Introduction
This article is for those who need the FASTEST hasher for their SMALL keys.
Update 2019-Oct-30
Fasten your belts, the fastest got boosted by reducing 3 instructions...
#define _PADr_KAZE(x, n) ( ((x) << (n))>>(n) )
uint32_t FNV1A_Pippip_Yurii(const char *str, size_t wrdlen) {
const uint32_t PRIME = 591798841; uint32_t hash32; uint64_t hash64 = 14695981039346656037;
size_t Cycles, NDhead;
if (wrdlen > 8) {
Cycles = ((wrdlen - 1)>>4) + 1; NDhead = wrdlen - (Cycles<<3);
#pragma nounroll
for(; Cycles--; str += 8) {
hash64 = ( hash64 ^ (*(uint64_t *)(str)) ) * PRIME;
hash64 = ( hash64 ^ (*(uint64_t *)(str+NDhead)) ) * PRIME;
}
} else
hash64 = ( hash64 ^ _PADr_KAZE(*(uint64_t *)(str+0), (8-wrdlen)<<3) ) * PRIME;
hash32 = (uint32_t)(hash64 ^ (hash64>>32)); return hash32 ^ (hash32 >> 16);
}
Two of five benchmarks in Yann's suite (xxHash) show these 3 instructions matter!
Note: GCC 7.3.0 executable was used, on i5-7200U @3.1GHz turbo.
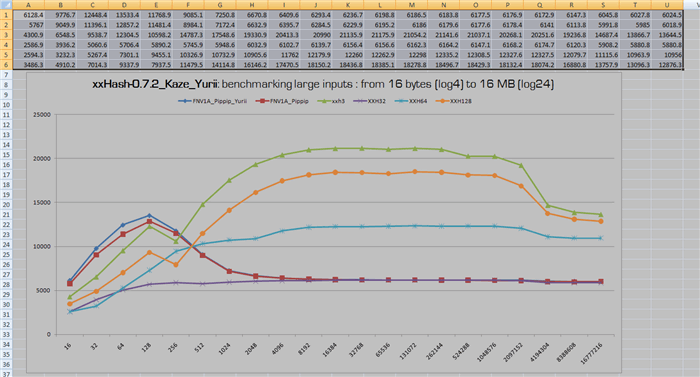

Let's see what reducing of above 3 instructions, along with telling Intel v19.0 not to unroll, deliver on my i5-7200U:
KAZE_www.byronknoll.com_cmix-v18.zip_english.dic:
44880 lines read
131072 elements in the table (17 bits)
Pippip_Yurii: 2325 [ 6822] ! Speed Brutality !
Pippip: 3046 [ 6822]
Totenschiff: 3308 [ 6818]
Yorikke: 2672 [ 6883]
wyhash: 5072 [ 6812]
FNV-1a: 4310 [ 6833]
CRC-32: 5251 [ 6891]
iSCSI CRC: 3631 [ 6785]
"KAZE_IPS_(3_million_IPs_dot_format).TXT":
2995394 lines read
8388608 elements in the table (23 bits)
Pippip_Yurii: 407608 [476410]
Pippip: 443241 [476410]
Totenschiff: 511103 [476467]
Yorikke: 530381 [506954]
wyhash: 551765 [476412]
FNV-1a: 716070 [477067]
CRC-32: 605808 [472854]
iSCSI CRC: 391876 [479542] ! Still 1st !
"KAZE_Word-list_12,561,874_wikipedia-en-html.tar.wrd":
12561874 lines read
33554432 elements in the table (25 bits)
Pippip_Yurii: 2018116 [2084750] ! Speed Brutality !
Pippip: 2148478 [2084750]
Totenschiff: 2313835 [2084381]
Yorikke: 2383182 [2099673]
wyhash: 2787755 [2081865]
FNV-1a: 3123546 [2081195]
CRC-32: 2998909 [2075088]
iSCSI CRC: 2154190 [2077725]
KAZE_www.gutenberg.org_ebooks_100.txt:
138578 lines read
524288 elements in the table (19 bits)
Pippip_Yurii: 17178 [31196] ! Speed Brutality !
Pippip: 18174 [31196]
Totenschiff: 20336 [31134]
Yorikke: 23733 [31139]
wyhash: 28118 [31260]
FNV-1a: 49246 [31178]
CRC-32: 41789 [31210]
iSCSI CRC: 22606 [31248]
KAZE_www.maximumcompression.com_english.dic:
354951 lines read
1048576 elements in the table (20 bits)
Pippip_Yurii: 41439 [53393] ! Speed Brutality !
Pippip: 44554 [53393]
Totenschiff: 48462 [53546]
Yorikke: 49988 [53782]
wyhash: 61612 [53996]
FNV-1a: 68586 [53896]
CRC-32: 65252 [54020]
iSCSI CRC: 46324 [53915]
KAZE_enwiki-20190920-pages-articles.xml.SORTED.wrd:
42206534 lines read
134217728 elements in the table (27 bits)
Pippip_Yurii: 8253384 [5996107] ! Speed Brutality !
Pippip: 8734972 [5996107]
Totenschiff: 9215109 [5996598]
Yorikke: 9271283 [6011605]
wyhash: 11241704 [5991525]
FNV-1a: 12017273 [5980248]
CRC-32: 11570725 [5843653]
iSCSI CRC: 8433784 [5803092]
It turns out, no hasher can outperform FNV1A-Pippip-Yurii on English wordlists, of any size :P
The three benchmark suites:
- Peter Kankowski's hash.c compiled with Intel v19.0;
- Yann Collet's xxHash-0.7.2 compiled with GCC v7.3.0;
- Sanmayce's Lookuperorama.c compiled with Intel v19.0 and GCC v7.3.0;
Lookuperorama.c_r7-.zip (252,329,722 bytes):
https://drive.google.com/file/d/1Uote1BFXJNwvMep13jlIfGyUAJlO1v20/view?usp=sharing
Update 2019-Oct-27
Wanted to clarify the "SMALL" term by running Yann's hashBench suite taken from his github repository, it currently features 5 different scenarios/benchmarks, more in-depth testing at his blog: http://fastcompression.blogspot.com/2019/03/presenting-xxh3.html
It goes like this (on my laptop with i5-7200U @3.1GHz turbo):
E:\Lookuperorama.c_r6\xxHash-0.7.2_Kaze\tests\bench>main --list
available hashes :
FNV1A_Pippip, xxh3, XXH32, XXH64, XXH128
E:\Lookuperorama.c_r6\xxHash-0.7.2_Kaze\tests\bench>main --maxs=384 --minl=7
=== benchmarking 5 hash functions ===
benchmarking large inputs : from 128 bytes (log7) to 128 MB (log27)
FNV1A_Pippip, 12854.7, 11440.3, 8929.2, 7174.9, 6636.1, 6394.0,
6283.3, 6228.9, 6195.0, 6182.2, 6149.4, 6134.6, 6148.0, 6116.3,
6130.5, 5988.9, 6026.9, 6018.3, 6019.6, 6023.4, 6026.5
xxh3 , 12284.3, 10600.1, 14781.2, 17586.9, 19274.7, 20418.2,
20950.6, 21046.0, 21261.7, 21080.3, 21184.1, 21063.7, 20386.1,
20333.4, 19406.0, 14742.3, 13837.3, 13064.6, 13355.9, 13316.7, 13297.0
XXH32 , 5726.2, 5414.3, 5763.7, 5961.1, 6059.9, 6116.2,
6147.3, 6162.2, 6161.0, 6163.9, 6170.6, 6171.3, 6170.8,
6166.7, 6110.5, 5897.7, 5890.4, 5885.5, 5893.9, 5897.4, 5808.5
XXH64 , 6729.2, 9030.5, 10232.1, 10780.8, 11709.2, 12022.1,
12175.7, 12262.5, 12264.8, 12305.7, 12330.0, 12313.2, 12323.3, 12343.0,
12113.4, 11102.2, 10961.6, 10973.9, 10985.3, 10983.9, 10957.8
XXH128 , 9355.2, 7935.8, 11494.6, 14218.5, 16195.2, 17538.0,
18248.4, 18559.3, 18504.8, 18585.5, 18541.0, 18513.6, 18173.4,
18149.1, 17032.7, 13786.5, 13095.0, 12948.7, 12683.0, 12806.4, 12764.3
...
My hope was 'Pippip' to "hold the line" up to 280 bytes long keys, yes, the tweets maximal length, by chance the XXH3 brutal domination starts somewhere at this mark.
Update 2019-Oct-26
It's time for FASTESTNESS!
When tweaking my matchfinder, I saw how many ideas were left unexploited in old hashers, exploittime.
First the console run of Peter Kankowski's hash suite (being one very precise micro-benchmark) at https://www.strchr.com/hash_functions, it shows the Pippip's supremacy while hashing the dictionary of most powerful compressor on Internet - CMIX:
The last column (in square brackets) shows collisions, the number before collisions is the top time.
If you happen to hash English words (~12 million distinct) or Shakespeare's verses, 'Pippip' screams:
KAZE_www.byronknoll.com_cmix-v18.zip_english.dic:
44880 lines read
131072 elements in the table (17 bits)
Pippip: 2463 [ 6822] ! Screaming speed !
Totenschiff: 2619 [ 6818]
Yorikke: 2674 [ 6883]
wyhash: 4371 [ 6812]
YoshimitsuTRIAD: 4035 [ 7006]
FNV-1a: 4283 [ 6833]
Larson: 4297 [ 6830]
CRC-32: 4342 [ 6891]
Murmur2: 4393 [ 6820]
Murmur3: 4320 [ 6874]
XXHfast32: 4573 [ 6812]
XXHstrong32: 4660 [ 6819]
iSCSI CRC: 3600 [ 6785]
"KAZE_Word-list_12,561,874_wikipedia-en-html.tar.wrd":
12561874 lines read
33554432 elements in the table (25 bits)
Pippip: 2143388 [2084750] ! iSCSI CRC in the mirror,
are you kidding me, what a beautiful brutality !
Totenschiff: 2300133 [2084381]
Yorikke: 2367380 [2099673]
wyhash: 2790935 [2081865]
YoshimitsuTRIAD: 2517971 [2084931]
FNV-1a: 3119297 [2081195]
Larson: 3017590 [2080111]
CRC-32: 2976146 [2075088]
Murmur2: 2858856 [2081476]
Murmur3: 2864098 [2082084]
XXHfast32: 3084063 [2084164]
XXHstrong32: 3191575 [2084514]
iSCSI CRC: 2155141 [2077725]
KAZE_www.gutenberg.org_ebooks_100.txt:
138578 lines read
524288 elements in the table (19 bits)
Pippip: 18195 [31196] ! Commentless I am !
Totenschiff: 20313 [31134]
Yorikke: 23758 [31139]
wyhash: 28252 [31260]
YoshimitsuTRIAD: 27014 [31316]
FNV-1a: 49282 [31178]
Larson: 48770 [31406]
CRC-32: 41691 [31210]
Murmur2: 31558 [31203]
Murmur3: 31336 [31308]
XXHfast32: 24637 [31146]
XXHstrong32: 27266 [31118]
iSCSI CRC: 22487 [31248]
KAZE_www.maximumcompression.com_english.dic:
354951 lines read
1048576 elements in the table (20 bits)
Pippip: 44669 [53393] ! Fastest on all major English words,
a tear is falling !
Totenschiff: 48633 [53546]
Yorikke: 49951 [53782]
wyhash: 61668 [53996]
YoshimitsuTRIAD: 54825 [53658]
FNV-1a: 68106 [53896]
Larson: 67358 [54076]
CRC-32: 64756 [54020]
Murmur2: 62863 [53857]
Murmur3: 62782 [53983]
XXHfast32: 68146 [53411]
XXHstrong32: 70334 [53391]
iSCSI CRC: 46122 [53915]
Simply, all my benchmarking experience led to writing the fastest hash function for tiny keys (1..64 bytes long) - FNV1A-Pippip, let us see what numbers say, in the showdown, other participants are:
- Wang's
WYHASH - the current #1 in speed department according to SMHASHER - Yann's
XXH (taken from latest v0.7.2) family - somewhere on top according to SMHASHER - SSE4.2 iSCSI
CRC32 SHA3-224
The hardware CRC32 was the topmonster for a long time, no more, now the supermonster 'Pippip' dethroned it, see for more versatile benchmarks the IDZ Intel Developer Zone forum (a link further below).
I have written Lookuperorama.c - the first both SYNTHETIC and REAL-WORLD benchmark for hash-table lookuping, current revision 6 is attached as .ZIP at the top.
The .C source and how to compile it under GCC and ICC:
_MakeEXE_Lookuperorama_GCC.bat
gcc -O3 -msse4.1 -fomit-frame-pointer Lookuperorama.c
-o Lookuperorama_GCC-7.3.0_WY_64bit.exe -D_N_XMM -D_N_prefetch_4096
-D_N_alone -D_N_HIGH_PRIORITY -DHashInBITS=24 -DHashChunkSizeInBITS=24
-DRAMpoolInKB=5120 -DBtreeHEURISTIC -D_WIN32_ENVIRONMENT_ -DLongestLineInclusive=64 -D_N_WY
gcc -O3 -msse4.1 -fomit-frame-pointer Lookuperorama.c
-o Lookuperorama_GCC-7.3.0_Pippip_64bit.exe -D_N_XMM -D_N_prefetch_4096
-D_N_alone -D_N_HIGH_PRIORITY -DHashInBITS=24 -DHashChunkSizeInBITS=24
-DRAMpoolInKB=5120 -DBtreeHEURISTIC -D_WIN32_ENVIRONMENT_
-DLongestLineInclusive=64 -D_N_Pippip
gcc -O3 -msse4.1 -fomit-frame-pointer Lookuperorama.c xxhash.c
-o Lookuperorama_GCC-7.3.0_XXH64_64bit.exe -D_N_XMM -D_N_prefetch_4096
-D_N_alone -D_N_HIGH_PRIORITY -DHashInBITS=24 -DHashChunkSizeInBITS=24
-DRAMpoolInKB=5120 -DBtreeHEURISTIC -D_WIN32_ENVIRONMENT_ -DLongestLineInclusive=64 -D_N_XXH64
gcc -O3 -msse4.1 -fomit-frame-pointer Lookuperorama.c xxhash.c
-o Lookuperorama_GCC-7.3.0_XXH3_64bit.exe -D_N_XMM -D_N_prefetch_4096
-D_N_alone -D_N_HIGH_PRIORITY -DHashInBITS=24 -DHashChunkSizeInBITS=24
-DRAMpoolInKB=5120 -DBtreeHEURISTIC -D_WIN32_ENVIRONMENT_ -DLongestLineInclusive=64 -D_N_XXH3
gcc -O3 -msse4.1 -fomit-frame-pointer Lookuperorama.c
-o Lookuperorama_GCC-7.3.0_CRC32C_64bit.exe -D_N_XMM -D_N_prefetch_4096
-D_N_alone -D_N_HIGH_PRIORITY -DHashInBITS=24 -DHashChunkSizeInBITS=24
-DRAMpoolInKB=5120 -DBtreeHEURISTIC -D_WIN32_ENVIRONMENT_ -DLongestLineInclusive=64 -D_N_CRC32C
gcc -O3 -msse4.1 -fomit-frame-pointer Lookuperorama.c
-o Lookuperorama_GCC-7.3.0_SHA3_64bit.exe -D_N_XMM -D_N_prefetch_4096
-D_N_alone -D_N_HIGH_PRIORITY -DHashInBITS=24 -DHashChunkSizeInBITS=24
-DRAMpoolInKB=5120 -DBtreeHEURISTIC -D_WIN32_ENVIRONMENT_ -DLongestLineInclusive=64 -D_N_SHA3
_MakeEXE_Lookuperorama_ICL.bat
icl /TP /O3 /arch:SSE4.1 Lookuperorama.c -D_N_XMM -D_N_prefetch_4096
-D_N_alone -D_N_HIGH_PRIORITY -D_icl_mumbo_jumbo_ /FAcs -DHashInBITS=24
-DHashChunkSizeInBITS=24 -DRAMpoolInKB=5120 -DBtreeHEURISTIC
-D_WIN32_ENVIRONMENT_ -DLongestLineInclusive=64 -D_N_WY
copy Lookuperorama.exe Lookuperorama_ICC-v19.0_WY_64bit.exe /y
icl /TP /O3 /arch:SSE4.1 Lookuperorama.c -D_N_XMM -D_N_prefetch_4096
-D_N_alone -D_N_HIGH_PRIORITY -D_icl_mumbo_jumbo_ /FAcs -DHashInBITS=24
-DHashChunkSizeInBITS=24 -DRAMpoolInKB=5120 -DBtreeHEURISTIC
-D_WIN32_ENVIRONMENT_ -DLongestLineInclusive=64 -D_N_Pippip
copy Lookuperorama.exe Lookuperorama_ICC-v19.0_Pippip_64bit.exe /y
icl /TP /O3 /arch:SSE4.1 Lookuperorama.c xxhash.c -D_N_XMM
-D_N_prefetch_4096 -D_N_alone -D_N_HIGH_PRIORITY -D_icl_mumbo_jumbo_ /FAcs
-DHashInBITS=24 -DHashChunkSizeInBITS=24 -DRAMpoolInKB=5120
-DBtreeHEURISTIC -D_WIN32_ENVIRONMENT_ -DLongestLineInclusive=64 -D_N_XXH64
copy Lookuperorama.exe Lookuperorama_ICC-v19.0_XXH64_64bit.exe /y
icl /TP /O3 /arch:SSE4.1 Lookuperorama.c xxhash.c -D_N_XMM
-D_N_prefetch_4096 -D_N_alone -D_N_HIGH_PRIORITY -D_icl_mumbo_jumbo_ /FAcs
-DHashInBITS=24 -DHashChunkSizeInBITS=24 -DRAMpoolInKB=5120 -DBtreeHEURISTIC
-D_WIN32_ENVIRONMENT_ -DLongestLineInclusive=64 -D_N_XXH3
copy Lookuperorama.exe Lookuperorama_ICC-v19.0_XXH3_64bit.exe /y
icl /TP /O3 /arch:SSE4.1 Lookuperorama.c -D_N_XMM -D_N_prefetch_4096
-D_N_alone -D_N_HIGH_PRIORITY -D_icl_mumbo_jumbo_ /FAcs -DHashInBITS=24
-DHashChunkSizeInBITS=24 -DRAMpoolInKB=5120 -DBtreeHEURISTIC
-D_WIN32_ENVIRONMENT_ -DLongestLineInclusive=64 -D_N_CRC32C
copy Lookuperorama.exe Lookuperorama_ICC-v19.0_CRC32C_64bit.exe /y
icl /TP /O3 /arch:SSE4.1 Lookuperorama.c -D_N_XMM -D_N_prefetch_4096
-D_N_alone -D_N_HIGH_PRIORITY -D_icl_mumbo_jumbo_ /FAcs -DHashInBITS=24
-DHashChunkSizeInBITS=24 -DRAMpoolInKB=5120 -DBtreeHEURISTIC
-D_WIN32_ENVIRONMENT_ -DLongestLineInclusive=64 -D_N_SHA3
copy Lookuperorama.exe Lookuperorama_ICC-v19.0_SHA3_64bit.exe /y
Funny, I tried latest Intel v19.0 compiler and GCC 7.3.0, the choice of GCC team not to unroll proved superior since tests are with short keys, ICC decided to unroll, try and see the results yourself.
For '1001 Nights' (15,583,440 bytes) and 10 hash-tables 24bit each, ICC v19.0, i7-3630QM, Windows 10:
Hasher | Collisions | Synthetic/Taxed Hashing Speed for ALL keys |
----------------------------------------------------------------------------------
SSE4.2 iSCSI CRC32 | 23,737,621 | 208,334,772 KEYS-PER-SECOND / 5,565,507 Keys/s |
SHA3-224 | 23,737,389 | 104,465 KEYS-PER-SECOND / 102,052 Keys/s |
----------------------------------------------------------------------------------
For '1001 Nights' (15,583,440 bytes) and 10 hash-tables 24bit each, GCC 7.3.0, i7-3630QM, Windows 10:
Hasher | Collisions | Synthetic/Taxed Hashing Speed for ALL keys |
----------------------------------------------------------------------------------
FNV1A-Pippip | 23,738,813 | 269,144,006 KEYS-PER-SECOND / 5,026,910 Keys/s |
WYHASH | 23,738,215 | 134,688,314 KEYS-PER-SECOND / 5,026,910 Keys/s |
XXH64 | 23,737,218 | 115,861,992 KEYS-PER-SECOND / 4,869,819 Keys/s |
XXH3 | 23,735,377 | 174,702,219 KEYS-PER-SECOND / 5,026,910 Keys/s |
----------------------------------------------------------------------------------
Note 1: Collisions are cumulative for all the 10 hash-tables.
Note 2: 'Taxed' means it is polluted with many random/uncached RAM accesses.
This is how the console dump for 'Pippip' looks like:
F:\Lookuperorama.c_r6>Lookuperorama_GCC-7.3.0_Pippip_64bit.exe
"Arabian_Nights_complete.html" x 24 7500 i
Current priority class is REALTIME_PRIORITY_CLASS.
Allocating Source-Buffer 14 MB ...
Allocating Source-Buffer 14 MB (REVERSED) ...
Allocating Target-Buffer 46 MB ...
Allocating Verification-Buffer 14 MB ...
Leprechaun: Memory pool for B-tress is 7,500 MB.
Leprechaun: In this revision 128MB 10-way hash is used which results in
10 x 16,777,216 internal B-Trees of order 3.
Leprechaun: In this revision, 1 pass is to be executed.
Leprechaun: Allocating HASH memory 1,342,177,345 bytes ... OK
Leprechaun: Allocating memory for B-tress 7501 MB ... OK
Leprechaun: Size of input file: 15,583,440
RAW Hashing Speed for key 15,583,440 bytes long = 6,600,355,781 6,
691,043,366 6,688,171,673 6,691,043,366 6,691,043,366 | 6,691,043,366 BYTES-PER-SECOND
RAW Hashing Speed for keys 04 bytes long = 916,672,764 KEYS-PER-SECOND; all in 17 clocks
RAW Hashing Speed for keys 06 bytes long = 916,672,647 KEYS-PER-SECOND; all in 17 clocks
RAW Hashing Speed for keys 08 bytes long = 973,964,562 KEYS-PER-SECOND; all in 16 clocks
RAW Hashing Speed for keys 10 bytes long = 486,982,218 KEYS-PER-SECOND; all in 32 clocks
RAW Hashing Speed for keys 12 bytes long = 486,982,156 KEYS-PER-SECOND; all in 32 clocks
RAW Hashing Speed for keys 14 bytes long = 486,982,093 KEYS-PER-SECOND; all in 32 clocks
RAW Hashing Speed for keys 16 bytes long = 486,982,031 KEYS-PER-SECOND; all in 32 clocks
RAW Hashing Speed for keys 18 bytes long = 324,654,645 KEYS-PER-SECOND; all in 48 clocks
RAW Hashing Speed for keys 36 bytes long = 247,355,634 KEYS-PER-SECOND; all in 63 clocks
RAW Hashing Speed for keys 64 bytes long = 197,257,936 KEYS-PER-SECOND; all in 79 clocks
The hash scanner - hashing in one pass all orders - TESTING CUMULATIVE PERFORMANCE...
RAW Hashing Speed for keys 4,6,8,10,12,14,16,18,36,64 bytes long = 269,
144,006 KEYS-PER-SECOND; all in 579 clocks
Leprechaun: Inserting keys/BBs of order 004 into B-trees, free RAM in B-tree pool is
00,007,500 MB; Pass #001 of 1 ... DONE; 00,000,185,110 B-trees have been rooted so far;
HashtableS_Utilization = 000%; Keys/s = 012,456,784
Leprechaun: Inserting keys/BBs of order 006 into B-trees, free RAM in B-tree pool is
00,007,491 MB; Pass #001 of 1 ... DONE; 00,001,330,364 B-trees have been rooted so far;
HashtableS_Utilization = 000%; Keys/s = 007,495,639
Leprechaun: Inserting keys/BBs of order 008 into B-trees, free RAM in B-tree pool is
00,007,432 MB; Pass #001 of 1 ... DONE; 00,004,317,931 B-trees have been rooted so far;
HashtableS_Utilization = 002%; Keys/s = 006,734,413
Leprechaun: Inserting keys/BBs of order 010 into B-trees, free RAM in B-tree pool is
00,007,264 MB; Pass #001 of 1 ... DONE; 00,009,402,389 B-trees have been rooted so far;
HashtableS_Utilization = 005%; Keys/s = 005,631,886
Leprechaun: Inserting keys/BBs of order 012 into B-trees, free RAM in B-tree pool is
00,006,952 MB; Pass #001 of 1 ... DONE; 00,016,178,252 B-trees have been rooted so far;
HashtableS_Utilization = 009%; Keys/s = 005,246,945
Leprechaun: Inserting keys/BBs of order 014 into B-trees, free RAM in B-tree pool is
00,006,492 MB; Pass #001 of 1 ... DONE; 00,024,085,199 B-trees have been rooted so far;
HashtableS_Utilization = 014%; Keys/s = 004,911,259
Leprechaun: Inserting keys/BBs of order 016 into B-trees, free RAM in B-tree pool is
00,005,903 MB; Pass #001 of 1 ... DONE; 00,032,694,767 B-trees have been rooted so far;
HashtableS_Utilization = 019%; Keys/s = 005,246,944
Leprechaun: Inserting keys/BBs of order 018 into B-trees, free RAM in B-tree pool is
00,005,208 MB; Pass #001 of 1 ... DONE; 00,041,744,572 B-trees have been rooted so far;
HashtableS_Utilization = 024%; Keys/s = 004,594,169
Leprechaun: Inserting keys/BBs of order 036 into B-trees, free RAM in B-tree pool is
00,004,424 MB; Pass #001 of 1 ... DONE; 00,051,646,708 B-trees have been rooted so far;
HashtableS_Utilization = 030%; Keys/s = 004,003,958
Leprechaun: Inserting keys/BBs of order 064 into B-trees, free RAM in B-tree pool is
00,003,120 MB; Pass #001 of 1 ... DONE; 00,061,668,508 B-trees have been rooted so far;
HashtableS_Utilization = 036%; Keys/s = 003,598,932
Leprechaun: (Total Hashing Speed) plus Searches-n-Inserts Per Second: 5,026,910 SNIPS
Number Of Bits (Slots=1<<Bits): 24
Number Of Hash Collisions(Distinct WORDs - Number Of Trees): 23,738,813
Number Of Trees(GREATER THE BETTER): 61,668,508
Number Of LEAFs(littler THE BETTER) not counting ROOT LEAFs: 8,688,301
Highest Tree not counting ROOT Level i.e. CORONA levels(littler THE BETTER): 2
Some links where 'Pippip' was benchmarked:
And the .C and .ASM source:
#define _PADr_KAZE(x, n) ( ((x) << (n))>>(n) )
uint32_t FNV1A_Pippip(const char *str, uint32_t wrdlen) {
const uint32_t PRIME = 591798841; uint32_t hash32;
uint64_t hash64 = 14695981039346656037; const char *p = str;
int i, Cycles, NDhead;
if (wrdlen > 8) {
Cycles = ((wrdlen - 1)>>4) + 1; NDhead = wrdlen - (Cycles<<3);
for(i=0; i<Cycles; i++) {
hash64 = ( hash64 ^ (*(uint64_t *)(p)) ) * PRIME;
hash64 = ( hash64 ^ (*(uint64_t *)(p+NDhead)) ) * PRIME;
p += 8;
}
} else
hash64 = ( hash64 ^ _PADr_KAZE(*(uint64_t *)(p+0), (8-wrdlen)<<3) ) * PRIME;
hash32 = (uint32_t)(hash64 ^ (hash64>>32)); return hash32 ^ (hash32 >> 16);
}
If 'Pippip' happens to be outsped by another function, please write me to me in the comment section.
Enfun!
End of Update 2019-Oct-26
Who is that bad boy?
FNV1A_YoshimitsuTRIAD - a C etude which hashed one 256bytes block at 14GB/s on i7-4770K.
Also, on PowerPC 440 and Cortex-A8 processors, 'Luckylight' (its Japanese meaning) simply overshadowed everything known to me.
Long story short, my experience with hashing the most needed range (7..255 bytes long keys) is that 'YoshimitsuTRIAD' slashes monstrously, it simply devours the keys at sick rate.
Until recently, I have not seen how Haswell performs, FNV1A_YoshimitsuTRIADiiXMM deserves special attention if XMM registers are available, this 96bytes stride variant of 'YoshimitsuTRIAD' hashed 256bytes block at 18GB/s, yippee.
As I can see things, 'YoshimitsuTRIAD' is the weapon of choice when it comes to English language phrases/sentences hashing, an area of great importance.
First, I am thankful to Fantasy (Dubai), Mr.Eiht (Germany), m^2 (Poland) and Harold (Holland).
They helped me and I still didn't return the favor, so by sharing the final edition of my best table lookup hash etude, I hope to gladden their hearts.
Or, as one unforgettable character (full of personality) from the Russian/Georgian/Armenian classic 'MIMINO' says:
"When he feels gladdened then I will feel that I am gladdened too. When I am gladdened then I will deliver in such a way that you too will be gladdened."
Below are the results after running 32bit code by Intel 12.1 compiler (/Ox used):
Linear speed on Harold's Rig (i7-4770K, 3500MHz):
Allocating HASH memory 512MB ... OK
Memory pool starting address: 00F40040 ... 64 byte aligned, OK
Info1: One second seems to have 1,000 clocks.
Info2: This CPU seems to be working at 3,499 MHz.
Copying a 256MB block 1024 times i.e. 256GB READ + 256GB WRITTEN ...
memcpy(): (256MB block); 262144MB copied in 19843 clocks or 13.211MB per clock
Fetching/Hashing a 64MB block 1024 times i.e. 64GB ...
BURST_Read_4DWORDS: (64MB block); 65536MB fetched in 4009 clocks or 16.347MB per clock
BURST_Read_8DWORDSi: (64MB block); 65536MB fetched in 4009 clocks or 16.347MB per clock
FNV1A_penumbra: (64MB block); 65536MB hashed in 3121 clocks or 20.998MB per clock
FNV1A_YoshimitsuTRIADiiXMM: (64MB block); 65536MB hashed in 3198 clocks or 20.493MB per clock
FNV1A_YoshimitsuTRIADii: (64MB block); 65536MB hashed in 5288 clocks or 12.393MB per clock
FNV1A_YoshimitsuTRIAD: (64MB block); 65536MB hashed in 4430 clocks or 14.794MB per clock
FNV1A_farolito: (64MB block); 65536MB hashed in 5726 clocks or 11.445MB per clock
FNV1A_Yorikke: (64MB block); 65536MB hashed in 4929 clocks or 13.296MB per clock
FNV1A_Yoshimura: (64MB block); 65536MB hashed in 5788 clocks or 11.323MB per clock
CRC32_SlicingBy8: (64MB block); 65536MB hashed in 36083 clocks or 1.816MB per clock
Fetching/Hashing a 2MB block 32*1024 times ...
BURST_Read_4DWORDS: (2MB block); 65536MB fetched in 2761 clocks or 23.736MB per clock
BURST_Read_8DWORDSi: (2MB block); 65536MB fetched in 2433 clocks or 26.936MB per clock
FNV1A_penumbra: (2MB block); 65536MB hashed in 1591 clocks or 41.192MB per clock
FNV1A_YoshimitsuTRIADiiXMM: (2MB block); 65536MB hashed in 1716 clocks or 38.191MB per clock
FNV1A_YoshimitsuTRIADii: (2MB block); 65536MB hashed in 3853 clocks or 17.009MB per clock
FNV1A_YoshimitsuTRIAD: (2MB block); 65536MB hashed in 3713 clocks or 17.650MB per clock
FNV1A_farolito: (2MB block); 65536MB hashed in 4087 clocks or 16.035MB per clock
FNV1A_Yorikke: (2MB block); 65536MB hashed in 4462 clocks or 14.688MB per clock
FNV1A_Yoshimura: (2MB block); 65536MB hashed in 4415 clocks or 14.844MB per clock
CRC32_SlicingBy8: (2MB block); 65536MB hashed in 35864 clocks or 1.827MB per clock
Fetching/Hashing a 128KB block 512*1024 times ...
BURST_Read_4DWORDS: (128KB block); 65536MB fetched in 2684 clocks or 24.417MB per clock
BURST_Read_8DWORDSi: (128KB block); 65536MB fetched in 3104 clocks or 21.113MB per clock
FNV1A_penumbra: (128KB block); 65536MB hashed in 1529 clocks or 42.862MB per clock
FNV1A_YoshimitsuTRIADiiXMM: (128KB block); 65536MB hashed in 1763 clocks or 37.173MB per clock
FNV1A_YoshimitsuTRIADii: (128KB block); 65536MB hashed in 4180 clocks or 15.678MB per clock
FNV1A_YoshimitsuTRIAD: (128KB block); 65536MB hashed in 3729 clocks or 17.575MB per clock
FNV1A_farolito: (128KB block); 65536MB hashed in 4539 clocks or 14.438MB per clock
FNV1A_Yorikke: (128KB block); 65536MB hashed in 4462 clocks or 14.688MB per clock
FNV1A_Yoshimura: (128KB block); 65536MB hashed in 4586 clocks or 14.290MB per clock
CRC32_SlicingBy8: (128KB block); 65536MB hashed in 35974 clocks or 1.822MB per clock
Fetching/Hashing a 16KB block 4*1024*1024 times ...
BURST_Read_4DWORDS: (16KB block); 65536MB fetched in 2247 clocks or 29.166MB per clock
BURST_Read_8DWORDSi: (16KB block); 65536MB fetched in 2277 clocks or 28.782MB per clock
FNV1A_penumbra: (16KB block); 65536MB hashed in 1528 clocks or 42.890MB per clock
FNV1A_YoshimitsuTRIADiiXMM: (16KB block); 65536MB hashed in 1607 clocks or 40.782MB per clock
FNV1A_YoshimitsuTRIADii: (16KB block); 65536MB hashed in 3729 clocks or 17.575MB per clock
FNV1A_YoshimitsuTRIAD: (16KB block); 65536MB hashed in 3666 clocks or 17.877MB per clock
FNV1A_farolito: (16KB block); 65536MB hashed in 4102 clocks or 15.977MB per clock
FNV1A_Yorikke: (16KB block); 65536MB hashed in 4587 clocks or 14.287MB per clock
FNV1A_Yoshimura: (16KB block); 65536MB hashed in 4461 clocks or 14.691MB per clock
CRC32_SlicingBy8: (16KB block); 65536MB hashed in 35834 clocks or 1.829MB per clock
Fetching/Hashing a 256bytes block 256*1024*1024 times ...
BURST_Read_4DWORDS: (256bytes block); 65536MB fetched in 2698 clocks or 24.291MB per clock
BURST_Read_8DWORDSi: (256bytes block); 65536MB fetched in 3136 clocks or 20.898MB per clock
FNV1A_penumbra: (256bytes block); 65536MB hashed in 3666 clocks or 17.877MB per clock
FNV1A_YoshimitsuTRIADiiXMM: (256bytes block); 65536MB hashed in 3470 clocks or 18.886MB per clock
FNV1A_YoshimitsuTRIADii: (256bytes block); 65536MB hashed in 4840 clocks or 13.540MB per clock
FNV1A_YoshimitsuTRIAD: (256bytes block); 65536MB hashed in 4516 clocks or 14.512MB per clock
FNV1A_farolito: (256bytes block); 65536MB hashed in 5522 clocks or 11.868MB per clock
FNV1A_Yorikke: (256bytes block); 65536MB hashed in 5117 clocks or 12.808MB per clock
FNV1A_Yoshimura: (256bytes block); 65536MB hashed in 5195 clocks or 12.615MB per clock
CRC32_SlicingBy8: (256bytes block); 65536MB hashed in 36004 clocks or 1.820MB per clock
Below, the results after running 32bit code by Intel 12.1 compiler (/Ox used):
Linear speed on Fantasy's 'Black-and-Red' Rig (i7-3930K, 4500MHz, CPU bus: 125MHz, RAM bus: 2400MHz Quad Channel):
FNV1A_YoshimitsuTRIAD: (64MB block); 65536MB hashed in 5728 clocks or 11.441MB per clock
CRC32_SlicingBy8: (64MB block); 65536MB hashed in 37544 clocks or 1.746MB per clock
FNV1A_YoshimitsuTRIAD: (2MB block); 65536MB hashed in 4560 clocks or 14.372MB per clock
CRC32_SlicingBy8: (2MB block); 65536MB hashed in 36394 clocks or 1.801MB per clock
FNV1A_YoshimitsuTRIAD: (16KB block); 65536MB hashed in 4390 clocks or 14.928MB per clock
CRC32_SlicingBy8: (16KB block); 65536MB hashed in 36210 clocks or 1.810MB per clock
Below, the results after running 32bit code by Intel 12.1 compiler (/Ox used):
Linear speed on Mr.Eiht's 'Redemption' Rig (i7 3930K 3.2GHz 8x4GB @1337MHz):
FNV1A_YoshimitsuTRIAD: (64MB block); 65536MB hashed in 7307 clocks or 8.969MB per clock
CRC32_SlicingBy8: (64MB block); 65536MB hashed in 44693 clocks or 1.466MB per clock
FNV1A_YoshimitsuTRIAD: (2MB block); 65536MB hashed in 5374 clocks or 12.195MB per clock
CRC32_SlicingBy8: (2MB block); 65536MB hashed in 43143 clocks or 1.519MB per clock
FNV1A_YoshimitsuTRIAD: (16KB block); 65536MB hashed in 5206 clocks or 12.589MB per clock
CRC32_SlicingBy8: (16KB block); 65536MB hashed in 42888 clocks or 1.528MB per clock
Below, the results after running 32bit code by Intel 12.1 compiler (/Ox used):
Linear speed on Sanmayce's 'Bonboniera' laptop (Core 2 T7500, 2200MHz):
FNV1A_penumbra: (64MB block); 65536MB hashed in 14445 clocks or 4.581MB per clock
FNV1A_YoshimitsuTRIAD: (64MB block); 65536MB hashed in 16115 clocks or 4.087MB per clock
CRC32_SlicingBy8: (64MB block); 65536MB hashed in 71573 clocks or 0.916MB per clock
FNV1A_penumbra: (2MB block); 65536MB hashed in 6568 clocks or 10.025MB per clock
FNV1A_YoshimitsuTRIAD: (2MB block); 65536MB hashed in 9750 clocks or 6.722MB per clock
CRC32_SlicingBy8: (2MB block); 65536MB hashed in 69763 clocks or 0.940MB per clock
FNV1A_penumbra: (16KB block); 65536MB hashed in 5819 clocks or 11.293MB per clock
FNV1A_YoshimitsuTRIAD: (16KB block); 65536MB hashed in 8986 clocks or 7.294MB per clock
CRC32_SlicingBy8: (16KB block); 65536MB hashed in 69467 clocks or 0.949MB per clock
Being an AMD fan (since the superb 'Barton') here come 'Zambezi' and 'Thuban' performances:
AMD FX-8120, 4515MHz = 21x215, L1 Data Cache: 8x16KB:
FNV1A_YoshimitsuTRIAD: (16KB block); 65536MB hashed in 5859 clocks or 11.186MB per clock
CRC32_SlicingBy8: (16KB block); 65536MB hashed in 44437 clocks or 1.475MB per clock
AMD Phenom II X6 1600T, 4000MHz = 16x250, FSB Frequency: 250MHz, L1 Data Cache: 6x64KB:
FNV1A_YoshimitsuTRIAD: (16KB block); 65536MB hashed in 5769 clocks or 11.360MB per clock
CRC32_SlicingBy8: (16KB block); 65536MB hashed in 34650 clocks or 1.891MB per clock
And a word for collision performance: problemless.
An excerpt from one of the tortures:
Purpose: to compare FNV1A_Yoshimura and CRC32 by giving the highest number of collisions,
i.e. the deepest nest/layer, the-lesser-the-better.
Keys are all BINARY strings from 0..18446744073709551615, i.e. all 64bit values at some step,
look the sample below.
1111111111111111111111111111111111111111111111111111111111111111
=
18446744073709551615
18,446,744,073,709,551,616 = 2^64
thousand
million
billion
trillion
quadrillion
quintillion
Note1: On T7500 2200MHz the full cycle took 240h with step 111,111,111:
for (QUADR = 0; QUADR <= ((unsigned long long)1<<32)*((unsigned long long)1<<32)-1;
QUADR=QUADR+3111111111) {...}
Note2: The keys look like (at step 3,111,111,111) these:
0000,0000,0000,0000,0000,0000,0000,0000,0000,0000,0000,0000,0000,0000,0000,0000
0000,0000,0000,0000,0000,0000,0000,0000,1011,1001,0110,1111,1100,1001,1100,0111 i.e. 3111111111
0000,0000,0000,0000,0000,0000,0000,0001,0111,0010,1101,1111,1001,0011,1000,1110 i.e. 6222222222
0000,0000,0000,0000,0000,0000,0000,0010,0010,1100,0100,1111,0101,1101,0101,0101
0000,0000,0000,0000,0000,0000,0000,0010,1110,0101,1011,1111,0010,0111,0001,1100
0000,0000,0000,0000,0000,0000,0000,0011,1001,1111,0010,1110,1111,0000,1110,0011
0000,0000,0000,0000,0000,0000,0000,0100,0101,1000,1001,1110,1011,1010,1010,1010
And just for the fun of it, I did similar benchmark with my dispersion 'TRISMUS' 1+ trillion 1Kb text chunks torture package (source at homepage).
Those 1,000,000,000,000 keys were 128bytes long Knight-Tour derivatives:
D:\_KAZE>Knight-Tour_FNV1A_YoshimitsuTRIADii_vs_CRC32_TRISMUS.exe a8 4000000000
...
Polynomial used:
CRC32: 0x8F6E37A0
KEYS to be hashed = 4,000,000,000x4x64
HashSizeInBits = 27
ReportAtEvery = 134,217,727
Allocating HASH memory 512MB ... OK
Allocating HASH memory 512MB ... OK
The first KT:
A8C7E8G7H5G3H1F2H3G1E2C1A2B4A6B8D7F8H7G5F7H8G6H4G2E1C2A1B3A5B7D8C6A7C8E7G8
H6G4H2F1D2B1A3B5D6F5D4F3E5C4B2D3F4E6C5A4B6D5F6E4C3D1E3
...
FNV1A_YoshimitsuTRIADii: Keys = 0,000,134,217,729;
1 x MAXcollisionsAtSomeSlots = 0,012; FeeSlots = 50,530,128
CRC32 0x8F6E37A0, iSCSI: Keys = 0,000,134,217,729;
4 x MAXcollisionsAtSomeSlots = 0,011; FeeSlots = 49,561,215
FNV1A_YoshimitsuTRIADii: Keys = 0,000,268,435,457;
3 x MAXcollisionsAtSomeSlots = 0,015; FeeSlots = 19,089,321
CRC32 0x8F6E37A0, iSCSI: Keys = 0,000,268,435,457;
4 x MAXcollisionsAtSomeSlots = 0,014; FeeSlots = 18,307,048
FNV1A_YoshimitsuTRIADii: Keys = 0,000,402,653,185;
1 x MAXcollisionsAtSomeSlots = 0,019; FeeSlots = 07,194,504
CRC32 0x8F6E37A0, iSCSI: Keys = 0,000,402,653,185;
8 x MAXcollisionsAtSomeSlots = 0,017; FeeSlots = 06,762,415
FNV1A_YoshimitsuTRIADii: Keys = 0,000,536,870,913;
2 x MAXcollisionsAtSomeSlots = 0,021; FeeSlots = 02,708,588
CRC32 0x8F6E37A0, iSCSI: Keys = 0,000,536,870,913;
2 x MAXcollisionsAtSomeSlots = 0,020; FeeSlots = 02,496,170
FNV1A_YoshimitsuTRIADii: Keys = 0,000,671,088,641;
2 x MAXcollisionsAtSomeSlots = 0,023; FeeSlots = 01,022,485
CRC32 0x8F6E37A0, iSCSI: Keys = 0,000,671,088,641;
2 x MAXcollisionsAtSomeSlots = 0,023; FeeSlots = 00,922,884
...
FNV1A_YoshimitsuTRIADii: Keys = 1,000,056,291,329;
1 x MAXcollisionsAtSomeSlots = 7,930; FeeSlots = 00,000,000
CRC32 0x8F6E37A0, iSCSI: Keys = 1,000,056,291,329;
2 x MAXcollisionsAtSomeSlots = 7,910; FeeSlots = 00,000,000
As you can see, the ideal dispersion would be 1,000,056,291,329/134,217,727 = 7451 MAXcollisionsAtSomeSlots, both YoshimitsuTRIADii & CRC32 did well.
And for those who want to experiment and write their own hashers, I included (in the download section), two simple tools (Fury & YoYo) allowing to test respectively Speed Performance & Dispersion Performance.
The collision benchmark called '~3 million IPs (dot format)' is included:
D:\_KAZE>YoYo_r2.exe IPS.TXT 20
YoYo - [CR]LF lines hasher, r.2 copyleft Kaze.
Note1: Incoming textual file can exceed 4GB and lines can be up to 1048576 chars long.
Note2: FNV1A_YoshimitsuTRIADiiXMM needs SSE4.1, so if not present YoYo will crash.
Polynomial(s) used:
CRC32C2_8slice: 0x8F6E37A0
HashSizeInBits = 20
Allocating KEY memory 1024KB ... OK
Allocating HASH memory 4MB ... OK
Allocating HASH memory 4MB ... OK
Allocating HASH memory 4MB ... OK
Hashing all the LF ending lines encountered in 42,892,307 bytes long file ...
Keys vs Slots ratio: 2:1 or 2,995,394:1,048,576
FNV1A_YoshimitsuTRIADiiXMM : Keys = 2,995,394; 1 x MAXcollisionsAtSomeSlots = 15;
HASHfreeSLOTS = 0,059,943; HashUtilization = 094%; Collisions = 2,006,761
FNV1A_YoshimitsuTRIADii : Keys = 2,995,394; 1 x MAXcollisionsAtSomeSlots = 15;
HASHfreeSLOTS = 0,059,943; HashUtilization = 094%; Collisions = 2,006,761
CRC32C2_8slice : Keys = 2,995,394; 1 x MAXcollisionsAtSomeSlots = 15;
HASHfreeSLOTS = 0,062,064; HashUtilization = 094%; Collisions = 2,008,882
Physical Lines: 2,995,394
Shortest Line : 7
Longest Line : 15
Performance: 38126.495 bytes per clock
Background
Ha, background, I remember while writing 'YoshimitsuTRIAD', I was listening to this cuore song for hours on end:
Just this once
Let me tell you you're the sweetest thing
The love in every song I sing
The music in my ears and everything
Happiness writes white
Maybe that isn't true tonight
And things you know you might forget
And other things I haven't told you yet
Close your eyes
Count to ten
Turn around
Back again
Hit the floor
Then once more
I'm still here
And it's all true
And it's all true
We don't need any kind of big parade
Just this once a little serenade
To celebrate this love we've made
We don't need
Don't need a big fanfare
This is just my heart laid bare
For anyone who might care
Go away
Round the world
Talk to all kinds of girls
But it's me you won't find
And you're mine
Close your eyes
Count to ten
Turn around
Back again
Hit the floor
Then once more
I'm still here
And it's all true, and it's all true, do you feel it too?
And it's all true, and it's all true, tell me do you feel it too?
/Tracey Thorn - It's All True/
Function homepage: http://www.sanmayce.com/Fastest_Hash/index.html
Two last things, don't complain that homepage of the bad boy is too-o-o long and second, the license, no license, it is 100% FREE.
Enjoy!
Points of Interest
To find the practical and most useful balance between overkill and underkill while being playful and LIFEFUL.
A man went into a pub and saw a dog sitting at a table playing poker with three men.
"Wow, what a smart dog!" he exclaimed.
"Nah, he's not much of a player, whenever he gets a good hand he wags his tail." a kibitzer said.
This dog reminds me of ... me.
History
FNV1A_Pippip written 2019-Oct-26FNV1A_YoshimitsuTRIAD written 2012-Oct-29

