Introduction
I was always fascinated to know about chess engine programming and all the different search algorithms used in chess engines but I never had a simple example to look at and grasp the main ideas. There were always thousands of lines of tricks, optimizations and smart techniques that I had to go through to even begin to understand the general structure of such programs. Then I took an introductory Artificial Intelligence course at school where I had to do several intriguing AI projects using the well known AIMA framework (which the source code of this project is loosely based on) and finally realized how simple everything was and that cloud of confusion eventually disappeared. One of the projects I was assigned to do in that class was to implement the Tigers and Goats game, a not so well known Indian board game as chess but with a very similar and much simpler structure and set of rules. After giving it some thought I decided to implement the game in JavaScript and HTML to keep it simple and platform independent. The purpose of this article is to provide a code base to understand and compare different adversarial search algorithms like Minimax and Alpha-Beta and to understand the general structure of such AI programs using the least amount of knowledge about a particular platform or framework.
Background
Tigers and Goats is an Indian two player board game played on a special board shown below:
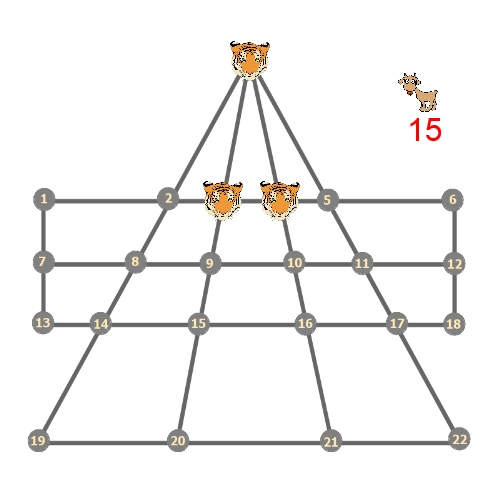
One player has to bring in the outside goats, one goat at a time and can not move any goats unless they are all in. The other player playing as tigers can capture the goats by jumping over them. The tigers can only move one square at a time in each direction (as the goats do) and can only jump over one square. Their goal is to capture all the goats. The goal of the goats is to surround the tigers so that they can not move anymore. I also added the rule that if a particular position happens more than twice, the game ends in a draw; to avoid repetitions. In order to move the pieces around the user should click on a piece and then click on the destination square. I recommend downloading the source code and running the game a few times to understand the game before proceeding to the next section.
Using the code
At the heart of these types of adversarial games is the Game State object, an entity that represents the current state of the game i.e. the position of the pieces or whose side it is to move. I represented the current state of the game with the GameState() class in the TigersAndGoats.js file as shown below:
function GameState() {
this.SideToPlay = 1;
this.OutsideGoats = 15;
this.CurrentPosition = ['T', 'E', 'E', 'T', 'T', 'E', 'E', 'E',
'E', 'E', 'E', 'E', 'E', 'E', 'E', 'E', 'E', 'E', 'E', 'E', 'E', 'E', 'E'];
this.Hash = 0;
this.Result = -1;
}
This may not be the most efficient representation but it is the simplest.
When the game is first loaded (window.onload() function) a new GameState object is created and stored as the current state of the game. Then the UpdateUserInterface() function in UIUtility.js file is called whose job is to look at the current game state and update the game board and the user interface elements accordingly.
Once we represented the current state of the game, we can get a list of available actions or moves that a player can take from that state.
var state = new GameState();
var actions = state.getLegalActions();
Whenever the user makes a move, ProcessUserInput() is called which determines if the user's action is in the list of legal actions and if so makes the move by generating the successor state and then updating the user interface.
var newState = oldState.generateSuccessor(action, history);
But when it is the computer's turn to move, the computerPlay() function will be called. It spawns a new Web Worker which is JavaScript's equivalent of a Thread and the worker then runs agent.getAction() which does the search and keeps returning the best action to take as it goes deeper into the search tree.

Algorithms
I implemented mainly 5 different search algorithms: Minimax, Expectimax, Alpha-Beta, Scout,
and MTD(f)[2].
All these algorithms run within an iterative deepening
framework. For example here is part of the getAction() function of the Minimax agent:
var depth = 1;
var result;
while (true) {
result = minimax(gameState, depth, this.Index);
postMessage([result[0], result[1], depth, nodesExpanded]);
depth++;
}
About null-window search
The Alpha-beta pruning algorithm gains its efficiency over Minimax by searching only those nodes in the search tree that may change the ultimate score at the top of the tree. In other words those branches that have no effect in the result of the search are pruned. It does so by assigning an aspiration window (which is [-Inf, +Inf] at first) recursively to each node in the search tree. At first the top most maximizer node at the top of the search tree tells its minimizer children that it is looking for a value between -Inf and +Inf. then as the search goes on, some values will bubble up the search tree and the maximizer at the top will be assigned a temporary maximum. After that the maximizer is only interested in values higher than the temporary maximum so it gives its children a lower bound in the aspiration window: [temporary maximum, +Inf]. The children will know that the maximizer is not interested in any values lower than the lower bound so whenever they get a value lower than the lower bound from their children, because they are minimizers and they know that anything they ultimately return would be lower than or equal to that value, they return it immediately to end the search for that tree branch (prune the branch and be ignored by their parent maximizer!). The same argument goes for the minimizers and how they assign upper bounds for their maximizer children. As the algorithm goes deeper into the search tree, the aspiration window only gets smaller and as a result more pruning AKA cut-offs will happen and the more we prune the less nodes we visit and the faster our search algorithm will be.
The Scout algorithm runs even faster than Alpha-beta by doing a null-window or zero-window search on most nodes. A null window search is like a test. Let's say that the maximizer at the top of the tree wants to know if the result of the search could be higher than its currently assigned temporary maximum. If it can not be then there is no point in continuing the search. The maximizer should in that case end the search, return its temporary maximum immediately and save some time! That test is done by setting the width of the aspiration window to zero. For example if the maximizer's current temporary maximum is 40 it can set the aspiration window to [40, 40] and tell its children that it is not interested in any value lower than 40 so return it immediately and if there is any value higher than 40 return it immediately because It doesn't care what the value is, it just wants to know if it exists!
The Scout algorithm does a full Alpha-beta search only on the first child and it then tests other children to see if they can do better! Because those tests run with zero width aspiration windows there will be more cut-offs and they run much faster than normal Alpha-beta. As a result if there is a good move ordering meaning that the first guess of the Scout algorithm is the best guess, Scout will run much faster than Alpha-beta.
One way to get a good move ordering in an iterative deepening framework is to store the results of the previous lower depth searches in a transposition table and then whenever we get to the same game state in the search tree, look up the transposition table and consider the previously known best actions first.
MTD(f) runs even faster than Scout by guessing a score and then running a null window search right from the beginning at the top of the search tree! In effect, it makes a guess then runs a test to check if the guess was correct or not and then adjusts the guess accordingly. In my tests MTD(f) in the starting position performed worse than Scout with memory, but on average given a large set of test positions MTD(f) should be about 10 percent faster than Scout[3].
Some Results
To do a performance comparison I ran all the algorithms on the starting position on my 2.5 GHz Core i3 laptop with a depth limit of 6. Here are the results:
| Expectimax | Minimax | Alpha-Beta | Alpha-Beta with memory | Scout without memory | Scout with memory | MTD(f) |
| Max Depth Reached | 6 | 6 | 6 | 6 | 6 | 6 | 6 |
| Time (ms) | 52,219 | 51,301 | 1,585 | 577 | 1,015 | 559 | 648 |
| Total Nodes Expanded | 3,769,060 | 3,769,060 | 111,450 | 27,842 | 68,421 | 24,253 | 31,204 |
| Leaves Visited | 2,997,798 | 2,997,798 | 58,835 | 12,202 | 41,177 | 10,681 | 12,874 |
| Score | 52.3 | 49 | 49 | 49 | 49 | 49 | 49 |
| Action | -1,-1,1 | -1,-1,7 | -1,-1,7 | -1,-1,7 | -1,-1,7 | -1,-1,7 | -1,-1,7 |
Points of Interest
The Hash Table
The hash value of each new game state is generated when the gameState.generateSuccessor function is called and is stored in that new game state:
state.Hash = 0;
for (var i = 0; i < state.CurrentPosition.length; i++) {
if (state.CurrentPosition[i] == 'T')
state.Hash += 2;
else if (state.CurrentPosition[i] == 'G')
state.Hash += 1;
state.Hash *= 4;
}
state.Hash *= 4;
state.Hash += state.OutsideGoats;
state.Hash *= 2;
state.Hash += state.SideToPlay;
This algorithm generates a perfect hash eliminating the possibility of hash collisions. Therefore the hash value can be used to see if two game states are equal for example to see if a position has occurred previously in the history array.
Another use of hash is in the transposition table. At each iteration of those search algorithms with memory, the algorithm stores the result of the search in the hash table.
if (TTresult == null || (TTresult != null && TTresult[2] < depth))
transpositionTable.insert(state.Hash, [action, score, depth, a, b]); Then at the beginning of each iteration the algorithm checks to see if a similar search with a better depth had previously been done and if so returns the result from the transposition table to save time. If not however it can still use that info for move ordering.
var TTresult = transpositionTable.find(state.Hash);
if (TTresult != null) {
if (TTresult[1] >= depth) {
if (TTresult[2] == TTresult[3]) {
history.pop();
return [TTresult[2], TTresult[0]];
}
if (TTresult[2] > b) {
history.pop();
return [TTresult[2], TTresult[0]];
}
if (TTresult[3] < a) {
history.pop();
return [TTresult[3], TTresult[0]];
}
a = Math.max(a, TTresult[2]);
b = Math.min(b, TTresult[3]);
}
for (var i = 0; i < actions.length; i++) {
if (actions[i].compare(TTresult[0])) {
actions.splice(i, 1);
actions.splice(0, 0, TTresult[0]);
break;
}
}
}
Now after a few seconds of searching there will be millions of elements in the hash table. If the hash table was just a list of elements and each time we wanted to look up the hash table we had to go through millions of elements then the performance of search algorithms with memory would degrade substantially. Therefore, hash table insertion and look up operations should be done faster than O(n). To that purpose I implemented a custom hash table with constant time insert and look up operations (O(1)). Specifically in practice no matter how many elements are in the hash table, Insert and look up (find) operations will only take 7 steps to run.
Because the hash key is always a 51 bit binary number we can create a tree as follows:
HashTree.prototype.find = function(key) {
function treeSearch(depth, key, node) {
var nextKey = key & 0xff;
if (depth == 1 && node.Nodes[key] != null) {
return node.Nodes[key].Data;
}
else if (node.Nodes[nextKey] != null) {
key = key - (key & 0xff);
return treeSearch(depth - 1, key / 256, node.Nodes[nextKey]);
}
return null;
}
return treeSearch(7, key, this);
}
This way the run time of Insert and Look up operations will only depend on the length of the hash key which is constant (51 bits).
To Run The Program
If you use Google Chrome you should run it with the --allow-file-access-from-files flag. This is due to chrome's security restrictions.
History
- Dec 10, 2013
- fixed a bug in the Transposition Table update algorithm that was causing algorithms with memory to go to absurdly high depths
- re-implemented MTD(f) to resemble the version in the original paper
- improved UI responsiveness
- added a new metric to measure the number of leaf nodes visited for each iteration
- updated the results table for a more meaningful comparison
- Dec 8, 2013, fixed the download link
- Dec 7, 2013, fixed article images
References
[1] Russell, Stuart J.; Norvig, Peter (2003), Artificial Intelligence: A Modern Approach (2nd ed.), Upper Saddle River,
New Jersey: Prentice Hall, ISBN 0-13-790395-2
[2] Aske Plaat, Jonathan Schaeffer, Wim Pijls, Arie de Bruin (1995). A New Paradigm for Minimax Search. Technical Report EUR-CS-95-03
[3] Aske Plaat, Jonathan Schaeffer, Wim Pijls, Arie de Bruin (1996). Best-First Fixed-Depth Minimax Algorithms. Artificial Intelligence, Vol. 87, Nos. 1-2, pp. 255-293. ISSN 0004-3702

