Short summary: I created a microbenchmark originally intended to compare efficiency of virtual calls on different processor architectures, which yielded some unexpected by me, yet reproducible, results. The link to the source code is at the very bottom.
The Benchmark
One day, I wanted to measure how much one can gain by replacing an object-oriented hierarchy (with virtual methods) with a collection of "components", where each component is responsible for a particular piece of object.
For the object-oriented part, I created 8 classes (O1-O8) derived from each other, with a virtual Update() method. Parent's Update() method is also called, so O8::Update() calls O7::Update() and so on. Care has been taken to prevent these calls from being inlined - I moved their implementations to separate compilation units, so they are not inlined unless globally optimizing compiler is used.
For the data-oriented part, unrelated 8 structs (O1Comp-O8Comp) have been created, with a non-virtual Update() method. This method is also prevented from being inlined by moving its implementation to separate unit.
To make this benchmark less memory performance oriented, Update() methods of object-oriented and data-oriented classes do some work. The work done by OO and DOD code is the same, because it actually gets done in inlined functions of separate Payload classes. Amount of work increases non-linearly, so O8Comp class does 128 times more work than O1Comp one (this seemed more natural for me).
The objects are managed the following way:
- For OO part, each object is created separately on the heap (i.e., by calling
new). Array of pointers to base object is then traversed and Update() (a virtual method) is called on each one. - For DOD part, separate linear arrays for each component are created (number of elements is adjusted to take into account that
O2 class has O2Comp and O1Comp and O8 has all 8 components). Arrays are processed one by one, with non-virtual Update() function called on each element of it.
Only loops which update the objects are measured, creation/deletion time is not.
Benchmark has some configurable options, like counting calls to ensure the same work is done, prefetching the virtual table, unrolling the loops, and - most importantly as it turns out - varying the workload.
The Results
With zero workload, gains are spectacular, with DOD code being about 3 times as fast as OO one. However, once I began increasing the amount of work done by Update(), the gains became smaller - and for some cases, OO code is actually faster! I cannot explain that - I profiled one of such pathological cases, and it is probably related to the fact that processor may prefer longer (although separated with unconditional calls) code path when calling O8::Update() than doing the same work in separate 8 loops for each of O1Comp...O8Comp
The general rule seems to be - the more work is done in an Update() method, the less you gain from OO to DOD conversion (at least when using gcc). To be more exact, gains seem to become smaller (or even become negative) if:
- the virtual table is prefetched before making a call in OO code, and
- the 'payload' loops are unrolled
I ran this on several processors I own, including PowerPC 970 (G5), Cell BE (PS3), Athlon 64, Pentium IV, Atom and Cortex-A8 (Nokia N900), in 8 configurations: light workload, light workload with unrolled loops, light workload with prefetch, light workload with prefetch and unrolled loops and the same 4 configurations for heavy workload. Actual tables of data are too boring to show, so here are the summarized graphs.
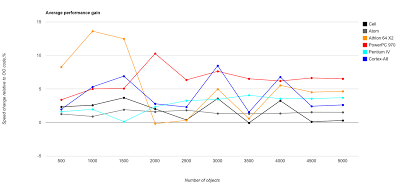
This one shows gains of going data-oriented way averaged among all those 8 configurations. As you can see, on average, you are still better off if you decide to drop object-orientedness:
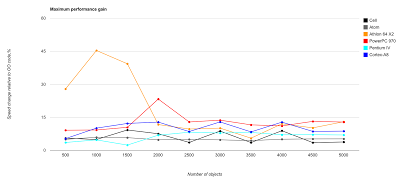
This is the maximum amount of speed up (in percents) this benchmark gained when doing things data-oriented way:
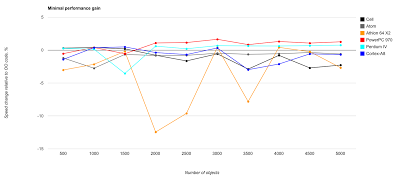
This is the minimum amount of speed up (actually, often a slowdown) when doing things data-oriented way:
How to Test It Yourself
The resulting microbenchmark can be found in this github.com repository. For Unix machines (including Mac OS X), just do this:
git clone git://github.com/RCL/dodbench.git
cd dodbench
make benchmark
(use gmake if on FreeBSD)

