function.
SELECT
DATEFROMPARTS(2013, 12, 31) AS [DateFromParts],
DATETIME2FROMPARTS(2013, 12, 31, 14, 30, 0, 0, 0) AS [DateTime2FromParts],
DATETIMEOFFSETFROMPARTS(2013, 12, 31, 14, 30, 0, 0, 1, 0, 0) AS [DateTimeOffsetFromParts],
TIMEFROMPARTS(14, 30, 0, 0, 0) AS [TimeFromParts]
SQL Server has more useful functions that you can use when working with dates and time. One such functions is EOMONTH, which returns a date representing the last day of the month of the date(time) that was passed as a parameter. Another is ISDATE which checks if a string can be converted to a valid date. You can find those and others on TechNet.
I recently came across a rather nice CP article explaining all there is to know about dates, times and functions in all versions of SQL Server. Recommended reading: Date and Time Date Types and Functions - SQL Server (2000, 2005, 2008, 2008 R2, 2012)
9.4 CASE and IIF
9.4.1 CASE
Sometimes you want to return a value based on another value. For example, when a bit is 1 or true you want to return 'Yes' and else 'No'. Or you want to include a value to the result only when that value is not empty. With CASE such scenario's become possible. With CASE you can either test a column for a value and return another value based on that value or you can include more advanced criteria for testing which value to show.
Let us look at the first CASE variant, the simple form. We know that a Person from the Person table can have the title 'Mr.' or 'Mrs.', 'Ms.' or 'Ms'. Instead of these values we want to return 'Mister' for 'Mr.' and 'Miss' for all the 'Ms.' variants. If the title is something else, like 'Sr.' then we want to show that.
SELECT
BusinessEntityID,
CASE Title
WHEN 'Mr.' THEN 'Mister'
WHEN 'Mrs.' THEN 'Miss'
WHEN 'Ms.' THEN 'Miss'
WHEN 'Ms' THEN 'Miss'
ELSE Title
END AS Salutation,
FirstName,
LastName
FROM Person.Person
So the simple CASE statement has an input expression, in this case Title, which is compared to multiple values defined in the WHEN clauses. If a match is found the value in the THEN clause is returned. If no match is found the value in the ELSE clause is returned. When the value was not matched in any WHEN clause and no ELSE clause is specified a NULL is returned.
Another variant on the CASE expression is the searched form. With the searched form of the CASE expression we have more flexibility in when clauses. We can now use predicates to test for a certain criterium. The first WHEN clause that returns true determines what value is returned. The following query shows how you can use the searched CASE expression and also offers an alternative using CONCAT.
SELECT
BusinessEntityID,
CASE
WHEN Title IS NULL AND MiddleName IS NULL
THEN FirstName + ' ' + LastName
WHEN Title IS NULL AND MiddleName IS NOT NULL
THEN FirstName + ' ' + MiddleName + ' ' + LastName
WHEN Title IS NOT NULL AND MiddleName IS NULL
THEN Title + ' ' + FirstName + ' ' + LastName
ELSE Title + ' ' + FirstName + ' ' + MiddleName + ' ' + LastName
END AS FullNameAndTitle,
CONCAT(Title + ' ', FirstName, ' ', MiddleName + ' ', LastName) AS FullNameAndTitleConcat
FROM Person.Person
ORDER BY FullNameAndTitle
Here is another example which we cannot write using other functions.
SELECT
SalesOrderID,
CustomerID,
SubTotal,
CASE
WHEN SubTotal < 100
THEN 'Very cheap order'
WHEN SubTotal < 1000
THEN 'Cheap order'
WHEN SubTotal < 5000
THEN 'Moderate order'
WHEN SubTotal < 10000
THEN 'Expensive order'
ELSE 'Very expensive order'
END AS OrderType
FROM Sales.SalesOrderHeader
Notice that in the second WHEN clause we do not have to check if the order is more expensive than 100. If the first WHEN clause returns true then the value in the corresponding THEN clause is returned and the subsequent WHEN clauses are not evaluated.
9.4.2 IIF
Sometimes all you want to know is if a certain attribute has a value or if it is NULL and return a value based on that predicate. Using a CASE expression can make your query rather wordy and it would be nice if we had a shortcut. Well, we have. With IIF you can test a predicate and specify a value if it evaluates to true and a value if it evaluates to false. The following example shows how IIF is used and can replace a CASE expression.
SELECT
BusinessEntityID,
CASE
WHEN Title IS NULL THEN 'No title'
ELSE Title
END AS TitleCase,
IIF(Title IS NULL, 'No title', Title) AS TitleIIF,
FirstName,
LastName
FROM Person.Person
And of course other types of predicates can be used as well.
SELECT
SalesOrderID,
CustomerID,
SubTotal,
IIF(SubTotal > 5000, 'Expensive order', 'Not so expensive order')
AS OrderType
FROM Sales.SalesOrderHeader
And even the following.
SELECT
BusinessEntityID,
FirstName,
LastName,
IIF(EXISTS(SELECT *
FROM Sales.SalesOrderHeader AS s
JOIN Sales.Customer AS c ON c.CustomerID = s.CustomerID
WHERE c.PersonID = BusinessEntityID),
'Has orders', 'Does not have orders')
FROM Person.Person
9.5 COALESCE, ISNULL and NULLIF
With COALESCE we can specify a range of values and the first value that is not NULL is returned. It can actually make our IIF that checks for a NULL from the previous section even shorter.
SELECT
BusinessEntityID,
COALESCE(Title, 'No title'),
FirstName,
LastName
FROM Person.Person
More values can be specified.
SELECT
ProductID,
Name,
ProductNumber,
COALESCE(Style, Class, ProductLine) AS Style
FROM Production.Product
Of course now we do not know if the result represents a style, class or productline, but you can fix that by adding a CASE expression.
COALESCE returns NULL if all values that were passed to it are NULLs.
ISNULL does the same as COALESCE, but with some differences. The first difference is that ISNULL can only have two values. So if the first value is NULL it will return the second value (which may also be NULL).
SELECT
BusinessEntityID,
ISNULL(Title, 'No title'),
FirstName,
LastName
FROM Person.Person
And you can nest ISNULL to get the same effect as COALESCE.
SELECT
ProductID,
Name,
ProductNumber,
ISNULL(Style, ISNULL(Class, ProductLine)) AS Style
FROM Production.Product
So why would you choose one over the other? Well, COALESCE is an ANSI SQL standard function, so it is more portable than ISNULL. The more important difference, however, is the return type of the two functions. The type that COALESCE returns is determined by the returned element, while for ISNULL the type is determined by the first element. In the following query the returned value of ISNULL is truncated to fit the type of the first element. COALESCE keeps the value intact.
DECLARE @first AS VARCHAR(4) = NULL
DECLARE @second AS VARCHAR(5) = 'Hello'
SELECT
COALESCE(@first, @second) AS [Coalesce],
ISNULL(@first, @second) AS [IsNull]
And the result.
Another difference between the two is that the underlying type of COALESCE is always NULLABLE, even when a NULL can never be returned. ISNULL recognizes scenario's where NULL is never returned and gives the underlying value definition the NOT NULLABLE attribute. This difference can be important when you are creating VIEWS or STORED PROCEDURES.
Though it is not within the scope of this article I want to show the difference just to make it clear.
I have created a view using the following definition.
CREATE VIEW dbo.CoalesceVsIsNull
AS
SELECT
BusinessEntityID,
COALESCE(Title, 'No title') AS TitleIsCoalesce,
ISNULL(Title, 'No title') AS TitleIsNull,
FirstName,
LastName
FROM Person.Person
And here is the views column definition.
As you can see TitleIsCoalesce can contain NULLs even though this is impossible. TitleIsNull will never have NULLs. If you have created the VIEW you can now delete it using the following command.
DROP VIEW dbo.CoalesceVsIsNull
Another thing you should be aware of when working with COALESCE, ISNULL or CASE is that every returned value should have the same data type or conversion errors may occur. For example, the following query raises an error because the @second parameter is going to be converted to an INT.
DECLARE @first AS INT = NULL
DECLARE @second AS VARCHAR(5) = 'Hello'
SELECT
ISNULL(@first, @second)
A last function I want to mention is NULLIF. This function takes two parameters and returns the first value if the values are different or NULL if the values are equal.
SELECT
NULLIF(1, 1) AS Equal,
NULLIF(1, 2) AS NotEqual
10. Conclusions
That concludes this part of the article and with that the entire article. I hope you have learned as much reading this as I have writing it. The two parts of this article discuss a lot about querying data. Yet it has only scratched the surface of what is possible within SQL Server. Some of the things I have not discussed, for example, are querying XML and full-text data and optimizing queries. And of course how to create databases, tables, indexes, constraints, triggers how to insert, update and delete data. If you want to know more about those subjects I recommend reading the 70-461 exam training kit, Querying Microsoft SQL Server 2012. I can also recommend practice and reading various sources, such as TechNet, MSDN, and of course CodeProject.
I will be happy to answer any questions or comments.
Happy coding!

