CodeProjectIntroduction
DataStage sparse lookup is considered an expensive operation because of a round-trip database query for each incoming row. It is appropriate if the following 2 conditions are met.
- The size of reference table is huge, i.e., more than millions of rows. If the reference table is small enough to fit into memory entirely, normal lookup is a better choice.
- The number of input rows is less than 1% of the reference table. Otherwise, use a Join stage.
Is it possible to speedup sparse lookup by sending queries to database in batches of 10, 20 or 50 rows? In other words, instead of sending the following SQL to database for each incoming row,
SELECT some_columns FROM my_table WHERE my_table.id_col = orchestrate.row_value
can we send one query for multiple rows like this?
SELECT some_columns FROM my_table WHERE my_table.id_col in (orchestrate.row_value_list)
Solution
In order to make the 2nd query work, we need 2 tricks. First, we need to concatenate values from multiple rows into a single string, separated by a delimiter (e.g. comma). I am not sure how to do this in DataStage v8.1 or earlier. Not impossible, but rather complicated. Since v8.5, the Transformer stage has loop capability, which makes the task of concatenating multiple rows much easier.
The 2nd trick is to, at database side, split the value list from a comma-delimited string into an array. If we simply plug the original string into the 2nd query, the database will interpret it literally as a single value. If only there is a standard SQL function equivalent to string.split() in C# or Java. Different databases use their own tricks to achieve string.split(). I will use Oracle in my example implementation.
Implementation
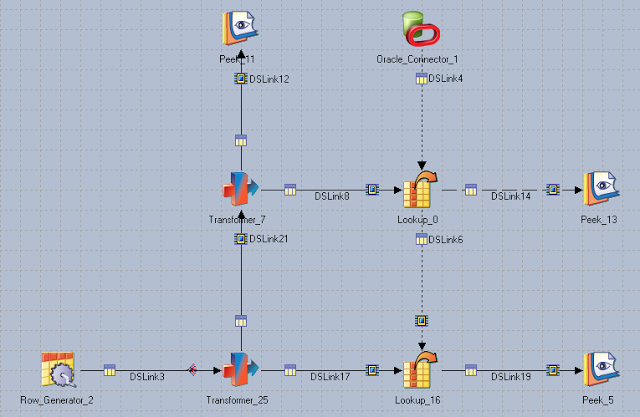
Job Overview
The example implementation generates 50k rows using a Row Generator stage. Each row has a key column and a value column. The rows are duplicated in Transformer_25. One copy is branched to Transformer_7, where multiple rows of the keys are concatenated. The number of rows in each concatenation is set by a job parameter, #BATCH_SIZE#. The concatenated keys are then sent to Lookup_0 for sparse lookup against an Oracle table with 5m rows. The lookup results are merged back to the original stream in Lookup_16.
Concatenate Multiple Rows in a Transformer Loop
Define the following stage variables and loop condition to concatenate multiple rows.
| Variable | Data Type | Derivation |
BatchCount | Integer | IF IsLast THEN 1 ELSE BatchCount + 1 |
IsLast | Bit | LastRow() or BatchCount = BATCH_SIZE |
FinalList | String(4000) | IF IsLast THEN TempList : DecimalToString(DSLink21.NUM_KEY,"suppress_zero") ELSE "" |
TempList | String(4000) | IF IsLast THEN "" ELSE TempList : DecimalToString(DSLink21.NUM_KEY, "suppress_zero") : "," |
Loop condition: @ITERATION = 1 and IsLast

Batch Sparse Lookup
The concatenated keys need to be split in the Oracle connector. Splitting a comma-delimited string in Oracle can be done using reqexp_substr() function and recursive query. For example,
SELECT regexp_substr('A,B,C', '[^,]+', 1, level) from dual connect by level <= regexp_count('A,B,C', ',') + 1
This is how to setup the query in the Oracle connector stage.
Test run
A test run with BATCH_SIZE of 50 is shown below. DSLink4 indicated that 1,000 queries, instead of 50,000, were sent to the database.
Performance Evaluation
Another job (shown below) using regular sparse lookup compares the performance of batch sparse lookup.
The result of the comparison is summarized in the chart below. Batch sparse lookup can cut down job running time by ~75%. The most effective batch size is between 20 to 50.

