Introduction
A friend of mine sent me a link to an interesting StackOverflow discussion this morning - it showcased the impact on performance caused by denormalized (underflow) floating point numbers. I was aware of the problem since I had to deal with that about ten years ago when it first hit us on Pentium 4 CPUs, which were exceptionally prone to it. However, I was surprised by the fact that performance impact is not alleviated even on modern hardware - one of StackOverflow users reported that Core i7 in 'flush to zero' mode was 47 times faster than when it had to deal with underflow numbers. That's bad.
Intrigued, I ran the code from that StackOverflow thread on a number of architectures. The results are shown below - first, I'd like to explain why I am not satisfied with them.
What are those Denormal Numbers?
If you find IEEE floating point numbers baffling, you need to read the history of floating point numbers before IEEE 754 standard - you'll learn that they were much more magical. You couldn't really write portable code with them: on some architectures, multiplying a number by 1.0 produced a (slightly) different number, on other architectures subtracting two different numbers could result in 0, yet another one required that you multiply a number by 1.0 before comparing it to 0... You can find some more examples here (PDF).
One particular issue with floating point numbers is that they have a large "gap" between 0 and the first non-zero number - to understand the gap, we need to go back to how floating point number is constructed.
Let's say that you have 3 decimal digits for significand (SSS) and one decimal digit for exponent (E), both signed. Your number is constructed like that: 1.SSS * 10^E, where 1 is always prepended to (non-zero) numbers in order to make number of decimal places constant across the range (this works better for binary, where 1 is the maximum digit). Anyway, with this notation you can represent numbers from 1.999 * 10^9 (furthest from zero) to 1.000 * 10^(-9) (closest to zero).
Now, note that the distance between the smallest non-zero number and the next one (that is, 1.001*10^(-9) ) is equal to 0.001 * 10^(-9) == 10^(-12) and is much smaller than the distance between 1.000*10^(-9) and zero.
i.e. on a horizontal axis we have:
0 ---------- <gap> ----------- 1.000*10^(-9) -- 1.001*10^(-9) -- 1.002*10^(-9) -- ....
The problem with that gap is as follows: if you subtract 1.000*10^(-9) from 1.001*10^(-9), you cannot represent the difference in the above notation (1.SSS*10^E) - you'd need a two-digit exponent (-12) for that. You have to either "flush it to zero" or extend the notation.
Solutions
Flushing to zero means that you can get zero when subtracting two non-equal numbers, like, say, 1.005*10^(-9) and 1.000*10^(-9). That can be a problem e.g. if you use floating point numbers to measure time and your program runs too fast: time deltas between frames will become zeroes in "flush to zero" mode and this can result in either division by zero or unexpected arrested motion.
Denormal numbers are a special case: we reserve a certain value of exponent for them and prepend not 1, but 0 instead: i.e. they have the form of 0.SSS * 10^(-9) (note that the exponent is fixed at the lowest possible value). That means that these numbers lose decimal places (i.e. precision) as they approach zero, so in fact the lunch isn't free, we still have to pay for it (i.e. returning to previous example, we need to account for the fact that time deltas will become less precise once the program runs faster), but at least we have something non-zero to multiply by.
However, the lunch is even more expensive - denormal numbers inflict a performance hit.
How large?
I ran the code from StackOverflow on a number of processors, all at least a few years old: 3.0 Ghz Xeon X5450 (2007), 2.2 Ghz Athlon 64 X2 (2006?), Atom N260 (2009), Cell (2006), PowerPC 970FX (2003), Intel Pentium 4 (2002), Cortex A8 (from Beagleboard xM) - 2009.
I have to underscore that I haven't changed the code at all - that is, it remained scalar. This is suboptimal for the most of the above CPUs, especially Cortex-A8 where VFP sucks better than Electrolux, so this 'benchmark' is not indicative of optimized code. Still, I don't think that the performance of scalar code shouldn't matter.
The result is like this:
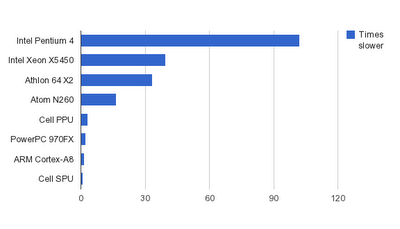
The hardest hit was taken by Pentium 4 - this is the architecture where I actually first encountered the problem. It is about 103 times slower on denormal numbers, but that's nothing new. However, it is not pleasing that years later Intel is still struggling with making denormals performant - Xeon is the second most affected processor, being almost 40 times slower on denormals, and according to StackOverflow thread, Core i7 is even worse in that regard.
x86/x64 CPUs top the charts, while RISCs seem to be affected very slightly. Note that SPU always operates in "flush to zero" mode and is unaffected at all - or is always affected, depending whether you need performance or numerical stability. It is included here for completeness and also to provide some scale.
Looks like a triumph of RISC architectures, heh? Well, not if we take absolute times in consideration:
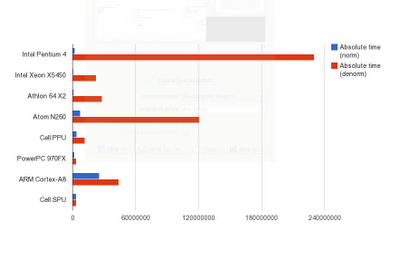
The histogram is a bit hard to read, but the numbers are:
| CPU | Norm | Denorm |
|---|
| Xeon 5450 | 0.57 sec | 22.6 sec |
| Athlon64 | 0.83 sec | 27.8 sec |
| PowerPC 970FX (G5) | 1.5 sec | 3.5 sec |
| Pentium 4 | 2.25 sec | 230 sec (!!) |
| Cell SPU | 3.28 sec | (not applicable) |
| Cell PPU | 3.7 sec | 11.67 sec |
| Atom N260 | 7.35 sec | 120 sec (!) |
| Cortex A8 (VFP!) | 25.5 sec | 44 sec |
So x86/x64 family executes normalized floats the fastest, but also takes the largest hit on denormalized ones. This is actually less satisfactory than more predictable behavior of PPC/ARM because it results in people "resolving" the issue by using "flush to zero" mode all the time and not caring about occasional abnormal behavior. Which defeats the original goals of IEEE and keeps floating point arithmetics tricky.

